9.总结
1.数据并行
数据并行,由于其原理相对比较简单,是目前使用最广泛的分布式并行技术。数据并行不仅仅指对训练的数据并行操作,还可以对网络模型梯度、权重参数、优化器状态等数据进行并行。
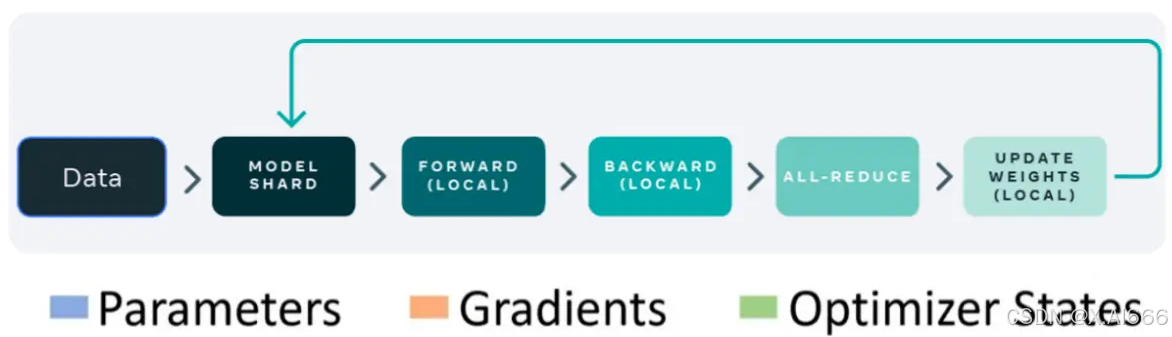
我们首先以PyTorch 数据并行的发展(DataParallel、DistributedDataParallel、FullyShardedDataParallel)为主线进行讲述了数据并行的技术原理。同时,也简述了 DeepSpeed 中的增强版数据并行ZeRO。
2.流水线并行
所谓流水线并行,就是由于模型太大,无法将整个模型放置到单张GPU卡中;因此,将模型的不同层放置到不同的计算设备,降低单个计算设备的显存消耗,从而实现超大规模模型训练,也被称为层间模型并行。
我们首先讲述了朴素流水线并行,但是,朴素流水线并行存在的Bubble太大,导致GPU的利用率很低。为了减少Bubble率,后面又讲述了微批次流水线并行方案GPipe,虽然,GPipe可以显著提高GPU的利用率,但是GPipe采用的是F-then-B 模式(先进行前向计算,再进行反向计算),由于缓存了多个 micro-batch 的中间变量和梯度,因此,显存的实际利用率并不高。后来,我们又讲述了采用1F1B模式(前向计算和反向计算交叉进行,可以及时释放不必要的中间变量)的PipeDream及其变体(PipeDream-2BW、PipeDream-Flush等)来进一步节省显存,训练更大的模型。同时,还提到了常见的AI训练框架中采用的流水线并行方案。
3.张量并行
将计算图中的层内的参数(张量)切分到不同设备(即层内并行),每个设备只拥有模型的一部分,以减少内存负荷,我们称之为张量模型并行。按照行或者列的切分方式,可将张量并行切分为对应的行并行或者列并行。我们首先介绍了由Megatron-LM提出的仅对权重进行划分的1D张量并行。为了应对超大规模的AI模型,后来又介绍了由 Colossal-AI 提出的多维(2/2.5/3 维)张量并行。2D张量并行提出


全生态接入系统技术白皮书)



