目录
前言
一、理论知识
二、准备工作
2.1 引入库
2.2 数据可视化
三、构建模型
3.1 构建生成器
3.2 构建鉴别器
四、训练函数
4.1 定义损失函数
4.2 定义优化器
4.3 训练模型
五、模型分析
5.1 加载模型
总结
前言
🍨 本文为中的学习记录博客[🔗365天深度学习训练营]🍖 原作者:[K同学啊]
说在前面
本周任务:基础任务——了解条件生成对抗网络(CGAN)的基本原理以及CGAN是如何实现条件控制的,学习CGAN代码并跑通代码;进阶任务——生成指定手势的图像
我的环境:Python3.6、Pycharm2020、TensorFlow2.4.0
一、理论知识
条件生成对抗网络(CGAN)是在生成对抗网络(GAN)的基础上进行了一些改进。对于原始GAN的生成器而言,其生成的图像数据是随机不可预测的,因此我们无法控制网络的输出,在实际操作中的可控性不强。
针对上述原始GAN无法生成具有特定属性的图像数据的问题,Mehdi Mirza等人在2014年提出了条件生成对抗网络,通过给原始生成对抗网络中的生成器G和判别器D增加额外的条件,例如我们需要生成器G生成一张没有阴影的图像,此时判别器D就需要判断生成器所生成的图像是否是一样没有的图像。条件生成对抗网络的本质是将额外添加的信息融入到生成器和判别器中,其中添加的信息可以是图像的类别、人脸表情和其他辅助信息等,旨在把无监督学习的GAN转化为有监督学习的CGAN,便于网络能够在我们的掌控下更好地进行训练。CGAN网络结构如下图所示:
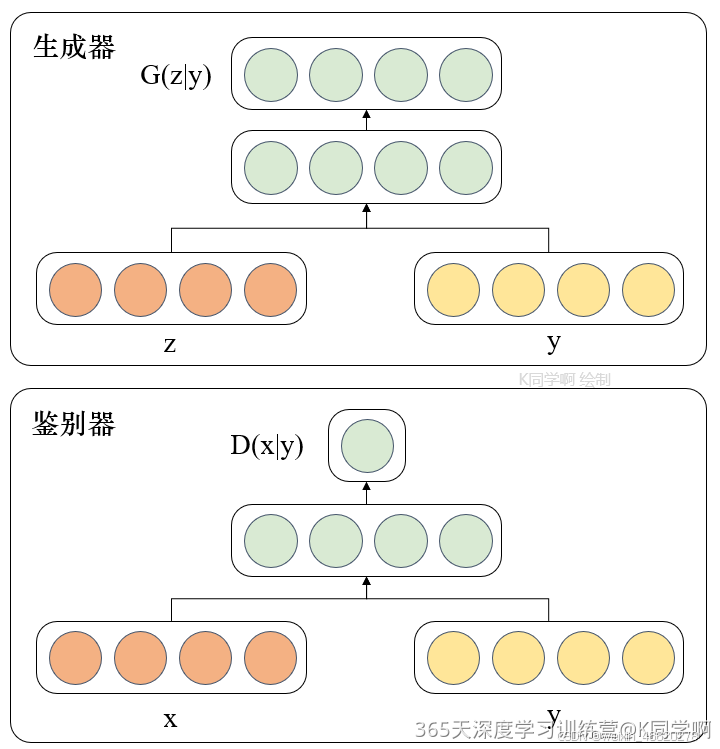
由上图的网络结构可知,条件信息y作为额外的输入被引入对抗网络中,与生成器中的噪声z合并作为隐含层表达;而在判别器D中,条件信息y则与原始数据x合并作为判别函数的输入。这种改进在以后的诸多方面研究中被证明是非常有效的,也为后续的相关工作提供了积极的指导作用。
二、准备工作
2.1 引入库和数据导入
代码如下:
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from torchvision.utils import save_image
from torchvision.utils import make_grid
from torch.utils.tensorboard import SummaryWriter
from torchsummary import summary
from torchinfo import summary
import matplotlib.pyplot as pltdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
batch_size = 128# 1.1 导入数据
train_transform = transforms.Compose([transforms.Resize(128),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
train_dataset = datasets.ImageFolder(root='./data/rps/', transform=train_transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)2.2 数据可视化
关于ax.imshow(make_grid(images.detach(),nrow=22).permute(1,2,0))详解:
- ax:这是一个matplotlib的轴对象(axis),用于在图形上放置图像。通常它用于创建子图。
- make_grid(images.detach(), nrow=10):这是一个函数调用。make_grid函数的作用是将一组图像拼接成一个网格。它接受两个参数:images和nrow,images是一个包含图像的张量,nrow是可选参数,表示每行显示的图像数量。在这里,它将图像进行拼接,并设置每行显示10个图像;
- permute(1,2,0):这是一个张量的操作,用于交换维度的顺序。在这里,对于一个3维的张量(假设图像维度为(C,H,W), 其中C是通道数,H是高度,W是宽度),permute(1,2,0)将把通道(C)移动到最后,而将高度和宽度维度(H,W)放在前面。这样做是为了符合matplotlib对图像的要求,因为matplotlib要求图像的维度为(H,W,C)。
- imshow(...):这是matplotlib的一个函数,用于显示图像。在这里,它接受一个拼接好并且维度已经调整好的图像张量,并将其显示在之前创建的轴对象(ax)。
代码如下:
# 1.2 数据可视化
def show_images(images):"""把图像组合成一个网络,并展示"""plt.figure(figsize=(20, 20))plt.axis('off')plt.imshow(make_grid(images.detach(), nrow=22).permute(1, 2, 0))def show_batch(dl):"""在数据库中取一个批次的数据进行展示"""for images, _ in dl:show_images(images)breakshow_batch(train_loader)image_shape = (3, 128, 128)
image_dim = int(np.prod(image_shape))
latent_dim = 100n_classes = 3
embedding_dim = 100打印输出:

三、构建模型
函数weights_init(m),其中m表示神经网络中的一层。函数的作用是对神经网络的权重进行初始化,通过函数判别类名:
- Conv:使用正态分布初始化权重数据,均值为0,标准差为0.02
- BatchNorm:使用正态分布初始化权重数据,均值为1,标准差为0.02,同时使用常数初始化偏置项数据,值为0
通过将每一层的权重初始化为符合正态分布的数据,提高网络的泛化能力和训练效果
3.1 构建生成器
代码如下:
# 二、构建模型
# 自定义权重初始化函数,用于初始化生成器和判别器的权重
def weights_init(m):# 获取当前层的类名classname = m.__class__.__name__# 如果当前层是卷积层(类名中包含'Conv')if classname.find('Conv') != -1:# 使用正态分布随机初始化权重,均值为0,标准差为0.02torch.nn.init.normal_(m.weight, 0.0, 0.02)# 如果当前层是批归一化层(类名中包含‘BatchNorm’)elif classname.find('BatchNorm') != -1:# 使用正态分布随机初始化权重,均值为0,标准差为0.02torch.nn.init.normal_(m.weight, 1.0, 0.02)# 将偏执项初始化为全零torch.nn.init.zeros_(m.bias)# 2.1 构建生成器
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()# 定义条件标签的生成器部分,用于将标签映射到嵌入空间中# n_classes:条件标签的总数# embedding_dim:嵌入空间的维度self.label_conditioned_generator = nn.Sequential(nn.Embedding(n_classes, embedding_dim),nn.Linear(embedding_dim, 16))# 定义潜在向量的生成器部分,用于将噪声向量映射到图像空间中# latent_dim: 潜在向量的维度self.latent = nn.Sequential(nn.Linear(latent_dim, 4*4*512),nn.LeakyReLU(0.2, inplace=True))# 定义生成器的主要结构,将条件标签和潜在向量合并成生成的图像self.model = nn.Sequential(# 反卷积层1:将合并后的向量映射为64x8x8的特征图nn.ConvTranspose2d(513, 64 * 8, 4, 2, 1, bias=False),nn.BatchNorm2d(64 * 8, momentum=0.1, eps=0.8), # 批标准化nn.ReLU(True), # ReLU激活函数# 反卷积层2:将64x8x8的特征图映射为64x4x4的特征图nn.ConvTranspose2d(64 * 8, 64 * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(64 * 4, momentum=0.1, eps=0.8),nn.ReLU(True),# 反卷积层3:将64x4x4的特征图映射为64x2x2的特征图nn.ConvTranspose2d(64 * 4, 64 * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(64 * 2, momentum=0.1, eps=0.8),nn.ReLU(True),# 反卷积层4:将64x2x2的特征图映射为64x1x1的特征图nn.ConvTranspose2d(64 * 2, 64 * 1, 4, 2, 1, bias=False),nn.BatchNorm2d(64 * 1, momentum=0.1, eps=0.8),nn.ReLU(True),# 反卷积层5:将64x1x1的特征图映射为3x64x64的RGB图像nn.ConvTranspose2d(64 * 1, 3, 4, 2, 1, bias=False),nn.Tanh() # 使用Tanh激活函数将生成的图像像素值映射到[-1, 1]范围内)def forward(self, inputs):noise_vector, label = inputs# 通过条件标签生成器将标签映射为嵌入向量label_output = self.label_conditioned_generator(label)# 将嵌入向量的形状变为(batch_size, 1, 4, 4),以便与潜在向量进行合并label_output = label_output.view(-1, 1, 4, 4)# 通过潜在向量生成器将噪声向量映射为潜在向量latent_output = self.latent(noise_vector)# 将潜在向量的形状变为(batch_size, 512, 4, 4),以便与条件标签进行合并latent_output = latent_output.view(-1, 512, 4, 4)# 将条件标签和潜在向量在通道维度上进行合并,得到合并后的特征图concat = torch.cat((latent_output, label_output), dim=1)# 通过生成器的主要结构将合并后的特征图生成为RGB图像image = self.model(concat)return imagegenerator = Generator().to(device)
generator.apply(weights_init)
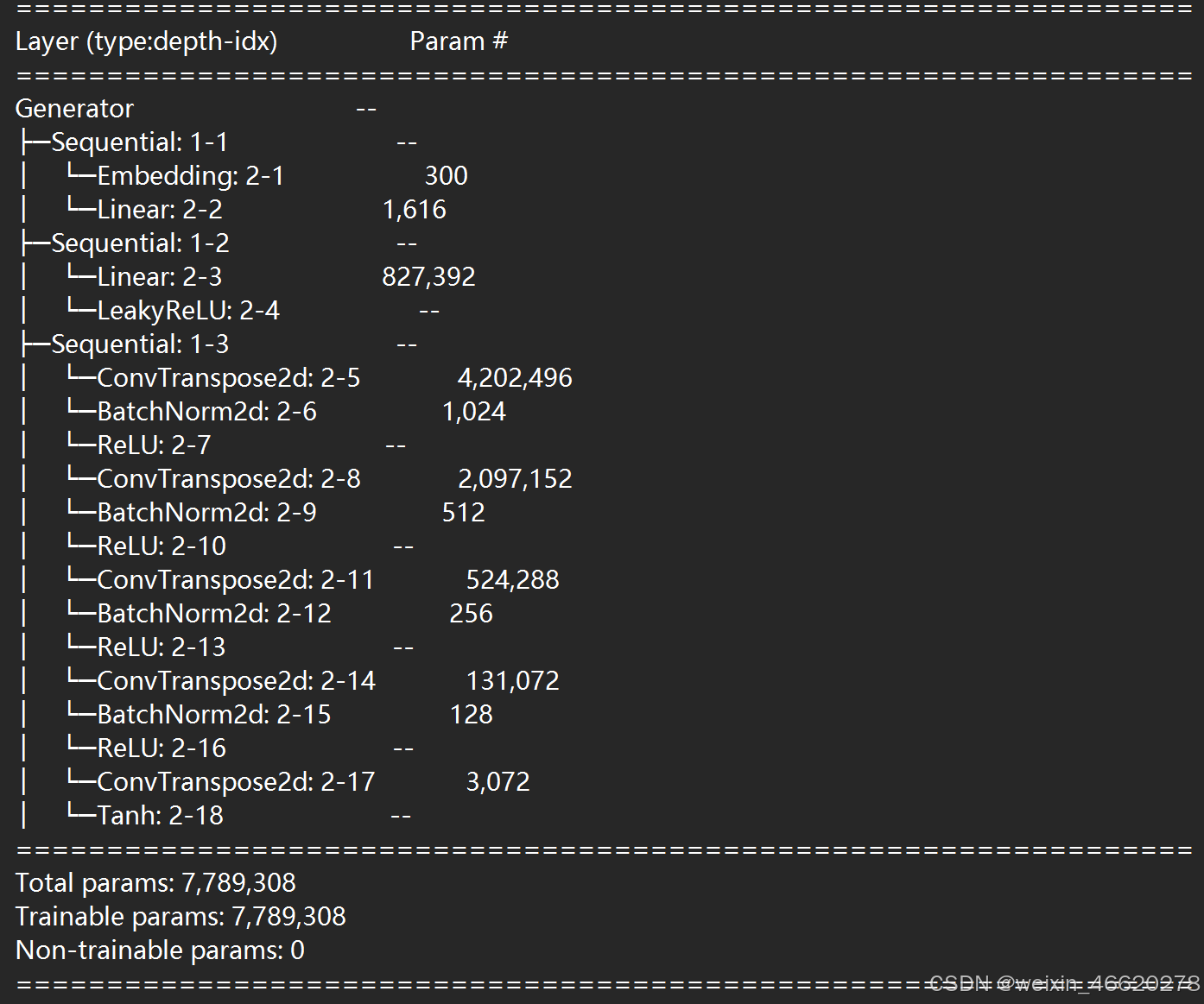
print(generator)summary(generator)模型打印输出:
print(generator)
summary(generator)

3.2 构建鉴别器
代码如下:
# 2.2 构建鉴别器
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()# 定义一个条件标签的嵌入层,用于将类别标签转换为特征向量self.label_condition_disc = nn.Sequential(nn.Embedding(n_classes, embedding_dim), # 嵌入层将类别标签编码为固定长度的向量nn.Linear(embedding_dim, 3 * 128 * 128) # 线性层将嵌入的向量转换为与图像尺寸相匹配的特征张量)# 定义主要的鉴别器模型self.model = nn.Sequential(nn.Conv2d(6, 64, 4, 2, 1, bias=False), # 输入通道为6(包含图像和标签的通道数),输出通道为64,4x4的卷积核,步长为2,padding为1nn.LeakyReLU(0.2, inplace=True), # LeakyReLU激活函数,带有负斜率,增加模型对输入中的负值的感知能力nn.Conv2d(64, 64 * 2, 4, 3, 2, bias=False), # 输入通道为64,输出通道为64*2,4x4的卷积核,步长为3,padding为2nn.BatchNorm2d(64 * 2, momentum=0.1, eps=0.8), # 批量归一化层,有利于训练稳定性和收敛速度nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64 * 2, 64 * 4, 4, 3, 2, bias=False), # 输入通道为64*2,输出通道为64*4,4x4的卷积核,步长为3,padding为2nn.BatchNorm2d(64 * 4, momentum=0.1, eps=0.8),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64 * 4, 64 * 8, 4, 3, 2, bias=False), # 输入通道为64*4,输出通道为64*8,4x4的卷积核,步长为3,padding为2nn.BatchNorm2d(64 * 8, momentum=0.1, eps=0.8),nn.LeakyReLU(0.2, inplace=True),nn.Flatten(), # 将特征图展平为一维向量,用于后续全连接层处理nn.Dropout(0.4), # 随机失活层,用于减少过拟合风险nn.Linear(4608, 1), # 全连接层,将特征向量映射到输出维度为1的向量nn.Sigmoid() # Sigmoid激活函数,用于输出范围限制在0到1之间的概率值)def forward(self, inputs):img, label = inputs# 将类别标签转换为特征向量label_output = self.label_condition_disc(label)# 重塑特征向量为与图像尺寸相匹配的特征张量label_output = label_output.view(-1, 3, 128, 128)# 将图像特征和标签特征拼接在一起作为鉴别器的输入concat = torch.cat((img, label_output), dim=1)# 将拼接后的输入通过鉴别器模型进行前向传播,得到输出结果output = self.model(concat)return outputdiscriminator = Discriminator().to(device)
discriminator.apply(weights_init)
print(discriminator)
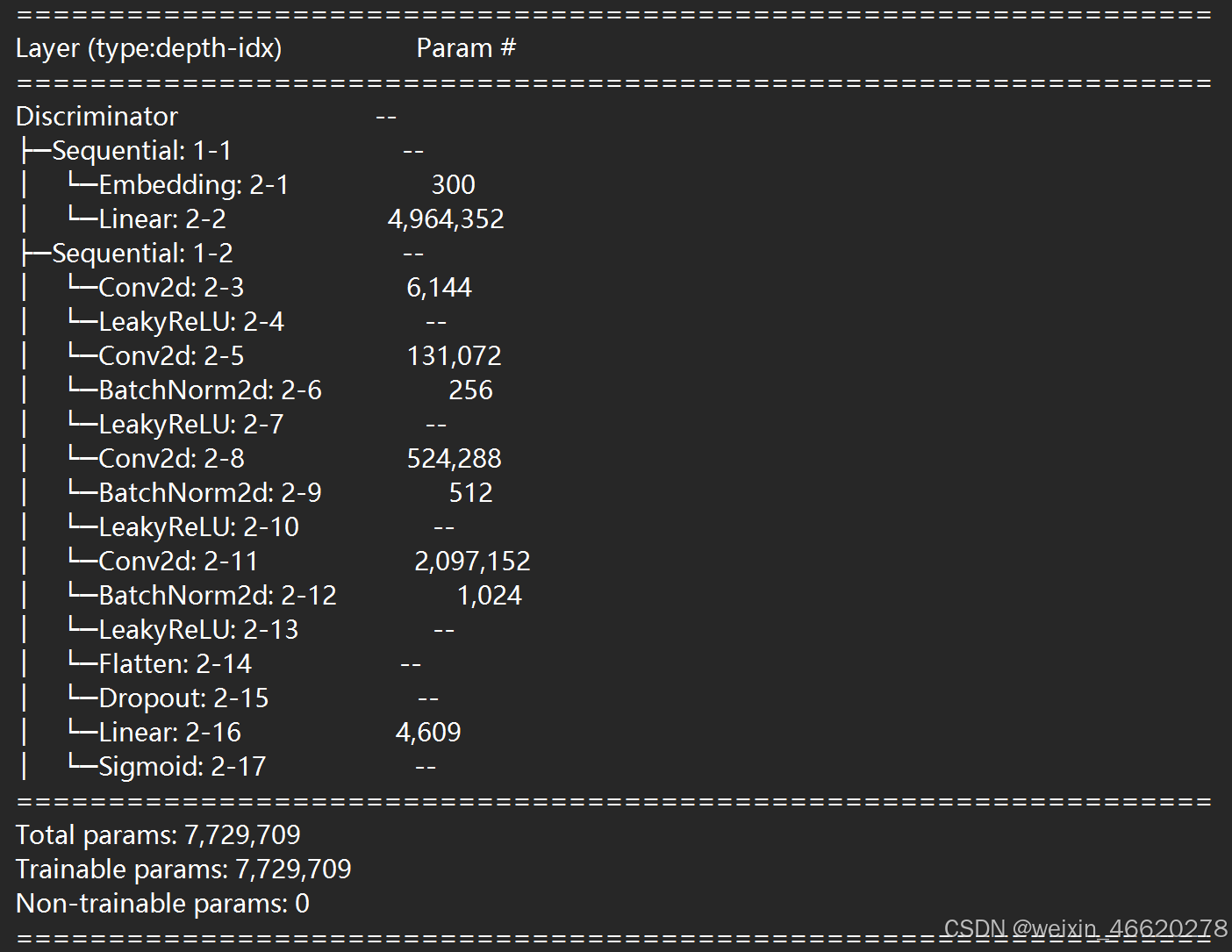
summary(discriminator)模型输出打印:
print(discriminator)
summary(discriminator)

使用示例代码
a = torch.ones(2, 3, 128, 128)
b = torch.ones(2, 1)
b = b.long()
a = a.to(device)
b = b.to(device)c = discriminator((a, b))
print(c.size())输出如下:
torch.Size([2,1])
四、训练函数
4.1 定义损失函数
代码如下:
# 三、训练模型
# 3.1 定义损失函数
adversarial_loss = nn.BCELoss()
def generator_loss(fake_output, label):gen_loss = adversarial_loss(fake_output, label)return gen_lossdef discriminator_loss(output, label):disc_loss = adversarial_loss(output, label)return disc_loss4.2 定义优化器
代码如下:
# 3.2 定义优化器
learning_rate = 0.0002
G_optimizer = optim.Adam(generator.parameters(), lr=learning_rate, betas=(0.5, 0.999))
D_optimizer = optim.Adam(discriminator.parameters(), lr=learning_rate, betas=(0.5, 0.999))
4.3 训练模型
代码逻辑结构图
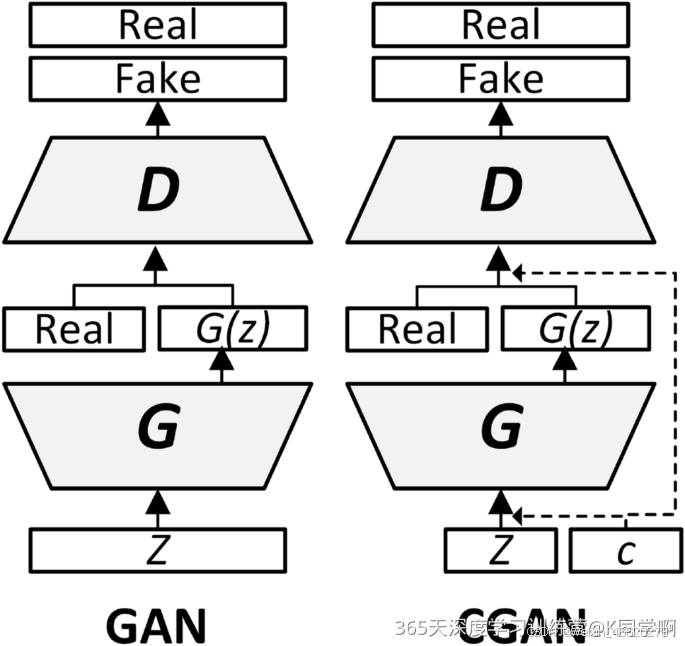
- 首先设置了训练的总轮数和用于存储每轮训练中判别器和生成器损失的列表.
- 然后进行GAN模型的训练,在每轮训练中,它首先从数据加载器中加载真实图像和标签,然后计算判别器对真实图像的损失,接着从噪声向量中生成假图像,计算判别器对假图像的损失,计算判别器总体损失并反向传播更新判别器的参数,然后计算生成器的损失反向传播更新生成器的参数。
- 最后,它打印当前轮次的判别器和生成器的平均损失,并将当前轮次的判别器和生成器的平均损失保存到列表中。
- 在每10轮训练后,它会将生成的假图像保存为图片文件,并将当前轮次的生成器和判别器的权重保存到文件
代码如下:
# 3.3 训练模型
# 设置训练的总轮数
num_epochs = 100
# 初始化用于存储每轮训练中判别器和生成器损失的列表
D_loss_plot, G_loss_plot = [], []# 循环进行训练
for epoch in range(1, num_epochs + 1):# 初始化每轮训练中判别器和生成器损失的临时列表D_loss_list, G_loss_list = [], []# 遍历训练数据加载器中的数据for index, (real_images, labels) in enumerate(train_loader):# 清空判别器的梯度缓存D_optimizer.zero_grad()# 将真实图像数据和标签转移到GPU(如果可用)real_images = real_images.to(device)labels = labels.to(device)# 将标签的形状从一维向量转换为二维张量(用于后续计算)labels = labels.unsqueeze(1).long()# 创建真实目标和虚假目标的张量(用于判别器损失函数)real_target = Variable(torch.ones(real_images.size(0), 1).to(device))fake_target = Variable(torch.zeros(real_images.size(0), 1).to(device))# 计算判别器对真实图像的损失D_real_loss = discriminator_loss(discriminator((real_images, labels)), real_target)# 从噪声向量中生成假图像(生成器的输入)noise_vector = torch.randn(real_images.size(0), latent_dim, device=device)noise_vector = noise_vector.to(device)generated_image = generator((noise_vector, labels))# 计算判别器对假图像的损失(注意detach()函数用于分离生成器梯度计算图)output = discriminator((generated_image.detach(), labels))D_fake_loss = discriminator_loss(output, fake_target)# 计算判别器总体损失(真实图像损失和假图像损失的平均值)D_total_loss = (D_real_loss + D_fake_loss) / 2D_loss_list.append(D_total_loss)# 反向传播更新判别器的参数D_total_loss.backward()D_optimizer.step()# 清空生成器的梯度缓存G_optimizer.zero_grad()# 计算生成器的损失G_loss = generator_loss(discriminator((generated_image, labels)), real_target)G_loss_list.append(G_loss)# 反向传播更新生成器的参数G_loss.backward()G_optimizer.step()# 打印当前轮次的判别器和生成器的平均损失print('Epoch: [%d/%d]: D_loss: %.3f, G_loss: %.3f' % ((epoch), num_epochs, torch.mean(torch.FloatTensor(D_loss_list)),torch.mean(torch.FloatTensor(G_loss_list))))# 将当前轮次的判别器和生成器的平均损失保存到列表中D_loss_plot.append(torch.mean(torch.FloatTensor(D_loss_list)))G_loss_plot.append(torch.mean(torch.FloatTensor(G_loss_list)))if epoch % 10 == 0:# 将生成的假图像保存为图片文件save_image(generated_image.data[:50], './images/sample_%d' % epoch + '.png', nrow=5, normalize=True)# 将当前轮次的生成器和判别器的权重保存到文件torch.save(generator.state_dict(), './training_weights/generator_epoch_%d.pth' % (epoch))torch.save(discriminator.state_dict(), './training_weights/discriminator_epoch_%d.pth' % (epoch))
训练过程打印:
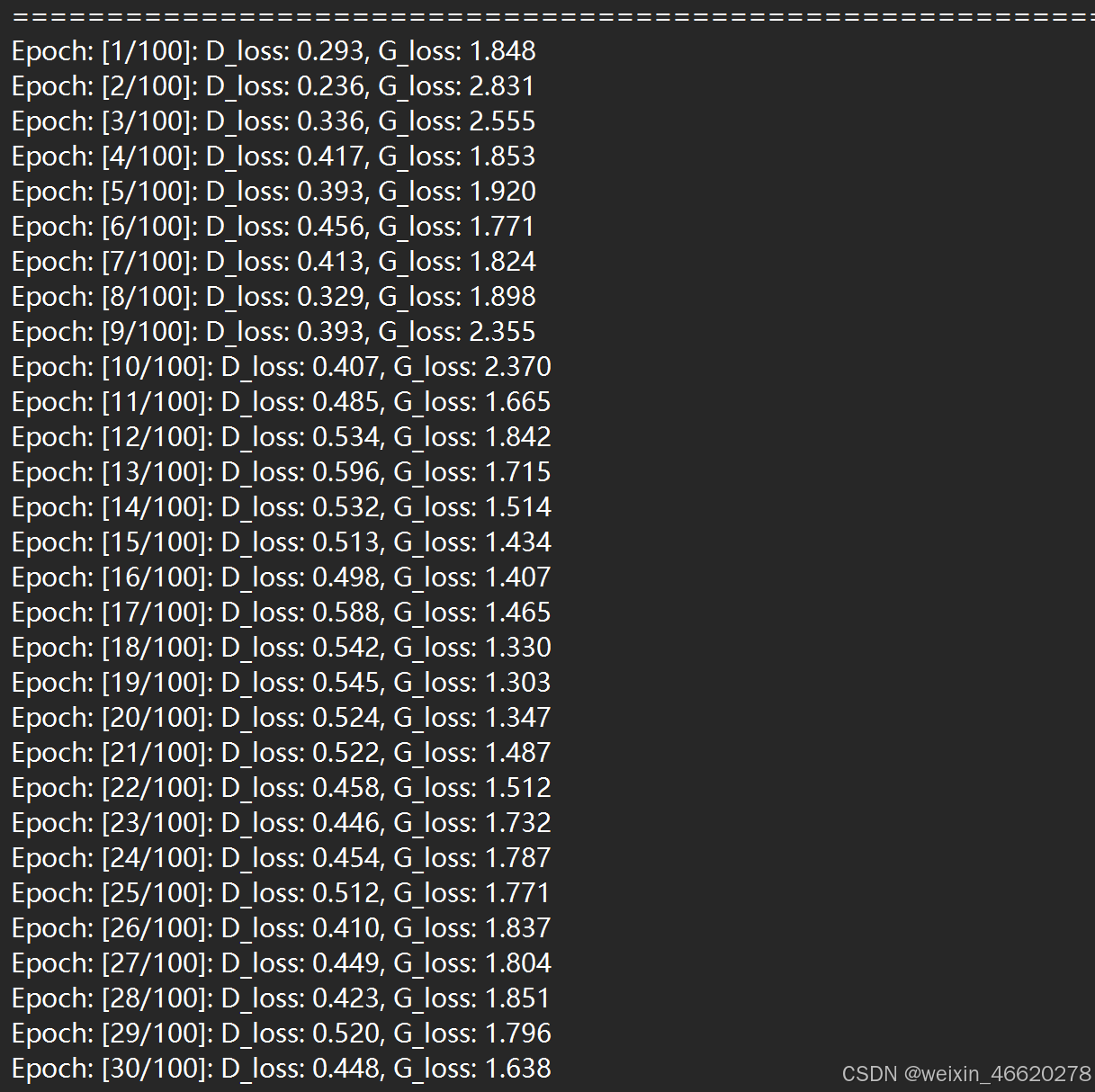
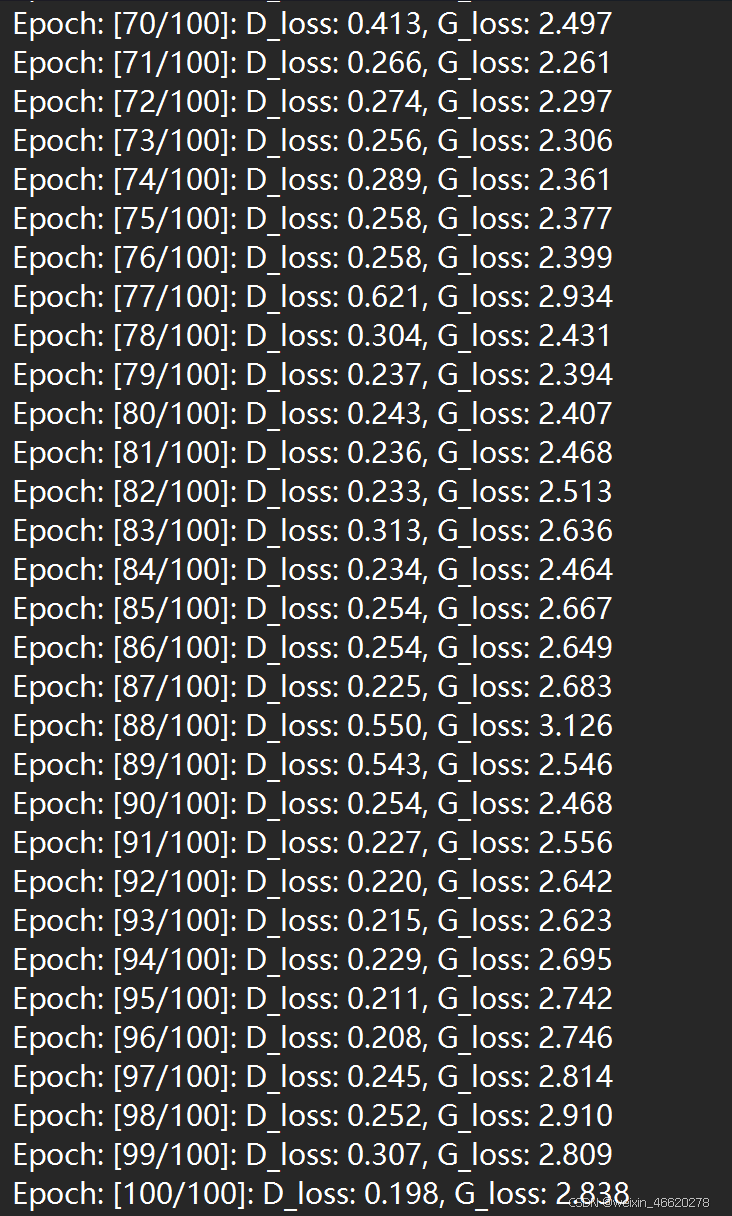
五、模型分析
5.1 加载模型
代码如下:
# 四、模型分析
# 4.1 加载模型
generator.load_state_dict(torch.load('./training_weights/generator_epoch_100.pth'), strict=False)
generator.eval()generator.load_state_dict(torch.load('./training_weights/generator_epoch_100.pth'), strict=False)
generator.eval()# 导入所需的库
from numpy import asarray
from numpy.random import randn
from numpy.random import randint
from numpy import linspace
from matplotlib import pyplot
from matplotlib import gridspec# 生成潜在空间的点,作为生成器的输入
def generate_latent_points(latent_dim, n_samples, n_classes=3):# 从标准正态分布中生成潜在空间的点x_input = randn(latent_dim * n_samples)# 将生成的点整形成用于神经网络的输入的批量z_input = x_input.reshape(n_samples, latent_dim)return z_input# 在两个潜在空间点之间进行均匀插值
def interpolate_points(p1, p2, n_steps=10):# 在两个点之间进行插值,生成插值比率ratios = linspace(0, 1, num=n_steps)# 线性插值向量vectors = list()for ratio in ratios:v = (1.0 - ratio) * p1 + ratio * p2vectors.append(v)return asarray(vectors)# 生成两个潜在空间的点
pts = generate_latent_points(100, 2)
# 在两个潜在空间点之间进行插值
interpolated = interpolate_points(pts[0], pts[1])# 将数据转换为torch张量并将其移至GPU(假设device已正确声明为GPU)
interpolated = torch.tensor(interpolated).to(device).type(torch.float32)output = None
# 对于三个类别的循环,分别进行插值和生成图片
for label in range(3):# 创建包含相同类别标签的张量labels = torch.ones(10) * labellabels = labels.to(device)labels = labels.unsqueeze(1).long()print(labels.size())# 使用生成器生成插值结果predictions = generator((interpolated, labels))predictions = predictions.permute(0, 2, 3, 1)pred = predictions.detach().cpu()if output is None:output = predelse:output = np.concatenate((output, pred))nrow = 3
ncol = 10fig = plt.figure(figsize=(15, 4))
gs = gridspec.GridSpec(nrow, ncol)k = 0
for i in range(nrow):for j in range(ncol):pred = (output[k, :, :, :] + 1) * 127.5pred = np.array(pred)ax = plt.subplot(gs[i, j])ax.imshow(pred.astype(np.uint8))ax.set_xticklabels([])ax.set_yticklabels([])ax.axis('off')k += 1plt.show()输出:
print(labels.size())
torch.Size([10, 1])
torch.Size([10, 1])
torch.Size([10, 1])print(output.shape())
(30,128,128,3)
训练过程的一些生成
sample_10 sample_50 sample_100




总结
本周了解条件生成对抗网络(CGAN)的基本原理以及CGAN是如何实现条件控制的,学习CGAN代码并跑通代码。但最后的结果还是有一些不是很清晰,后续需要考虑一下如何改进。






