目录
- 1. LLM-Based Agent的Memory
- 1.1 基础概念
- 1.2 用于解释Memory的例子
- 1.3 智能体记忆的定义
- 1.3.1 狭义定义(肯定不用这个定义)
- 1.3.2 广义定义
- 1.4 记忆协助下智能体与环境的交互过程
- 1.4.1 记忆写入
- 1.4.2 记忆管理
- 1.4.3 记忆读取
- 1.4.4 总过程
- 2. 如何实现智能体记忆模块
- 2.1 记忆来源
- 2.2 记忆形式
- 2.2.1 文本形式
- 2.2.2 参数形式
- 2.2.3 文本记忆和参数记忆的对比
- 2.3 记忆操作
- 3. 评估记忆
- 3.1 直接评估
- 3.1.1 主观评估
- 3.1.2 客观评估
- 3.1.2.1 结果正确率
- 3.1.2.2 引用正确率
- 3.1.2.3 时间和硬件消耗
- 3.2 间接评估
- 3.2.1 对话
- 3.2.2 多源问题回答
- 3.2.3 长上下文应用
- 3.2.4 其他任务
- 参考
1. LLM-Based Agent的Memory
1.1 基础概念
| 概念 | 定义 |
|---|---|
| Task | 智能体最终需要完成的目标(论文中用 τ \LARGE \tau τ表示)。 |
| Environment | 狭义上是指智能体为了完成任务需要交互的物体; 广义上是指影响智能体决定的上下文因素。 |
| Trial | 智能体执行一个动作,环境会对这个动作给出回应。这个过程一直重复直到任务完成。这个完整的智能体-环境交互过程称为Trial(论文中用 a t \large a_t at和 o t \large o_t ot分别表示step t时的智能体动作和观测环境给出的回应。因此长度为T的Trial可以表示为 ξ T = { a 1 , o 1 , a 2 , o 2 , ⋯ , a T , o T } \large \xi_T=\large \{a_1, o_1, a_2, o_2, \cdots, a_T, o_T\} ξT={a1,o1,a2,o2,⋯,aT,oT})。 |
| Step | 智能体执行动作和环境给出对应的回应构成一个Step。 |
1.2 用于解释Memory的例子
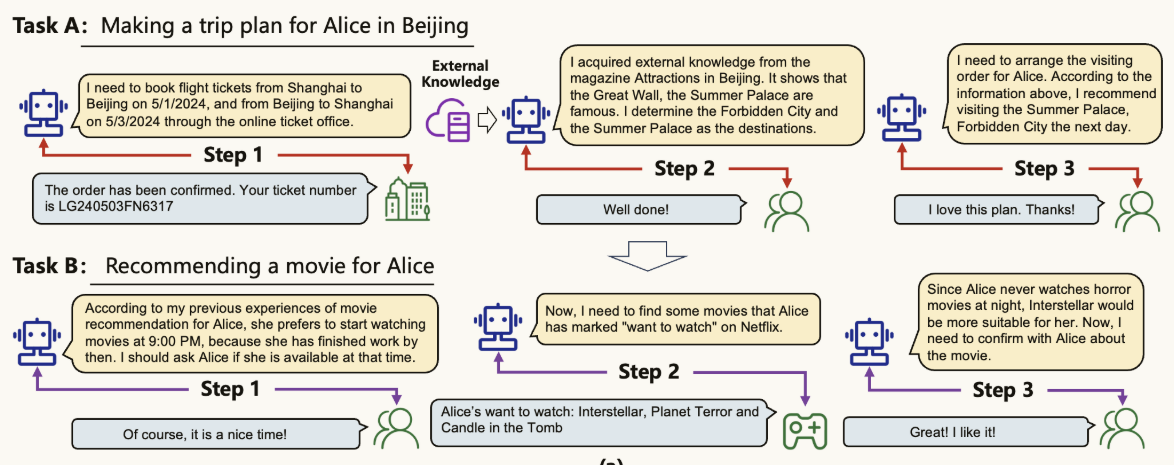
| 角色 | Task A:为Alice制定时间为2024-5-1到2024-5-3的北京旅行计划 |
|---|---|
| 智能体( a 1 A \large a_1^A a1A) | 我需要在网上售票处预定2024-5-1从上海到北京的启程机票,同时预定2024-5-3从北京到上海的返程机票。 |
| 网上售票处( o 1 A \large o_1^A o1A) | 订单已确认。启程航班会在9:00起飞,你的票号为EK240501SX9021。返程航班会在16:30起飞,你的票号为LG240503FN6317。请准时到达机场乘坐对应航班。 |
| 智能体( a 2 A \large a_2^A a2A) | 我从杂志《北京的名胜古迹》中获取了额外的知识——长城、紫禁城和颐和园是著名的景点。根据Alice的偏好,我认为她更喜欢古建筑,所以我决定紫禁城和颐和园作为旅行的目的地。 |
| Alice( o 2 A \large o_2^A o2A) | 不错! |
| 智能体( a 3 A \large a_3^A a3A) | 现在,我需要为Alice安排参观顺序。根据上面的信息,我推荐在她到达北京后先参观颐和园,因为在那里度过一下午并且观看日落是十分惬意的。然后,明天她可以有充足的时间去参观紫禁城。最后,后天她可以返回上海进行休息。 |
| Alice( o 3 A \large o_3^A o3A) | 我喜欢这个计划。谢谢! |
| 角色 | Task B:在2024-5-10这天为Alice推荐一部电影 |
|---|---|
| 智能体( a 1 B \large a_1^B a1B) | 根据我过去关于Alice电影推荐的经验,她更喜欢在21:00观看电影,因为她那时刚结束工作。我应该问Alice在那个时间是否有空。 |
| Alice( o 1 B \large o_1^B o1B) | 当然,这是一个不错的时间! |
| 智能体( a 2 B \large a_2^B a2B) | 现在,我需要在Netflix上找出一些Alice标记为想看的电影。 |
| Netflix( o 2 B \large o_2^B o2B) | Alice想看的电影:Interstellar,Planet Terror和Candle in the Tomb。 |
| 智能体( a 3 B \large a_3^B a3B) | 因为Alice从不在晚上观看恐怖电影,Interstellar应该非常适合她观看。 |
| Alice( o 3 B \large o_3^B o3B) | 不错!我喜欢这部电影! |
1.3 智能体记忆的定义
1.3.1 狭义定义(肯定不用这个定义)
狭义上来说,智能体的记忆应该只与同一个Trial的历史信息有关。对于一个给定的任务,在步骤 t t t之前一个Trial的历史信息为 ξ t = { a 1 , o 1 , a 2 , o 2 , ⋯ , a t − 1 , o t − 1 } \large \xi_t=\large \{a_1, o_1, a_2, o_2, \cdots, a_{t-1}, o_{t-1}\} ξt={a1,o1,a2,o2,⋯,at−1,ot−1},而记忆是根据 ξ t \large \xi_t ξt推导出来的内容。对于上面的Task A来说,智能体在第3步的时候需要为Alice安排参观顺序;在这个时候,它的记忆包含在第1步中的到达时间和第2步中选择景点的信息。对于Task B来说,智能体在第3步中需要为Alice选择一部电影;在这个时候,它的记忆包含在第1步中观看电影的时间和第2步中Alice想看的电影。
1.3.2 广义定义
广义上来说,智能体的记忆来自更多来源。假如给定一系列的任务 { τ 1 , τ 2 , ⋯ , τ K } \{\LARGE \tau_{\small 1}, \LARGE \tau_{\small 2}, \cdots, \LARGE \tau_{\small K} \normalsize \} {τ1,τ2,⋯,τK},对于任务 τ k \LARGE \tau_{\small k} τk,在第 t t t步时记忆来自以下三个来源:
1. 来自当前Trial的历史信息 ξ t k = { a 1 k , o 1 k , ⋯ , a t − 1 k , o t − 1 k } \large \xi_t^k=\{a_1^k, o_1^k, \cdots, a_{t-1}^k, o_{t-1}^k\} ξtk={a1k,o1k,⋯,at−1k,ot−1k}。
2. 跨不同Trial的历史信息 Ξ k = { ξ 1 , ξ 2 , ⋯ , ξ k − 1 , ξ k ′ } \Xi^k=\{\xi^1, \xi^2, \cdots, \xi^{k-1}, \xi^{k'}\} Ξk={ξ1,ξ2,⋯,ξk−1,ξk′},其中 ξ j ( j ∈ { 1 , ⋯ , k − 1 } ) \xi^j(j\in\{1,\cdots,k-1\}) ξj(j∈{1,⋯,k−1})代表 τ j \LARGE \tau_j τj的Trials, ξ k ′ \xi^{k'} ξk′代表最近对 τ k \LARGE \tau_k τk探索的Trials。
3. 额外的知识 D t k D_t^k Dtk。
智能体的记忆是根据 ( ξ t k , Ξ k , D t k ) (\xi_t^k,\Xi^k,D_t^k) (ξtk,Ξk,Dtk)推导出来的内容。
对于Task A来说,如果有几个失败的Trials,Alice给出的反馈是消极的,那么这些trials可以插入到智能体的记忆里以避免未来重犯相同的错误(对应于 ξ k ′ \xi^{k'} ξk′)。对于Task B来说,智能体可能推荐与Alice在Task A参观景点有关的电影,以捕获她最近的偏好(对应于 { ξ 1 , ξ 2 , ⋯ , ξ k − 1 } \{\xi^1, \xi^2, \cdots, \xi^{k-1}\} {ξ1,ξ2,⋯,ξk−1})。在智能体决策过程中,它参考了杂志《北京的名胜景点》来制定旅行计划,这对于当前任务来说是额外的知识(对应于 D t k D_t^k Dtk)。
1.4 记忆协助下智能体与环境的交互过程
智能体的记忆模块需要通过三个操作来实现智能体与环境的交互,这三个操作分别是记忆写入、记忆管理、记忆读取。
1.4.1 记忆写入
记忆写入旨在将原始观察结果(环境给出的回应)投影到实际存储的记忆内容中,使得记忆内容丰富且简洁。这对应于智能体与环境一次交互过程中的第一步——智能体接受来自环境的信息,并将它存储到记忆中。给定一个任务 τ k \LARGE \tau_{\small k} τk,如果智能体在第 t t t步时采取了行动 a t k \large a_t^k atk,然后环境给出了回应 o t k \large o_t^k otk,最后进行记忆写入操作:
m t k = W ( { a t k , o t k } ) . \large m_t^k= W(\{a_t^k, o_t^k\}). mtk=W({atk,otk}).
其中 W W W是一个投影函数, m t k \large m_t^k mtk是最终要存储的记忆内容,可以是自然语言或参数化的表达。对于Task A来说,智能体在第2步之后要记住航班安排和选择的景点。对于Task B来说,智能体在第1步之后记住Alice希望在21:00看电影这个事实。
1.4.2 记忆管理
记忆管理操作旨在处理已存储的记忆,使其更为有效。例如,总结高级概念以使智能体更加通用,合并相似信息以降低重复,遗忘不重要、不相关信息以去除这些记忆造成的消极影响。这对应于智能体与环境一次交互过程中的第二步——智能体处理存储的信息使其变得更有用。假设 M t − 1 k M_{t-1}^k Mt−1k是第 t t t步之前关于 τ k \LARGE \tau_{\small k} τk的记忆内容, m t k \large m_t^k mtk是第 t t t步时记忆写入操作产生的待存储记忆,那么记忆管理可以被描述为:
M t k = P ( M t − 1 k , m t k ) . M_t^k=P(M_{t-1}^k, m_t^k). Mtk=P(Mt−1k,mtk).
其中 P P P是一个迭代处理存储记忆的函数。对于狭义的记忆来说,这个迭代过程只发生在当前的trial中,当这个trial结束时会清空关于这个trial的记忆。对于广义的记忆来说,这个迭代过程发生在不同的trials、tasks甚至外部知识的整合中。对于Task B来说,智能体可以总结出Alice享受在夜晚观看科幻电影,这可以用作未来为Alice进行推荐时的指导守则。
1.4.3 记忆读取
记忆读取操作旨在从记忆中获取重要信息以支持下一次智能体的行动。这对应于智能体与环境一次交互过程的第三步——智能体依据处理过的记忆信息来进行下一次行动。假设 M t k M_t^k Mtk是 τ k \LARGE \tau_{\small k} τk在第 t t t步时的记忆内容, c t + 1 k c_{t+1}^k ct+1k是下一次智能体时的上下文,那么记忆读取操作可以被描述为:
M ^ t k = R ( M t k , c t + 1 k ) . \hat{M}_t^k=R(M_t^k, c_{t+1}^k). M^tk=R(Mtk,ct+1k).
其中R是计算 M t k M_t^k Mtk和 c t + 1 k c_{t+1}^k ct+1k相似度的函数。 M ^ t k \hat{M}_t^k M^tk用作驱动智能体下一次行动的最终提示词的一部分。对于Task B来说,智能体在第3步决定最终推荐的影片时,它需要聚焦于第2步中想要观看电影的列表,然后从中挑选出一部电影。
1.4.4 总过程
基于上面的3种操作,可以得出从 { a t k , o t k } \large \{a_t^k, o_t^k\} {atk,otk}到 a t + 1 k \large a_{t+1}^k at+1k的公式:
a t + 1 k = L L M { R ( P ( M t − 1 k , W ( { a t k , o t k } ) ) , c t + 1 k ) } . \large a_{t+1}^k=LLM\{R(P(M_{t-1}^k, W(\{a_t^k, o_t^k\})), c_{t+1}^k)\}. at+1k=LLM{R(P(Mt−1k,W({atk,otk})),ct+1k)}.
其中LLM是大语言模型。完整的智能体与环境交互过程可以由上面公式的迭代展开得到。
2. 如何实现智能体记忆模块
智能体记忆模块的实现需要以下三方面的内容:记忆来源、记忆形式和记忆操作。记忆来源指的是记忆内容来自哪里;记忆形式专注于如何表达记忆内容;记忆操作指的是如何处理记忆内容。
2.1 记忆来源
记忆来源主要由以下三部分构成:一次trial中的信息,不同trials之间的信息和外部知识。前两个在智能体与环境交互过程中动态生成,而后者是循环外的静态知识。
在智能体与环境不断交互的过程,一个trial的历史信息是支撑智能体未来行动的最相关和最具信息性的信号。但是仅仅只是利用一个trial中的信息不足以使智能体很好地完成任务,因此还需要跨越不同trial的信息。对于不同的trials,可以从中提取出成功和失败的行动以及对这些行动的思考等等,如此智能体便能通过不同的trials积累经验以在未来更好地完成任务。在一个trial中的历史信息,可以看做是短期记忆,而在不同的trials中积累到的经验可以看做是长期记忆。如果只是使用这两者作为智能体记忆的话,就没有包含外部知识和经验。外部知识可以解决大模型内部知识过时的问题,并且将外部知识插入到记忆中可以扩宽智能体的知识边界,从而更好地决策。
2.2 记忆形式
目前,总共由两种形式来表达记忆内容:文本形式和参数形式。对于文本形式而言,信息通过自然语言保存和检索;对于参数形式而言,记忆信息被编码成大语言模型的参数。
2.2.1 文本形式
文本形式是目前表示记忆内容的主流方法,具备更好的解释性、易实现性和更快的读写效率。文本信息可以以非结构化的形式存储,如原始的自然语言;也可以以结构化的形式存储如元组、数据库等等。目前以文本形式存储记忆信息的方法有三种:1. 存储完整的智能体与环境交互过程。2. 存储最近的部分智能体与环境交互过程。3. 通过指标挑选智能体与环境过程中的内容,然后存储挑选出的内容。
下面对这三种方法进行比较:
| 存储所有交互 | 存储最近交互 | 挑选交互存储 | |
|---|---|---|---|
| 含义 | 存储智能体与环境交互过程中的所有信息 | 存储智能体与环境交互过程中最近的信息 | 基于相关性、重要性和话题选择智能体与环境交互的信息存储 |
| 优点 | 1. 保持充足的信息 | 1. 提升记忆的效率。 2. 使智能体更专注于最近的信息 | 1. 记忆的效率和准确率依赖于检索策略 |
| 缺点 | 1. 计算代价高。 2. 容易达到大语言模型上下文的最大限制,产生信息截断从而导致信息丢失。 3. 大模型对于长文本中不同位置的内容不能平等、稳定对待,从而导致推理产生偏差。 | 1. 丢失遥远但重要的信息 | 1. 不恰当的检索策略会导致检索出不相关信息。 2. 系统可能导致大的计算成本和长的时间延迟。 3. 无法妥善存储异质信息。 |
尽管通过最新真实世界的外部知识能显著提高智能体的能力,但是由于潜在的不准确性和偏见,这些信息的可靠性是值得怀疑的。此外,智能体使用工具可能导致更高的计算成本和复杂性,也会面临隐私、数据安全和政策遵守的问题。
2.2.2 参数形式
参数形式的记忆不需要在提示词中占据额外的上下文长度,所以它不会受到大语言模型上下文的约束。参数化记忆目前有两种方式:微调和知识编辑。
| 监督微调 | 知识编辑 | |
|---|---|---|
| 优点 | 1. 更好地完成特定领域的任务。 | 1. 只改变相关的知识。 2. 计算消耗小 |
| 缺点 | 1. 过拟合。 2. 灾难性遗忘。 3. 计算和时间消耗大 | 1. 存在元学习的计算消耗。 2. 不相关知识的保存存在问题。 |
2.2.3 文本记忆和参数记忆的对比
| 文本记忆 | 参数记忆 | |
|---|---|---|
| 效果 | 文本记忆虽然能存储详细、综合的信息,但是被大语言模型提示词的token限制。 | 参数记忆不受提示词token显示,但是可能在文本转化为参数的过程产生信息损失以及一些额外的副作用。 |
| 效率 | 对于文本记忆,每个大模型推理都需要将记忆整合到提示词中,从而导致更高的计算消耗和更长的处理时间。 | 参数记忆没有将记忆整合到提示词的额外消耗,但是在将记忆写入到大语言模型参数的过程会产生额外的消耗。 |
| 可解释性 | 自然语言极具解释性。 | 存在大语言模型的参数空间,可解释性差,但是信息高度密集。 |
2.3 记忆操作
记忆写入操作需要识别那些信息需要写入,然后进行信息提取操作后将提取的信息写入到记忆中。因为原始信息通常是冗长且有噪声的。此外,在将提取的信息写入到记忆时,还需要决定记忆的表现形式。
记忆管理操作需要像人脑一样不断处理和抽象信息——生成高度抽象的记忆,合并重复的记忆和遗忘早期不重要的记忆。
记忆读取操作需要从记忆提取出相关信息,因此如何获取与当前状态高度相关的信息是记忆读取操作的核心。记忆写入时记忆的表达形式高度影响记忆读取。
3. 评估记忆
3.1 直接评估
直接评估将智能体的记忆作为单独模块,从而单独评估它的有效性。之前研究中直接评估可以分为两类:主观评估和客观评估。
3.1.1 主观评估
在主观评估中,需要解决两个问题:1. 什么方面应该被评估。2. 怎样构建评估流程。下面首先介绍大多数研究用来评估记忆模块的两个方面。
连贯性指的是从记忆模块中得到的记忆是否与当前上下文合适。例如,如果智能体正在为Alice的旅行进行规划时,从记忆模块中得到的记忆应该是与她的旅行偏好而不是工作偏好。合理性指的是从记忆模块中得到的记忆是否是合理的,例如,如果智能体被问及颐和园在哪里,从记忆模块中得到的记忆应该是颐和园在北京而不是颐和园在月亮上。
关于评估流程的构建同样面临两个问题:1. 如何选择人类评估者。2. 如何给记忆模块的输出打分。对于人类评估者而言,他们必须熟悉评估任务,并且给出可信、可靠的得分。此外,必须挑选来自多个不同背景的评估者,以确保消除特殊人类群体的主观偏见。对于评价记忆模块的输出而言,可以直接评价输出或者在两个候选输出之间进行比较。此外,还需要仔细设计评级,保证足够的细粒度但又不至于过度细致。
主观评价的优点是可解释,评价者可以给出他们为什么这样评价的理由,缺点是耗时耗力以及评价者自身可能有某些偏见。
3.1.2 客观评估
3.1.2.1 结果正确率
这个指标测量智能体是否在基于记忆模块的基础上正确回答预定义的问题。例如,问题是Alice今天去过哪里了,两个选择分别是颐和园和长城。然后智能体基于记忆和问题选择正确答案。或者智能体生成的答案与真正的答案进行比较。该指标的计算公式为:
C o r r e c t n e s s = 1 N ∑ i = 1 N I [ a i = a ^ i ] . Correctness=\frac{1}{N}\sum_{i=1}^N\mathbb{I}[a_i=\hat{a}_i]. Correctness=N1i=1∑NI[ai=a^i].
其中 N N N代表问题的数量, a i a_i ai代表第 i i i问题真正的答案, a ^ i \hat{a}_i a^i是智能体给出的答案, I [ a i = a ^ i ] = { 1 i f a i = a ^ i , 0 i f a i ≠ a ^ i . \mathbb{I}[a_i=\hat{a}_i]=\left\{\begin{aligned}1\quad &if \ a_i=\hat{a}_i,\\0\quad &if \ a_i\neq\hat{a}_i.\end{aligned}\right. I[ai=a^i]={10if ai=a^i,if ai=a^i.。
3.1.2.2 引用正确率
该指标测量的是智能体能否发现能用来回答问题的相关信息。该指标更关心支持智能体做出最终结果的中间信息。对于Alice今天去过哪里这个问题,假如记忆模块中包括(A)Alice和朋友在王府井吃中饭和(B)Alice中午吃烤鸭,一个好的记忆模块应该选择(A)作为参考来回答问题。研究者利用F1-得分计算计算引用正确率:
F1 = 2 Precision ⋅ Recall Precision + Recall . \text{F1}=\frac{2\text{Precision}·\text{Recall}}{\text{Precision}+\text{Recall}}. F1=Precision+Recall2Precision⋅Recall.
其中 Precision = TP TP + FP \text{Precision}=\frac{\text{TP}}{\text{TP}+\text{FP}} Precision=TP+FPTP, Recall = TP TP + FN \text{Recall}=\frac{\text{TP}}{\text{TP}+\text{FN}} Recall=TP+FNTP。
3.1.2.3 时间和硬件消耗
总的时间消耗包括记忆适应和记忆读取。计算公式如下:
Δ time = 1 M ∑ i = 1 M t i end − t i start . \Delta\text{time}=\frac{1}{M}\sum_{i=1}^Mt_i^{\text{end}}-t_i^{\text{start}}. Δtime=M1i=1∑Mtiend−tistart.
其中 M M M是记忆操作的数量, t i end t_i^{\text{end}} tiend是第 i i i次操作的结束时间, t i start t_i^{\text{start}} tistart是第 i i i次操作的开始时间。此外对于计算而言,峰值GPU利用率也可作为一个评价指标。
3.2 间接评估
通过任务的完成度来评价记忆模块也是一个流行的评估策略。如果一个智能体完成了一个高度依赖记忆的任务,可以认为记忆模块是非常有效的。
3.2.1 对话
与人类进行对话是智能体最重要的应用之一,记忆在这个过程中起着至关重要的作用。通过在内存中存储上下文信息,智能体允许用户体验个性化的对话,从而提高用户的满意度。因此,当智能体的其他部分被确定时,对话任务的性能可以反映不同记忆模块的有效性。
在对话情境中,一致性和参与度是评估主体记忆有效性的两种常用方法。一致性是指智能体的响应如何与上下文一致,因为在对话期间应该避免戏剧性的变化。参与度是指用户如何参与继续对话。它反映了智能体响应的质量和吸引力,以及智能体为当前对话制作人物角色的能力。
3.2.2 多源问题回答
多源问答可以综合评价来自多个来源的记忆信息,包括trial内信息、trial间信息和外部知识。它着重于集成来自不同内容和来源记忆的利用问题。通过评价多源问答任务,可以考察智能体对不同来源内容整合能力的记忆。它还揭示了由于多个信息源的内存矛盾的问题,以及知识更新的问题,这可能会影响记忆模块的性能。
3.2.3 长上下文应用
在许多情况下,基于LLM的智能体必须根据极长的提示做出决策。在这些场景中,长提示通常被视为记忆内容,在驱动智能体行为方面起着重要作用。
对于特定的长上下文任务,长上下文段落检索是评价智能体长上下文能力的重要任务之一。它要求智能体在一个长的上下文中找到与给定的问题或描述相对应的正确段落。长上下文摘要是另一个具有代表性的任务。它要求智能体对整个上下文有一个全局的理解,并根据描述进行总结,其中可以利用ROUGE等匹配分数的一些度量来将结果与真实答案进行比较。
长上下文应用程序的评估提供了更广泛的方法来评估代理中的记忆功能,重点是实际的下游场景。
3.2.4 其他任务
除了上述三类主要任务进行间接评估外,一般任务中还有一些其他指标可以揭示记忆模块的有效性。成功率是指智能体能够成功解决的任务的比例。探索度通常出现在探索性博弈中,它反映了主体对环境的探索程度。事实上,几乎所有配备记忆的智能体都可以通过消融研究来评估记忆的效果,比较有/没有记忆模块之间的性能。对具体场景的评估更能体现记忆对于下游应用的实际意义。
参考
Zeyu Zhang, Xiaohe Bo, Chen Ma, and et al. A Survey on the Memory Mechanism of Large
Language Model based Agents.



