新学期开始了,下面我将记录大数据学习过程中的各种实验,并写成博客
Hadoop是一种分布式存储大数据框架,是大数据学习最基本也是最重要的模型。下面我们介绍Hadoop集群的搭建。版本:Hadoop3.3.6,环境:Ubuntu24.04.1 LTS三台虚拟机。
Hadoop 安装
在安装Hadoop时候,非常重要的一点就是三台虚拟机所登录的账户必须为同一个名称的,一般来说,我们会选择新建Hadoop用户。但是,新建的用户由于权限问题可能部分文件无法访问,所以,这里我没有按照老师的做法,而是选择全部使用root用户进行ssh配置。
root 用户配置
Ubuntu默认没有配置root的密码,首先需要进行配置root。
sudo passwd root
配置至少8位数数字的密码

切换到root用户
su root
更新软件包
sudo apt-get update
安装SSH、配置SSH免密登录
(1)安装SSH
sudo apt-get install openssh-server
(2)配置SSH免密登录
ssh localhost
exit
cd ~/.ssh/
ssh-keygen -t rsa #一直按回车
cat ./id_rsa.pub >> ./authorized_keys
备注:
①输入ssh-keygen -t rsa,是在生成公钥和私钥,执行需要一按回车(按三次);②cat ./id_rsa.pub >> ./authorized_keys ,是为了把将每台机器的id_rsa.pub存入每台机器的authorized_keys中
这一部分参考
https://mp.weixin.qq.com/s?__biz=MzU1NjM4ODg3NQ==&mid=2247562740&idx=3&sn=ac85efafeb177ade3717521ef1916848&chksm=fbc67290ccb1fb86c67feb95085b5578c0129a7eb5aa9099659c246d04a06bda840ddf98a6a7&scene=27
(3)验证免密。
ssh localhost
exit
至于为什么要设置免密登录,是因为:当我们每次启动集群时,都需要对每个节点输入一次密码,放到实际场景中,如果多台机器一起跑,如果没有配置免密,那么启停集群时要手动输入很多密码,这是致命的。这个给时候我们就需要对Hadoop集群进行SSH免密登录配置。
我们之后还会将Hadoop101的配置文件通过集群分发脚本分发到子结点上,如果没有免密登录,脚本就无法运行,操作起来就很麻烦。
Java环境配置
Java版本我使用的是openjdk8,具体版本不限,选择其中一个就行
sudo apt install openjdk-8-jdk
随后,配置环境变量文件
先安装vim
apt install vim
vim ~/.bashrc
在文末添加
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 #目录要换成自己jdk所在目录
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH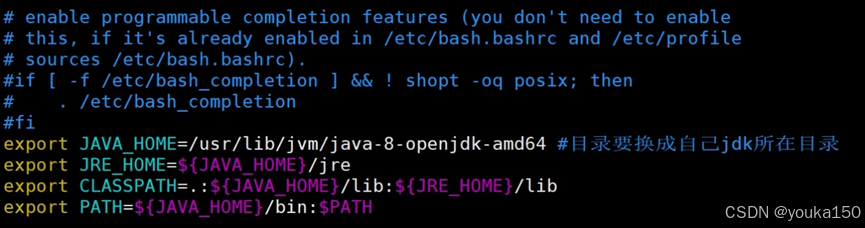
输入命令使得环境变量生效
source ~/.bashrc
验证
java -version

克隆虚拟机
右键虚拟机,点击管理,选择克隆
一定要选择完整克隆
将这三台虚拟机进行重命名,分别叫做hadoop101 hadoop102 hadoop103(这里没有用master node1 node2的形式)。这样主要是为了后续集群分发脚本(xsync)编写的方便性。
修改主机名称
克隆完成后,分别修改三台主机的名称叫做hadoop101 hadoop102 hadoop103
sudo vim /etc/hostname
重启一下,就生效
xsync集群分发脚本(非常方便,强烈推荐)
xsync是基于rsync用于集群内文件传输的自编脚本,主要用处就是将master结点上的文件/路径传输到同一路径下的node结点上,对于配置文件,hadoop集群搭建都非常有用、高效。脚本参考版本如下(注意,每个人的脚本会略有不同,特别是主机名):
首先,在/usr/local/bin目录下创建xsync
vim /usr/local/bin
将以下内容复制进去:
#!/bin/bash
if [[ $# -lt 1 ]] ;thenecho no params;exit;
fi
p=$1
dir=`dirname $p`
filename=`basename $p`
cd $dir
fullpath=`pwd -P .`
user=`whoami`echo user = $user
echo fullpath = $fullpath
echo filename = $filename
echo dir = $dir
echo p = $p
for((i=1;i<=3;i=$i+1));doecho ==========Hadoop10$i==========rsync -lr $p ${user}@hadoop10$i:$fullpath
done;
随后,让脚本生效
chmod +x /usr/local/bin/xsync
配置集群ip映射
Hadoop是分布式集群,那怎么搭建集群呢,主要靠的是各台虚拟机的ip地址。在创建过程中,系统已经自动分配了一个ip地址。大部分人由于为了体现集群,会把ip地址进行修改,生成三个连续的序列。不过实际上可以不用修改也可以搭建集群。我没有修改
首先,查看各个虚拟机的ip地址,安装net-tools
apt install net-tools
ifconfig
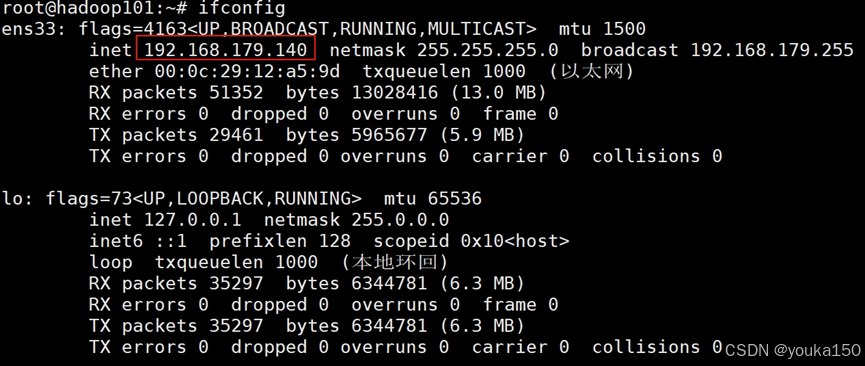
三台虚拟机的inet对应的分别的ip地址
接着,也就是最重要的一步,修改hosts文件,3台虚拟机中都需要在 hosts 文件中加入对方的ip地址,形成集群
sudo vim /etc/hosts
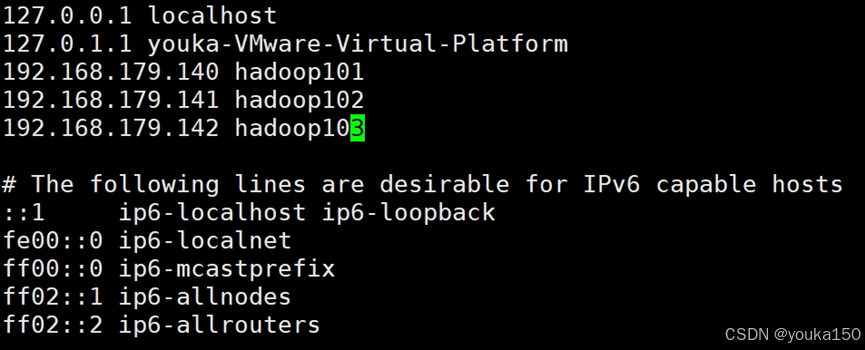
如上图所示,这回,我们就可以用xsync命令将hosts文件分发给集群的其他结点:
xsync /etc/hosts
SSH免密登录其他节点(在hadoop101上执行)
在master上执行
cd ~/.ssh
rm ./id_rsa* # 删除之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回车就可以
cat ./id_rsa.pub >> ./authorized_keys
scp ~/.ssh/id_rsa.pub root@hadoop101:/home/hadoop/
scp ~/.ssh/id_rsa.pub root@hadoop103:/home/hadoop/
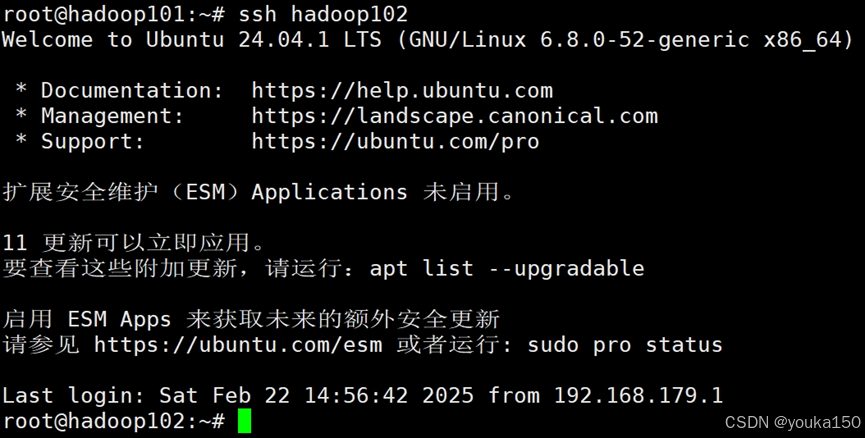
验证一下:
ssh hadoop102
安装hadoop3.3.6(在hadoop101中执行)
(1)下载hadoop
下载网址:Index of /hadoop/common
我选择的是3.3.6版本,可以根据你的需求进行选择
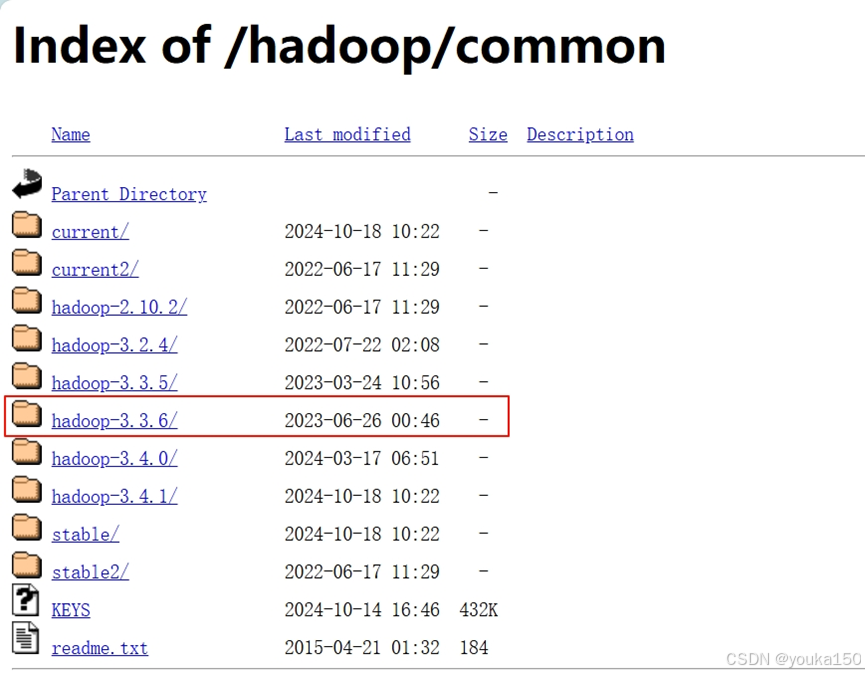
选择hadoop-3.3.6.tar.gz 下载
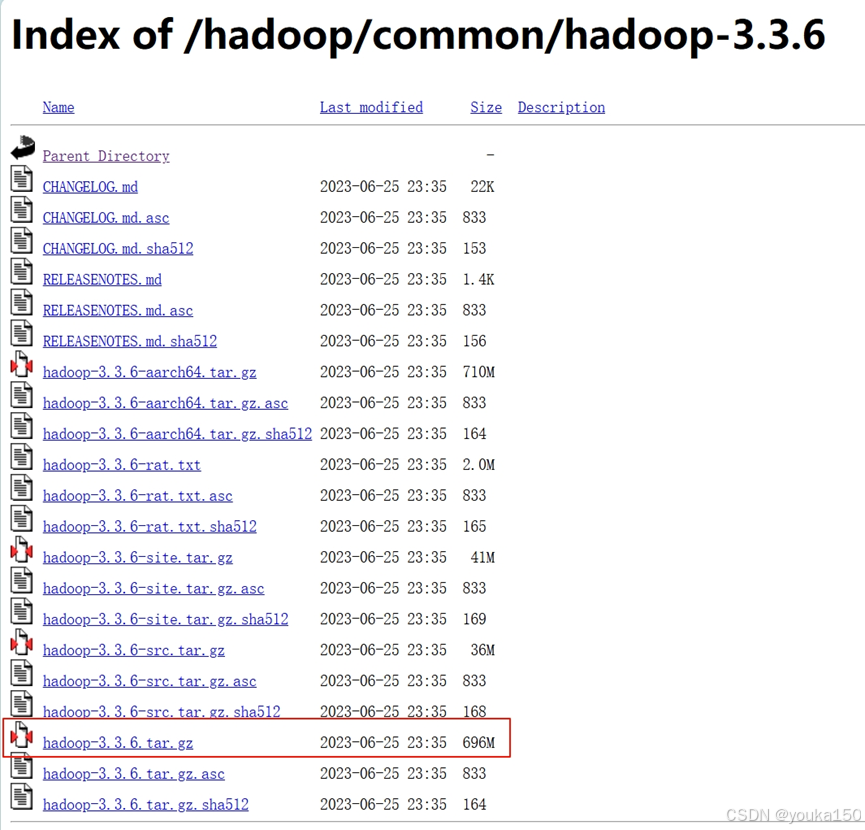
(2)把hadoop上传到hadoop101上
我们使用Xftp工具进行上传
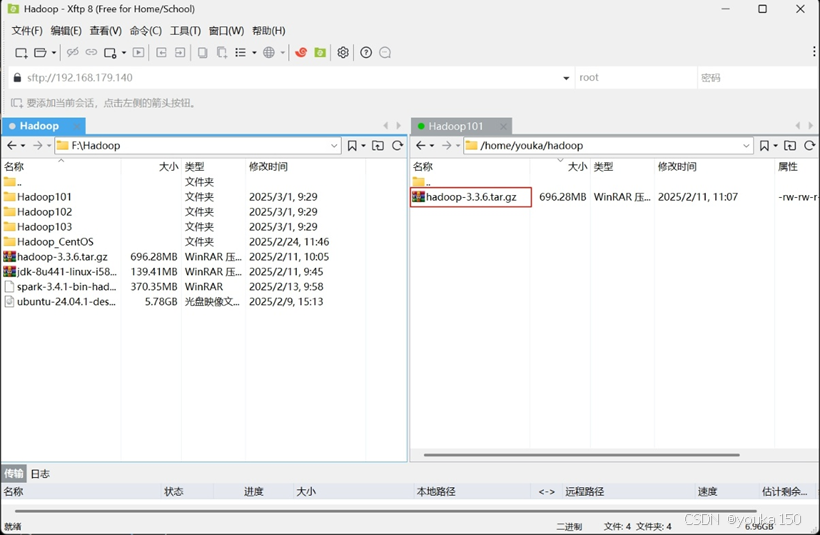
上传完成后,进行解压,解压到/usr/local路径下
执行以下代码:
sudo tar -zxf hadoop-3.3.6.tar.gz -C /usr/local #解压
cd /usr/local/
sudo chown -R hadoop ./ hadoop-3.3.6 # 修改文件权限
验证
cd /usr/local/hadoop-3.3.6
./bin/hadoop version

配置hadoop环境(这一步需要很仔细)
配置环境变量
vim ~/.bashrc
在文末添加如下内容:
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export HADOOP_H0ME=/usr/local/hadoop-3.3.6
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
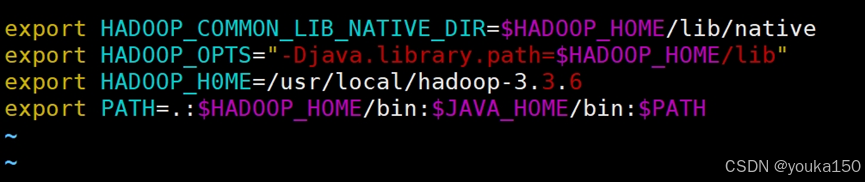
使得配置生效
source ~/.bashrc
创建文件目录(为后面的xml做准备)
cd /usr/local/hadoop
mkdir dfs
cd dfs
mkdir name data tmp
cd /usr/local/hadoop
mkdir tmp
配置hadoop的java环境变量
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
vim $HADOOP_HOME/etc/hadoop/yarn-env.sh
两个的首行都写入
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64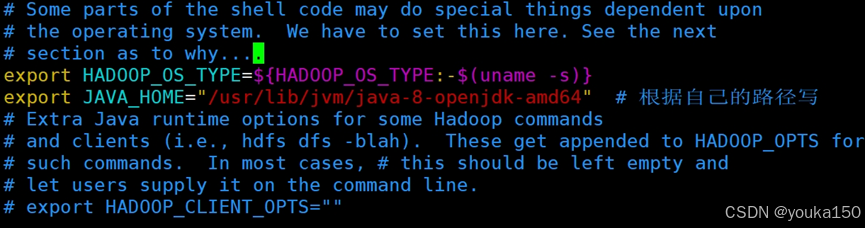
配置nodes
cd /usr/local/hadoop/etc/hadoop
删除掉原有的localhost,把集群的名字写入
vim workers
hadoop101
hadoop102
hadoop103
配置 core-site.xml
vim core-site.xml
添加内容:
<configuration>
<property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop-3.3.6/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://hadoop101:8020</value>
</property>
</configuration>
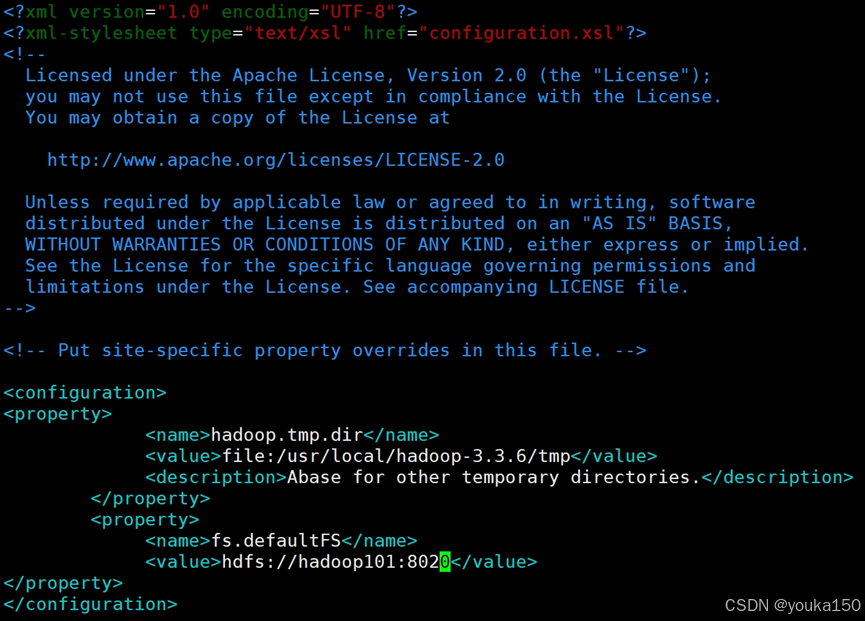
配置 hdfs-site.xml
vim hdfs-site.xml
添加内容
<configuration><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop-3.3.6/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop-3.3.6/tmp/dfs/data</value></property><property><name>dfs.namenode.http-address</name><value>hadoop101:9870</value></property><property><name>dfs.namenode.secondary.http-address</name><value>hadoop102:50090</value></property>
</configuration>
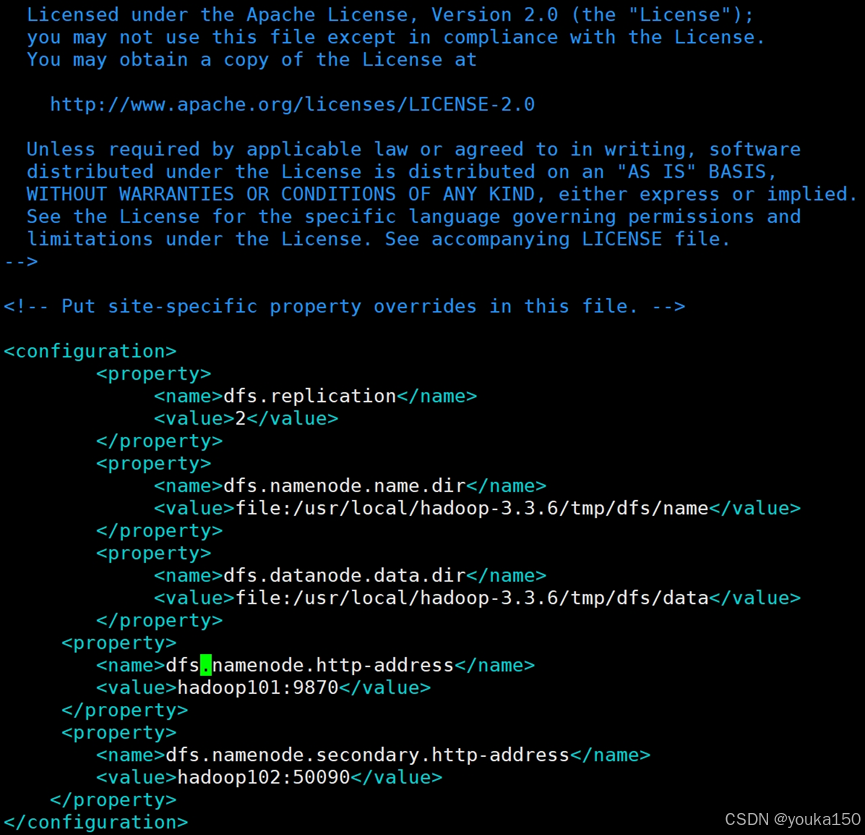
配置mapred-site.xml
vim mapred-site.xml
添加内容
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
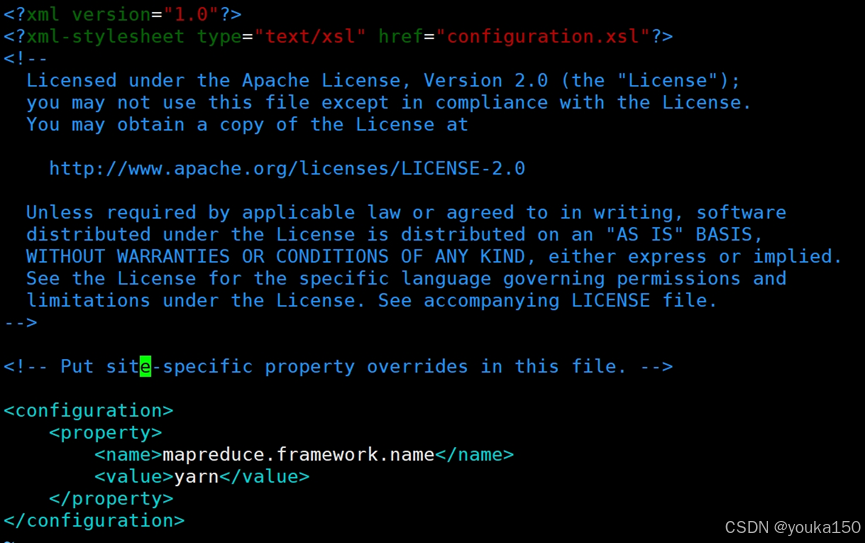
至此,hadoop101结点配置完成,我们需要将配置分发给其他结点,这里我们依旧使用xsync命令
cd /usr/local
xsync hadoop-3.3.6
这一步需要等待1min左右
启动hadoop
首次启动需要先在 hadoop101 节点执行 NameNode 的格式化
hdfs namenode -format
正式启动
start-all.sh
mr-jobhistory-daemon.sh start historyserver

在浏览器中输入ip地址:9870,出现如下界面
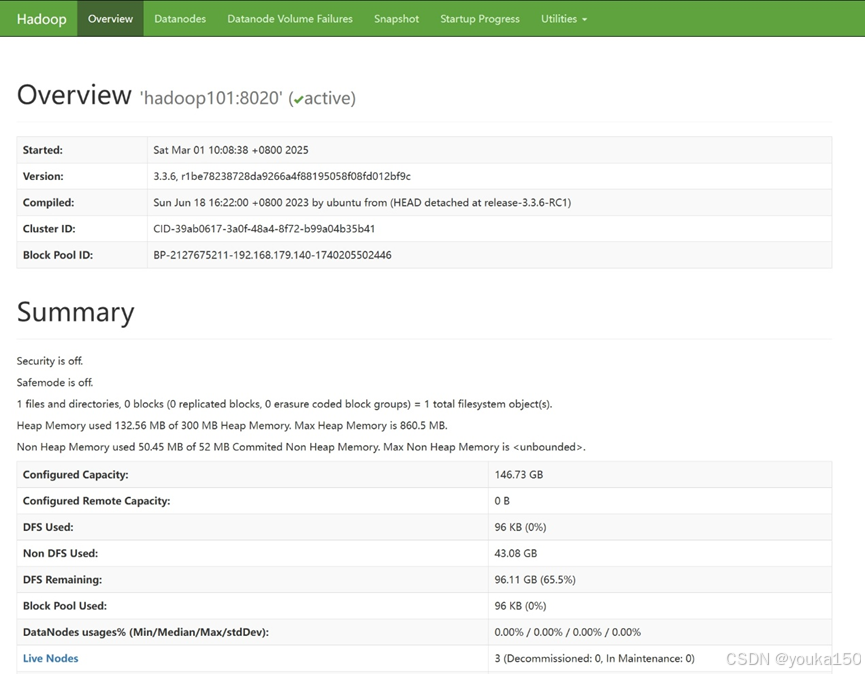
集群配置成功
利用jps检查启动的结点
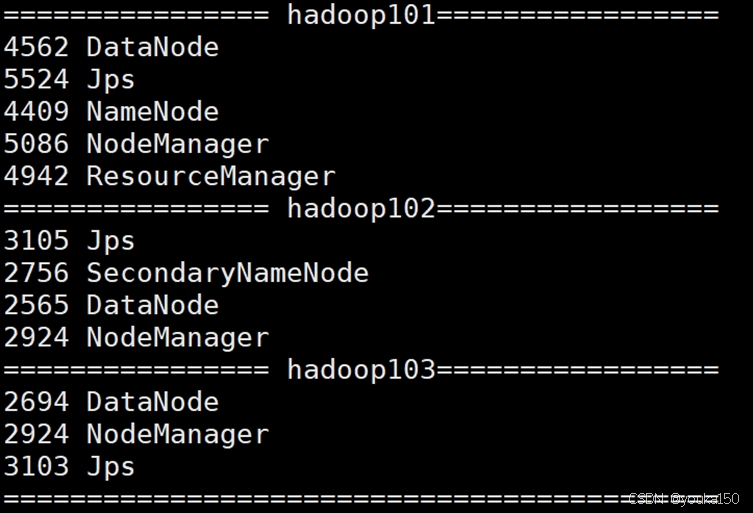
关闭集群
stop-all.sh
mr-jobhistory-daemon.sh stop historyserver


全生态接入系统技术白皮书)



