1、分割字符串
切片索引从0开始
number = "d4e8e1f4a0f7e1f3a0e6e1f3f4a1a0d4e8e5a0e6ece1e7a0e9f3baa0c4c4c3d4c6fbb9b2b2e1e2b9b9b7b4e1b4b7e3e4b3b2b2e3e6b4b3e2b5b0b6b1b0e6e1e5e1b5fd"
result_list= []
number = "d4e8e1f4a0f7e1f3a0e6e1f3f4a1a0d4e8e5a0e6ece1e7a0e9f3baa0c4c4c3d4c6fbb9b2b2e1e2b9b9b7b4e1b4b7e3e4b3b2b2e3e6b4b3e2b5b0b6b1b0e6e1e5e1b5fd"
for i in range(0,len(number),2):number_good = number[i:i+2]result_list.append(number_good)
print(result_list)
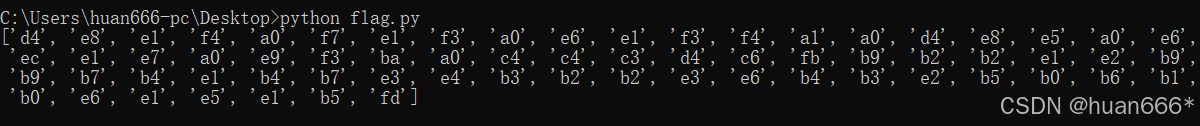
2、读取pcap数据包文件
import pyshark
import binascii# 打开PCAP文件并设置过滤器
packets = pyshark.FileCapture('out.pcap', display_filter="icmp.type==0")# 处理每个数据包
for each in packets:try:# 解码ICMP数据负载data = binascii.unhexlify(each.icmp.data).decode()if data.startswith('$$START$$'):data = data[len('$$START$$'):]print(data)except Exception as e:print(f"Error processing packet: {e}")
3、统计文本中字符出现的次数,从高到低排序
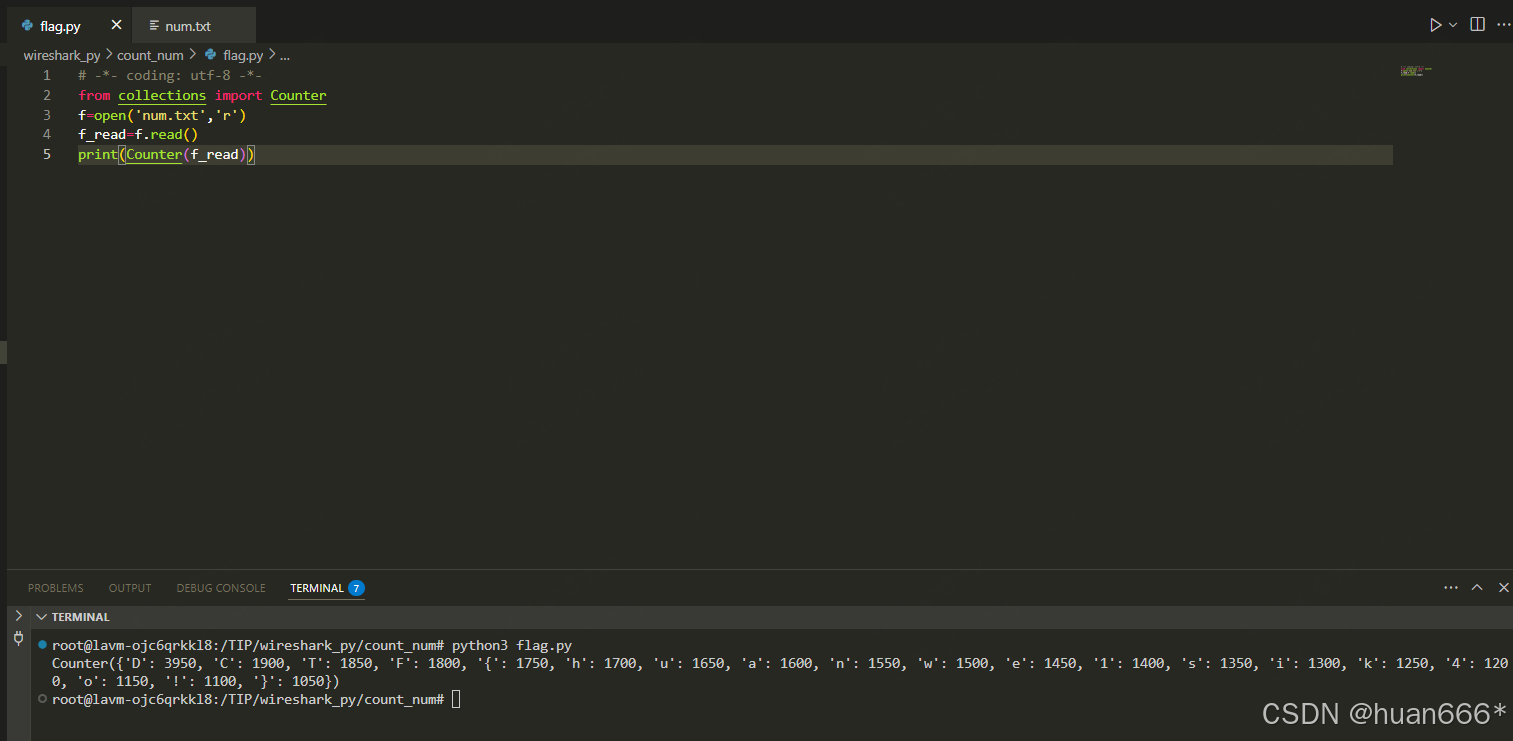
# -*- coding: utf-8 -*-
from collections import Counter
f=open('num.txt','r')
f_read=f.read()
print(Counter(f_read))


![[C++] STL数据结构小结](http://pic.xiahunao.cn/nshx/[C++] STL数据结构小结)



