
高效写入
本章内容将介绍如何发挥 TDengine 最大写入性能,通过原理解析到参数如何配置再到实际示例演示,完整描述如何达到高效写入。
为帮助用户轻松构建百万级吞吐量的数据写入管道,TDengine 连接器提供高效写入的特性。
启动高效写入特性后,TDengine 连接器将自动创建写入线程与专属队列,将数据按子表切分缓存,在达到数据量阈值或超时条件时批量发送,以此减少网络请求、提升吞吐量,让用户无需掌握多线程编程知识和数据切分技巧即可实现高性能写入。
高效写入使用方法
下面介绍各连接器高效写入特性的使用方法:
一、JDBC 高效写入特性概述
JDBC 驱动从 3.6.0 版本开始,在 WebSocket 连接上提供了高效写入特性。JDBC 驱动高效写入特性有如下特点:
- 支持 JDBC 标准参数绑定接口。
- 在资源充分条件下,写入能力跟写入线程数配置线性相关。
- 支持写入超时和连接断开重连后的重试次数和重试间隔配置。
- 支持调用
executeUpdate接口获取写入数据条数,若写入有异常,此时可捕获。
下面详细介绍其使用方法。本节内容假设用户已经熟悉 JDBC 标准参数绑定接口(可参考 参数绑定)。
二、如何开启高效写入特性:
对于 JDBC 连接器来说,有两种方式开启高效写入特性:
- 在连接属性上设置 PROPERTY_KEY_ASYNC_WRITE 为
stmt或者 JDBC URL 中增加asyncWrite=stmt都可以在此连接上开启高效写入。在连接上开启高效写入特性后,后续所有创建的PreparedStatement都会使用高效写入模式。 - 在参数绑定创建
PreparedStatement所用的 SQL 中,使用ASYNC_INSERT INTO而不是INSERT INTO,则可以在这个参数绑定对象上开启高效写入。
三、如何检查写入是否成功:
客户应用使用 JDBC 标准接口的 addBatch 添加一条记录,用 executeBatch 提交所有添加记录。高效写入模式下,可以使用 executeUpdate 方法来同步获取写入成功条数,如果有数据写入失败,此时调用 executeUpdate 会捕获到异常。
四、高效写入重要配置参数:
-
TSDBDriver.PROPERTY_KEY_BACKEND_WRITE_THREAD_NUM:高效写入模式下,后台写入线程数。仅在使用 WebSocket 连接时生效。默认值为 10。
-
TSDBDriver.PROPERTY_KEY_BATCH_SIZE_BY_ROW:高效写入模式下,写入数据的批大小,单位是行。仅在使用 WebSocket 连接时生效。默认值为 1000。
-
TSDBDriver.PROPERTY_KEY_CACHE_SIZE_BY_ROW:高效写入模式下,缓存的大小,单位是行。仅在使用 WebSocket 连接时生效。默认值为 10000。
-
TSDBDriver.PROPERTY_KEY_ENABLE_AUTO_RECONNECT:是否启用自动重连。仅在使用 WebSocket 连接时生效。true:启用,false:不启用。默认为 false。高效写入模式建议开启。
-
TSDBDriver.PROPERTY_KEY_RECONNECT_INTERVAL_MS:自动重连重试间隔,单位毫秒,默认值 2000。仅在 PROPERTY_KEY_ENABLE_AUTO_RECONNECT 为 true 时生效。
-
TSDBDriver.PROPERTY_KEY_RECONNECT_RETRY_COUNT:自动重连重试次数,默认值 3,仅在 PROPERTY_KEY_ENABLE_AUTO_RECONNECT 为 true 时生效。
其他配置参数请参考 高效写入配置。
五、JDBC 高效写入使用说明
下面是一个简单的使用 JDBC 高效写入的例子,说明了高效写入相关的配置和接口。
public class WSHighVolumeDemo {// modify host to your ownprivate static final String HOST = "127.0.0.1";private static final int port = 6041;private static final Random random = new Random(System.currentTimeMillis());private static final int NUM_OF_SUB_TABLE = 10000;private static final int NUM_OF_ROW = 10;public static void main(String[] args) throws SQLException {String url = "jdbc:TAOS-WS://" + HOST + ":" + port + "/?user=root&password=taosdata";Properties properties = new Properties();// Use an efficient writing modeproperties.setProperty(TSDBDriver.PROPERTY_KEY_ASYNC_WRITE, "stmt");// The maximum number of rows to be batched in a single write requestproperties.setProperty(TSDBDriver.PROPERTY_KEY_BATCH_SIZE_BY_ROW, "10000");// The maximum number of rows to be cached in the queue (for each backend write// thread)properties.setProperty(TSDBDriver.PROPERTY_KEY_CACHE_SIZE_BY_ROW, "100000");// Number of backend write threadsproperties.setProperty(TSDBDriver.PROPERTY_KEY_BACKEND_WRITE_THREAD_NUM, "5");// Enable this option to automatically reconnect when the connection is brokenproperties.setProperty(TSDBDriver.PROPERTY_KEY_ENABLE_AUTO_RECONNECT, "true");// The maximum time to wait for a write request to be processed by the server in// millisecondsproperties.setProperty(TSDBDriver.PROPERTY_KEY_MESSAGE_WAIT_TIMEOUT, "5000");// Enable this option to copy data when modifying binary data after the// `addBatch` method is calledproperties.setProperty(TSDBDriver.PROPERTY_KEY_COPY_DATA, "false");// Enable this option to check the length of the sub-table name and the length// of variable-length data typesproperties.setProperty(TSDBDriver.PROPERTY_KEY_STRICT_CHECK, "false");try (Connection conn = DriverManager.getConnection(url, properties)) {init(conn);// If you are certain that the child table exists, you can avoid binding the tag// column to improve performance.String sql = "INSERT INTO power.meters (tbname, groupid, location, ts, current, voltage, phase) VALUES (?,?,?,?,?,?,?)";try (PreparedStatement pstmt = conn.prepareStatement(sql)) {long current = System.currentTimeMillis();int rows = 0;for (int j = 0; j < NUM_OF_ROW; j++) {// To simulate real-world scenarios, we adopt the approach of writing a batch of// sub-tables, with one record per sub-table.for (int i = 1; i <= NUM_OF_SUB_TABLE; i++) {pstmt.setString(1, "d_" + i);pstmt.setInt(2, i);pstmt.setString(3, "location_" + i);pstmt.setTimestamp(4, new Timestamp(current + j));pstmt.setFloat(5, random.nextFloat() * 30);pstmt.setInt(6, random.nextInt(300));pstmt.setFloat(7, random.nextFloat());// when the queue of backend cached data reaches the maximum size, this method// will be blockedpstmt.addBatch();rows++;}pstmt.executeBatch();if (rows % 50000 == 0) {// The semantics of executeUpdate in efficient writing mode is to synchronously// retrieve the number of rows written between the previous call and the current// one.int affectedRows = pstmt.executeUpdate();Assert.equals(50000, affectedRows);}}}} catch (Exception ex) {// please refer to the JDBC specifications for detailed exceptions infoSystem.out.printf("Failed to insert to table meters using efficient writing, %sErrMessage: %s%n",ex instanceof SQLException ? "ErrCode: " + ((SQLException) ex).getErrorCode() + ", " : "",ex.getMessage());// Print stack trace for context in examples. Use logging in production.ex.printStackTrace();throw ex;}}private static void init(Connection conn) throws SQLException {try (Statement stmt = conn.createStatement()) {stmt.execute("CREATE DATABASE IF NOT EXISTS power");stmt.execute("USE power");stmt.execute("CREATE STABLE IF NOT EXISTS power.meters (ts TIMESTAMP, current FLOAT, voltage INT, phase FLOAT) TAGS (groupId INT, location BINARY(24))");}}
}
示例程序
场景设计
下面的示例程序展示了如何高效写入数据,场景设计如下:
- TDengine 客户端程序从其它数据源不断读入数据,在示例程序中采用生成模拟数据的方式来模拟读取数据源,同时提供了从 Kafka 拉取数据写入 TDengine 的示例。
- 为了提高 TDengine 客户端程序读取数据速度,使用多线程读取。为了避免乱序,多个读取线程读取数据对应的表集合应该不重叠。
- 为了与每个数据读取线程读取数据的速度相匹配,后台启用一组写入线程与之对应,每个写入线程都有一个独占的固定大小的消息队列。
示例代码
这一部分是针对以上场景的示例代码。对于其它场景高效写入原理相同,不过代码需要适当修改。
本示例代码假设源数据属于同一张超级表(meters)的不同子表。程序在开始写入数据之前已经在 test 库创建了这个超级表,以及对应的子表。如果实际场景是多个超级表,只需按需创建多个超级表和启动多组任务。
程序清单
| 类名 | 功能说明 |
|---|---|
| FastWriteExample | 主程序,完成命令行参数解析,线程池创建,以及等待任务完成功能 |
| WorkTask | 从模拟源中读取数据,调用 JDBC 标准接口写入 |
| MockDataSource | 模拟生成一定数量 meters 子表的数据 |
| DataBaseMonitor | 统计写入速度,并每隔 10 秒把当前写入速度打印到控制台 |
| CreateSubTableTask | 根据子表范围创建子表,供主程序调用 |
| Meters | 提供了 meters 表单条数据的序列化和反序列化,供发送消息给 Kafka 和 从 Kafka 接收消息使用 |
| ProducerTask | 生产者,向 Kafka 发送消息 |
| ConsumerTask | 消费者,从 Kafka 接收消息,调用 JDBC 高效写入接口写入 TDengine,并按进度提交 offset |
| Util | 提供一些基础功能,包括创建连接,创建 Kafka topic,统计写入条数等 |
以下是各类的完整代码和更详细的功能说明。
FastWriteExample 示例
主程序命令行参数介绍:
-b,--batchSizeByRow <arg> 指定高效写入的 batchSizeByRow 参数,默认 1000 -c,--cacheSizeByRow <arg> 指定高效写入的 cacheSizeByRow 参数,默认 10000 -d,--dbName <arg> 指定数据库名, 默认 `test` --help 打印帮助信息 -K,--useKafka 使用 Kafka,采用创建生产者发送消息,消费者接收消息写入 TDengine 方式。否则采用工作线程订阅模拟器生成数据写入 TDengine 方式 -r,--readThreadCount <arg> 指定工作线程数,默认 5,当 Kafka 模式,此参数同时决定生产者和消费者线程数 -R,--rowsPerSubTable <arg> 指定每子表写入行数,默认 100 -s,--subTableNum <arg> 指定子表总数,默认 1000000 -w,--writeThreadPerReadThread <arg> 指定每工作线程对应写入线程数,默认 5
JDBC URL 和 Kafka 集群地址配置:
- JDBC URL 通过环境变量配置,例如:
export TDENGINE_JDBC_URL="jdbc:TAOS-WS://localhost:6041?user=root&password=taosdata" - Kafka 集群地址通过环境变量配置,例如:
KAFKA_BOOTSTRAP_SERVERS=localhost:9092
使用方式:
1. 采用模拟数据写入方式:java -jar highVolume.jar -r 5 -w 5 -b 10000 -c 100000 -s 1000000 -R 1000
2. 采用 Kafka 订阅写入方式:java -jar highVolume.jar -r 5 -w 5 -b 10000 -c 100000 -s 1000000 -R 100 -K
主程序负责:
- 解析命令行参数
- 创建子表
- 创建工作线程或 Kafka 生产者,消费者
- 统计写入速度
- 等待写入结束,释放资源
示例源码:
package com.taos.example.highvolume;import org.apache.commons.cli.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.atomic.AtomicInteger;public class FastWriteExample {static final Logger logger = LoggerFactory.getLogger(FastWriteExample.class);static ThreadPoolExecutor writerThreads;static ThreadPoolExecutor producerThreads;static final ThreadPoolExecutor statThread = (ThreadPoolExecutor) Executors.newFixedThreadPool(1);private static final List<Stoppable> allTasks = new ArrayList<>();private static int readThreadCount = 5;private static int writeThreadPerReadThread = 5;private static int batchSizeByRow = 1000;private static int cacheSizeByRow = 10000;private static int subTableNum = 1000000;private static int rowsPerSubTable = 100;private static String dbName = "test";public static void forceStopAll() {logger.info("shutting down");for (Stoppable task : allTasks) {task.stop();}if (producerThreads != null) {producerThreads.shutdown();}if (writerThreads != null) {writerThreads.shutdown();}statThread.shutdown();}private static void createSubTables(){writerThreads = (ThreadPoolExecutor) Executors.newFixedThreadPool(readThreadCount, getNamedThreadFactory("FW-CreateSubTable-thread-"));int range = (subTableNum + readThreadCount - 1) / readThreadCount;for (int i = 0; i < readThreadCount; i++) {int startIndex = i * range;int endIndex;if (i == readThreadCount - 1) {endIndex = subTableNum - 1;} else {endIndex = startIndex + range - 1;}logger.debug("create sub table task {} {} {}", i, startIndex, endIndex);CreateSubTableTask createSubTableTask = new CreateSubTableTask(i,startIndex,endIndex,dbName);writerThreads.submit(createSubTableTask);}logger.info("create sub table task started.");while (writerThreads.getActiveCount() != 0) {try {Thread.sleep(1);} catch (InterruptedException ignored) {Thread.currentThread().interrupt();}}logger.info("create sub table task finished.");}public static void startStatTask() throws SQLException {StatTask statTask = new StatTask(dbName, subTableNum);allTasks.add(statTask);statThread.submit(statTask);}public static ThreadFactory getNamedThreadFactory(String namePrefix) {return new ThreadFactory() {private final AtomicInteger threadNumber = new AtomicInteger(1);@Overridepublic Thread newThread(Runnable r) {return new Thread(r, namePrefix + threadNumber.getAndIncrement());}};}private static void invokeKafkaDemo() throws SQLException {producerThreads = (ThreadPoolExecutor) Executors.newFixedThreadPool(readThreadCount, getNamedThreadFactory("FW-kafka-producer-thread-"));writerThreads = (ThreadPoolExecutor) Executors.newFixedThreadPool(readThreadCount, getNamedThreadFactory("FW-kafka-consumer-thread-"));int range = (subTableNum + readThreadCount - 1) / readThreadCount;for (int i = 0; i < readThreadCount; i++) {int startIndex = i * range;int endIndex;if (i == readThreadCount - 1) {endIndex = subTableNum - 1;} else {endIndex = startIndex + range - 1;}ProducerTask producerTask = new ProducerTask(i,rowsPerSubTable,startIndex,endIndex);allTasks.add(producerTask);producerThreads.submit(producerTask);ConsumerTask consumerTask = new ConsumerTask(i,writeThreadPerReadThread,batchSizeByRow,cacheSizeByRow,dbName);allTasks.add(consumerTask);writerThreads.submit(consumerTask);}startStatTask();Runtime.getRuntime().addShutdownHook(new Thread(FastWriteExample::forceStopAll));while (writerThreads.getActiveCount() != 0) {try {Thread.sleep(10);} catch (InterruptedException ignored) {Thread.currentThread().interrupt();}}}private static void invokeMockDataDemo() throws SQLException {ThreadFactory namedThreadFactory = new ThreadFactory() {private final AtomicInteger threadNumber = new AtomicInteger(1);private final String namePrefix = "FW-work-thread-";@Overridepublic Thread newThread(Runnable r) {return new Thread(r, namePrefix + threadNumber.getAndIncrement());}};writerThreads = (ThreadPoolExecutor) Executors.newFixedThreadPool(readThreadCount, namedThreadFactory);int range = (subTableNum + readThreadCount - 1) / readThreadCount;for (int i = 0; i < readThreadCount; i++) {int startIndex = i * range;int endIndex;if (i == readThreadCount - 1) {endIndex = subTableNum - 1;} else {endIndex = startIndex + range - 1;}WorkTask task = new WorkTask(i,writeThreadPerReadThread,batchSizeByRow,cacheSizeByRow,rowsPerSubTable,startIndex,endIndex,dbName);allTasks.add(task);writerThreads.submit(task);}startStatTask();Runtime.getRuntime().addShutdownHook(new Thread(FastWriteExample::forceStopAll));while (writerThreads.getActiveCount() != 0) {try {Thread.sleep(10);} catch (InterruptedException ignored) {Thread.currentThread().interrupt();}}}// print helpprivate static void printHelp(Options options) {HelpFormatter formatter = new HelpFormatter();formatter.printHelp("java -jar highVolume.jar", options);System.out.println();}public static void main(String[] args) throws SQLException, InterruptedException {Options options = new Options();Option readThdcountOption = new Option("r", "readThreadCount", true, "Specify the readThreadCount, default is 5");readThdcountOption.setRequired(false);options.addOption(readThdcountOption);Option writeThdcountOption = new Option("w", "writeThreadPerReadThread", true, "Specify the writeThreadPerReadThread, default is 5");writeThdcountOption.setRequired(false);options.addOption(writeThdcountOption);Option batchSizeOption = new Option("b", "batchSizeByRow", true, "Specify the batchSizeByRow, default is 1000");batchSizeOption.setRequired(false);options.addOption(batchSizeOption);Option cacheSizeOption = new Option("c", "cacheSizeByRow", true, "Specify the cacheSizeByRow, default is 10000");cacheSizeOption.setRequired(false);options.addOption(cacheSizeOption);Option subTablesOption = new Option("s", "subTableNum", true, "Specify the subTableNum, default is 1000000");subTablesOption.setRequired(false);options.addOption(subTablesOption);Option rowsPerTableOption = new Option("R", "rowsPerSubTable", true, "Specify the rowsPerSubTable, default is 100");rowsPerTableOption.setRequired(false);options.addOption(rowsPerTableOption);Option dbNameOption = new Option("d", "dbName", true, "Specify the database name, default is test");dbNameOption.setRequired(false);options.addOption(dbNameOption);Option kafkaOption = new Option("K", "useKafka", false, "use kafka demo to test");kafkaOption.setRequired(false);options.addOption(kafkaOption);Option helpOption = new Option(null, "help", false, "print help information");helpOption.setRequired(false);options.addOption(helpOption);CommandLineParser parser = new DefaultParser();CommandLine cmd;try {cmd = parser.parse(options, args);} catch (ParseException e) {System.out.println(e.getMessage());printHelp(options);System.exit(1);return;}if (cmd.hasOption("help")) {printHelp(options);return;}if (cmd.getOptionValue("readThreadCount") != null) {readThreadCount = Integer.parseInt(cmd.getOptionValue("readThreadCount"));if (readThreadCount <= 0){logger.error("readThreadCount must be greater than 0");return;}}if (cmd.getOptionValue("writeThreadPerReadThread") != null) {writeThreadPerReadThread = Integer.parseInt(cmd.getOptionValue("writeThreadPerReadThread"));if (writeThreadPerReadThread <= 0){logger.error("writeThreadPerReadThread must be greater than 0");return;}}if (cmd.getOptionValue("batchSizeByRow") != null) {batchSizeByRow = Integer.parseInt(cmd.getOptionValue("batchSizeByRow"));if (batchSizeByRow <= 0){logger.error("batchSizeByRow must be greater than 0");return;}}if (cmd.getOptionValue("cacheSizeByRow") != null) {cacheSizeByRow = Integer.parseInt(cmd.getOptionValue("cacheSizeByRow"));if (cacheSizeByRow <= 0){logger.error("cacheSizeByRow must be greater than 0");return;}}if (cmd.getOptionValue("subTableNum") != null) {subTableNum = Integer.parseInt(cmd.getOptionValue("subTableNum"));if (subTableNum <= 0){logger.error("subTableNum must be greater than 0");return;}}if (cmd.getOptionValue("rowsPerSubTable") != null) {rowsPerSubTable = Integer.parseInt(cmd.getOptionValue("rowsPerSubTable"));if (rowsPerSubTable <= 0){logger.error("rowsPerSubTable must be greater than 0");return;}}if (cmd.getOptionValue("dbName") != null) {dbName = cmd.getOptionValue("dbName");}logger.info("readThreadCount={}, writeThreadPerReadThread={} batchSizeByRow={} cacheSizeByRow={}, subTableNum={}, rowsPerSubTable={}",readThreadCount, writeThreadPerReadThread, batchSizeByRow, cacheSizeByRow, subTableNum, rowsPerSubTable);logger.info("create database begin.");Util.prepareDatabase(dbName);logger.info("create database end.");logger.info("create sub tables start.");createSubTables();logger.info("create sub tables end.");if (cmd.hasOption("K")) {Util.createKafkaTopic();// use kafka demoinvokeKafkaDemo();} else {// use mock data source demoinvokeMockDataDemo();}}
}
WorkTask 示例
工作线程负责从模拟数据源读数据。每个读任务都关联了一个模拟数据源。每个模拟数据源可生成某个子表区间的数据。不同的模拟数据源生成不同表的数据。
工作线程采用阻塞的方式调用 JDBC 标准接口 addBatch。也就是说,一旦对应高效写入后端队列满了,写操作就会阻塞。
package com.taos.example.highvolume;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.sql.Connection;
import java.sql.PreparedStatement;
import java.util.Iterator;class WorkTask implements Runnable, Stoppable {private static final Logger logger = LoggerFactory.getLogger(WorkTask.class);private final int taskId;private final int writeThreadCount;private final int batchSizeByRow;private final int cacheSizeByRow;private final int rowsPerTable;private final int subTableStartIndex;private final int subTableEndIndex;private final String dbName;private volatile boolean active = true;public WorkTask(int taskId,int writeThradCount,int batchSizeByRow,int cacheSizeByRow,int rowsPerTable,int subTableStartIndex,int subTableEndIndex,String dbName) {this.taskId = taskId;this.writeThreadCount = writeThradCount;this.batchSizeByRow = batchSizeByRow;this.cacheSizeByRow = cacheSizeByRow;this.rowsPerTable = rowsPerTable;this.subTableStartIndex = subTableStartIndex; // for this task, the start index of sub tablethis.subTableEndIndex = subTableEndIndex; // for this task, the end index of sub tablethis.dbName = dbName;}@Overridepublic void run() {logger.info("task {} started", taskId);Iterator<Meters> it = new MockDataSource(subTableStartIndex, subTableEndIndex, rowsPerTable);try (Connection connection = Util.getConnection(batchSizeByRow, cacheSizeByRow, writeThreadCount);PreparedStatement pstmt = connection.prepareStatement("INSERT INTO " + dbName +".meters (tbname, ts, current, voltage, phase) VALUES (?,?,?,?,?)")) {long i = 0L;while (it.hasNext() && active) {i++;Meters meters = it.next();pstmt.setString(1, meters.getTableName());pstmt.setTimestamp(2, meters.getTs());pstmt.setFloat(3, meters.getCurrent());pstmt.setInt(4, meters.getVoltage());pstmt.setFloat(5, meters.getPhase());pstmt.addBatch();if (i % batchSizeByRow == 0) {pstmt.executeBatch();}if (i % (10L * batchSizeByRow) == 0){pstmt.executeUpdate();}}} catch (Exception e) {logger.error("Work Task {} Error", taskId, e);}logger.info("task {} stopped", taskId);}public void stop() {logger.info("task {} stopping", taskId);this.active = false;}
}
MockDataSource 示例
模拟数据生成器,生成一定子表范围的数据。为了模拟真实情况,采用轮流每个子表一条数据的生成方式。
package com.taos.example.highvolume;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.util.Iterator;
import java.util.Random;
import java.util.concurrent.ThreadLocalRandom;/*** Generate test data*/
class MockDataSource implements Iterator<Meters> {private final static Logger logger = LoggerFactory.getLogger(MockDataSource.class);private final int tableStartIndex;private final int tableEndIndex;private final long maxRowsPerTable;long currentMs = System.currentTimeMillis();private int index = 0;// mock valuespublic MockDataSource(int tableStartIndex, int tableEndIndex, int maxRowsPerTable) {this.tableStartIndex = tableStartIndex;this.tableEndIndex = tableEndIndex;this.maxRowsPerTable = maxRowsPerTable;}@Overridepublic boolean hasNext() {return index < (tableEndIndex - tableStartIndex + 1) * maxRowsPerTable;}@Overridepublic Meters next() {// use interlace rows to simulate the data distribution in real worldif (index % (tableEndIndex - tableStartIndex + 1) == 0) {currentMs += 1000;}long currentTbId = index % (tableEndIndex - tableStartIndex + 1) + tableStartIndex;Meters meters = new Meters();meters.setTableName(Util.getTableNamePrefix() + currentTbId);meters.setTs(new java.sql.Timestamp(currentMs));meters.setCurrent((float) (Math.random() * 100));meters.setVoltage(ThreadLocalRandom.current().nextInt());meters.setPhase((float) (Math.random() * 100));index ++;return meters;}
}CreateSubTableTask 示例
根据子表范围创建子表,采用批量拼 sql 创建方式。
package com.taos.example.highvolume;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;class CreateSubTableTask implements Runnable {private static final Logger logger = LoggerFactory.getLogger(CreateSubTableTask.class);private final int taskId;private final int subTableStartIndex;private final int subTableEndIndex;private final String dbName;public CreateSubTableTask(int taskId,int subTableStartIndex,int subTableEndIndex,String dbName) {this.taskId = taskId;this.subTableStartIndex = subTableStartIndex;this.subTableEndIndex = subTableEndIndex;this.dbName = dbName;}@Overridepublic void run() {try (Connection connection = Util.getConnection();Statement statement = connection.createStatement()){statement.execute("use " + dbName);StringBuilder sql = new StringBuilder();sql.append("create table");int i = 0;for (int tableNum = subTableStartIndex; tableNum <= subTableEndIndex; tableNum++) {sql.append(" if not exists " + Util.getTableNamePrefix() + tableNum + " using meters" + " tags(" + tableNum + ", " + "\"location_" + tableNum + "\"" + ")");if (i < 1000) {i++;} else {statement.execute(sql.toString());sql = new StringBuilder();sql.append("create table");i = 0;}}if (sql.length() > "create table".length()) {statement.execute(sql.toString());}} catch (SQLException e) {logger.error("task id {}, failed to create sub table", taskId, e);}}}
Meters 示例
数据模型类,提供了发送到 Kafka 的序列化和反序列化方法。
package com.taos.example.highvolume;import java.sql.Timestamp;public class Meters {String tableName;Timestamp ts;float current;int voltage;float phase;public String getTableName() {return tableName;}public void setTableName(String tableName) {this.tableName = tableName;}public Timestamp getTs() {return ts;}public void setTs(Timestamp ts) {this.ts = ts;}public float getCurrent() {return current;}public void setCurrent(float current) {this.current = current;}public int getVoltage() {return voltage;}public void setVoltage(int voltage) {this.voltage = voltage;}public float getPhase() {return phase;}public void setPhase(float phase) {this.phase = phase;}@Overridepublic String toString() {return tableName + "," +ts.toString() + "," +current + "," +voltage + "," +phase;}public static Meters fromString(String str) {String[] parts = str.split(",");if (parts.length != 5) {throw new IllegalArgumentException("Invalid input format");}Meters meters = new Meters();meters.setTableName(parts[0]);meters.setTs(Timestamp.valueOf(parts[1]));meters.setCurrent(Float.parseFloat(parts[2]));meters.setVoltage(Integer.parseInt(parts[3]));meters.setPhase(Float.parseFloat(parts[4]));return meters;}}ProducerTask 示例
消息生产者,采用与 JDBC 高效写入不同的 Hash 方式,将模拟数据生成器生成的数据,写入所有分区。
package com.taos.example.highvolume;import com.taosdata.jdbc.utils.ReqId;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.util.Iterator;
import java.util.Properties;class ProducerTask implements Runnable, Stoppable {private final static Logger logger = LoggerFactory.getLogger(ProducerTask.class);private final int taskId;private final int subTableStartIndex;private final int subTableEndIndex;private final int rowsPerTable;private volatile boolean active = true;public ProducerTask(int taskId,int rowsPerTable,int subTableStartIndex,int subTableEndIndex) {this.taskId = taskId;this.subTableStartIndex = subTableStartIndex;this.subTableEndIndex = subTableEndIndex;this.rowsPerTable = rowsPerTable;}@Overridepublic void run() {logger.info("kafak producer {}, started", taskId);Iterator<Meters> it = new MockDataSource(subTableStartIndex, subTableEndIndex, rowsPerTable);Properties props = new Properties();props.put("bootstrap.servers", Util.getKafkaBootstrapServers());props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("batch.size", 1024 * 1024);props.put("linger.ms", 500);// create a Kafka producerKafkaProducer<String, String> producer = new KafkaProducer<>(props);try {while (it.hasNext() && active) {Meters meters = it.next();String key = meters.getTableName();String value = meters.toString();// to avoid the data of the sub-table out of order. we use the partition key to ensure the data of the same sub-table is sent to the same partition.// Because efficient writing use String hashcode,here we use another hash algorithm to calculate the partition key.long hashCode = Math.abs(ReqId.murmurHash32(key.getBytes(), 0));ProducerRecord<String, String> metersRecord = new ProducerRecord<>(Util.getKafkaTopic(), (int)(hashCode % Util.getPartitionCount()), key, value);producer.send(metersRecord);}} catch (Exception e) {logger.error("task id {}, send message error: ", taskId, e);}finally {producer.close();}logger.info("kafka producer {} stopped", taskId);}public void stop() {logger.info("kafka producer {} stopping", taskId);this.active = false;}
}
ConsumerTask 示例
消息消费者,从 Kafka 接收消息,写入 TDengine。
package com.taos.example.highvolume;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.sql.Connection;
import java.sql.PreparedStatement;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;class ConsumerTask implements Runnable, Stoppable {private static final Logger logger = LoggerFactory.getLogger(ConsumerTask.class);private final int taskId;private final int writeThreadCount;private final int batchSizeByRow;private final int cacheSizeByRow;private final String dbName;private volatile boolean active = true;public ConsumerTask(int taskId,int writeThreadCount,int batchSizeByRow,int cacheSizeByRow,String dbName) {this.taskId = taskId;this.writeThreadCount = writeThreadCount;this.batchSizeByRow = batchSizeByRow;this.cacheSizeByRow = cacheSizeByRow;this.dbName = dbName;}@Overridepublic void run() {logger.info("Consumer Task {} started", taskId);Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, Util.getKafkaBootstrapServers());props.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group");props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, String.valueOf(batchSizeByRow));props.put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG, "3000");props.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, String.valueOf(2 * 1024 * 1024));props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, "15000");props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "60000");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);List<String> topics = Collections.singletonList(Util.getKafkaTopic());try {consumer.subscribe(topics);} catch (Exception e) {logger.error("Consumer Task {} Error", taskId, e);return;}try (Connection connection = Util.getConnection(batchSizeByRow, cacheSizeByRow, writeThreadCount);PreparedStatement pstmt = connection.prepareStatement("INSERT INTO " + dbName +".meters (tbname, ts, current, voltage, phase) VALUES (?,?,?,?,?)")) {long i = 0L;long lastTimePolled = System.currentTimeMillis();while (active) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> metersRecord : records) {i++;Meters meters = Meters.fromString(metersRecord.value());pstmt.setString(1, meters.getTableName());pstmt.setTimestamp(2, meters.getTs());pstmt.setFloat(3, meters.getCurrent());pstmt.setInt(4, meters.getVoltage());pstmt.setFloat(5, meters.getPhase());pstmt.addBatch();if (i % batchSizeByRow == 0) {pstmt.executeBatch();}if (i % (10L * batchSizeByRow) == 0){pstmt.executeUpdate();consumer.commitSync();}}if (!records.isEmpty()){lastTimePolled = System.currentTimeMillis();} else {if (System.currentTimeMillis() - lastTimePolled > 1000 * 60) {lastTimePolled = System.currentTimeMillis();logger.error("Consumer Task {} has been idle for 10 seconds, stopping", taskId);}}}} catch (Exception e) {logger.error("Consumer Task {} Error", taskId, e);} finally {consumer.close();}logger.info("Consumer Task {} stopped", taskId);}public void stop() {logger.info("consumer task {} stopping", taskId);this.active = false;}
}
StatTask 示例
提供定时统计写入条数功能
package com.taos.example.highvolume;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;class StatTask implements Runnable, Stoppable {private final static Logger logger = LoggerFactory.getLogger(StatTask.class);private final int subTableNum;private final String dbName;private final Connection conn;private final Statement stmt;private volatile boolean active = true;public StatTask(String dbName,int subTableNum) throws SQLException {this.dbName = dbName;this.subTableNum = subTableNum;this.conn = Util.getConnection();this.stmt = conn.createStatement();}@Overridepublic void run() {long lastCount = 0;while (active) {try {Thread.sleep(10000);long count = Util.count(stmt, dbName);logger.info("numberOfTable={} count={} speed={}", subTableNum, count, (count - lastCount) / 10);lastCount = count;} catch (InterruptedException e) {logger.error("interrupted", e);break;} catch (SQLException e) {logger.error("execute sql error: ", e);break;}}try {stmt.close();conn.close();} catch (SQLException e) {logger.error("close connection error: ", e);}}public void stop() {active = false;}}
Util 模块示例
工具类,提供连接创建,数据库创建和 topic 创建等功能。
package com.taos.example.highvolume;import com.taosdata.jdbc.TSDBDriver;import java.sql.*;
import java.util.Properties;import org.apache.kafka.clients.admin.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.util.*;
import java.util.concurrent.ExecutionException;public class Util {private final static Logger logger = LoggerFactory.getLogger(Util.class);public static String getTableNamePrefix() {return "d_";}public static Connection getConnection() throws SQLException {String jdbcURL = System.getenv("TDENGINE_JDBC_URL");if (jdbcURL == null || jdbcURL == "") {jdbcURL = "jdbc:TAOS-WS://localhost:6041/?user=root&password=taosdata";}return DriverManager.getConnection(jdbcURL);}public static Connection getConnection(int batchSize, int cacheSize, int writeThreadNum) throws SQLException {String jdbcURL = System.getenv("TDENGINE_JDBC_URL");if (jdbcURL == null || jdbcURL == "") {jdbcURL = "jdbc:TAOS-WS://localhost:6041/?user=root&password=taosdata";}Properties properties = new Properties();properties.setProperty(TSDBDriver.PROPERTY_KEY_ASYNC_WRITE, "stmt");properties.setProperty(TSDBDriver.PROPERTY_KEY_BATCH_SIZE_BY_ROW, String.valueOf(batchSize));properties.setProperty(TSDBDriver.PROPERTY_KEY_CACHE_SIZE_BY_ROW, String.valueOf(cacheSize));properties.setProperty(TSDBDriver.PROPERTY_KEY_BACKEND_WRITE_THREAD_NUM, String.valueOf(writeThreadNum));properties.setProperty(TSDBDriver.PROPERTY_KEY_ENABLE_AUTO_RECONNECT, "true");return DriverManager.getConnection(jdbcURL, properties);}public static void prepareDatabase(String dbName) throws SQLException {try (Connection conn = Util.getConnection();Statement stmt = conn.createStatement()) {stmt.execute("DROP DATABASE IF EXISTS " + dbName);stmt.execute("CREATE DATABASE IF NOT EXISTS " + dbName + " vgroups 20");stmt.execute("use " + dbName);stmt.execute("CREATE STABLE " + dbName+ ".meters (ts TIMESTAMP, current FLOAT, voltage INT, phase FLOAT) TAGS (groupId INT, location BINARY(64))");}}public static long count(Statement stmt, String dbName) throws SQLException {try (ResultSet result = stmt.executeQuery("SELECT count(*) from " + dbName + ".meters")) {result.next();return result.getLong(1);}}public static String getKafkaBootstrapServers() {String kafkaBootstrapServers = System.getenv("KAFKA_BOOTSTRAP_SERVERS");if (kafkaBootstrapServers == null || kafkaBootstrapServers == "") {kafkaBootstrapServers = "localhost:9092";}return kafkaBootstrapServers;}public static String getKafkaTopic() {return "test-meters-topic";}public static void createKafkaTopic() {Properties config = new Properties();config.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, getKafkaBootstrapServers());try (AdminClient adminClient = AdminClient.create(config)) {String topicName = getKafkaTopic();int numPartitions = getPartitionCount();short replicationFactor = 1;ListTopicsResult topics = adminClient.listTopics();Set<String> existingTopics = topics.names().get();if (!existingTopics.contains(topicName)) {NewTopic newTopic = new NewTopic(topicName, numPartitions, replicationFactor);CreateTopicsResult createTopicsResult = adminClient.createTopics(Collections.singleton(newTopic));createTopicsResult.all().get();logger.info("Topic " + topicName + " created successfully.");}} catch (InterruptedException | ExecutionException e) {logger.error("Failed to delete/create topic: " + e.getMessage());throw new RuntimeException(e);}}public static int getPartitionCount() {return 5;}}执行步骤
执行 Java 示例程序
本地集成开发环境执行示例程序
- clone TDengine 仓库
git clone git@github.com:taosdata/TDengine.git --depth 1 - 用集成开发环境打开
TDengine/docs/examples/JDBC/highvolume目录。 - 在开发环境中配置环境变量
TDENGINE_JDBC_URL。如果已配置了全局的环境变量TDENGINE_JDBC_URL可跳过这一步。 - 如果要运行 Kafka 示例,需要设置 Kafka 集群地址的环境变量
KAFKA_BOOTSTRAP_SERVERS。 - 指定命令行参数,如
-r 3 -w 3 -b 100 -c 1000 -s 1000 -R 100 - 运行类
com.taos.example.highvolume.FastWriteExample。
远程服务器上执行示例程序
若要在服务器上执行示例程序,可按照下面的步骤操作:
-
打包示例代码。在目录
TDengine/docs/examples/JDBC/highvolume下执行下面命令来生成highVolume.jar:mvn package -
复制程序到服务器指定目录:
scp -r .\target\highVolume.jar <user>@<host>:~/dest-path -
配置环境变量。
编辑~/.bash_profile或~/.bashrc添加如下内容例如:export TDENGINE_JDBC_URL="jdbc:TAOS-WS://localhost:6041?user=root&password=taosdata"以上使用的是本地部署 TDengine Server 时默认的 JDBC URL。你需要根据自己的实际情况更改。
如果想使用 Kafka 订阅模式,请再增加 Kafaka 集群环境变量配置:export KAFKA_BOOTSTRAP_SERVERS=localhost:9092 -
用 Java 命令启动示例程序,命令模板(如果用 Kafaka 订阅模式,最后可以加上
-K):java -jar highVolume.jar -r 5 -w 5 -b 10000 -c 100000 -s 1000000 -R 1000 -
结束测试程序。测试程序不会自动结束,在获取到当前配置下稳定的写入速度后,按 CTRL + C 结束程序。
下面是一次实际运行的日志输出,机器配置 40 核 + 256G + 固态硬盘。---------------$ java -jar highVolume.jar -r 2 -w 10 -b 10000 -c 100000 -s 1000000 -R 100 [INFO ] 2025-03-24 18:03:17.980 com.taos.example.highvolume.FastWriteExample main 309 main readThreadCount=2, writeThreadPerReadThread=10 batchSizeByRow=10000 cacheSizeByRow=100000, subTableNum=1000000, rowsPerSubTable=100 [INFO ] 2025-03-24 18:03:17.983 com.taos.example.highvolume.FastWriteExample main 312 main create database begin. [INFO ] 2025-03-24 18:03:34.499 com.taos.example.highvolume.FastWriteExample main 315 main create database end. [INFO ] 2025-03-24 18:03:34.500 com.taos.example.highvolume.FastWriteExample main 317 main create sub tables start. [INFO ] 2025-03-24 18:03:34.502 com.taos.example.highvolume.FastWriteExample createSubTables 73 main create sub table task started. [INFO ] 2025-03-24 18:03:55.777 com.taos.example.highvolume.FastWriteExample createSubTables 82 main create sub table task finished. [INFO ] 2025-03-24 18:03:55.778 com.taos.example.highvolume.FastWriteExample main 319 main create sub tables end. [INFO ] 2025-03-24 18:03:55.781 com.taos.example.highvolume.WorkTask run 41 FW-work-thread-2 started [INFO ] 2025-03-24 18:03:55.781 com.taos.example.highvolume.WorkTask run 41 FW-work-thread-1 started [INFO ] 2025-03-24 18:04:06.580 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=12235906 speed=1223590 [INFO ] 2025-03-24 18:04:17.531 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=31185614 speed=1894970 [INFO ] 2025-03-24 18:04:28.490 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=51464904 speed=2027929 [INFO ] 2025-03-24 18:04:40.851 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=71498113 speed=2003320 [INFO ] 2025-03-24 18:04:51.948 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=91242103 speed=1974399
写入性能关键要素
客户端程序方面
从客户端程序的角度来说,高效写入数据要考虑以下几个因素:
- 批量写入:通常情况下,每批次写入的数据量越大越高效(但超过一定阈值其优势会消失)。使用 SQL 写入 TDengine 时,尽量在单条 SQL 中拼接更多数据。当前,TDengine 支持的单条 SQL 最大长度为 1MB(1,048,576 字符)。
- 多线程写入:在系统资源未达瓶颈前,写入线程数增加可提升吞吐量(超过阈值后性能可能因服务端处理能力限制而下降)。推荐为每个写入线程分配独立连接,以减少连接资源的竞争。
- 写入相邻性:数据在不同表(或子表)之间的分布,即要写入数据的相邻性。一般来说,每批次只向同一张表(或子表)写入数据比向多张表(或子表)写入数据要更高效。
- 提前建表:提前建表可以提高写入性能,因为后续不需要检查表是否存在,且写入时可以不传标签列的数据,提高性能。
- 写入方式:
- 参数绑定写入比 SQL 写入更高效。因参数绑定方式避免了 SQL 解析。
- SQL 写入不自动建表比自动建表更高效。因自动建表要频繁检查表是否存在。
- SQL 写入比无模式写入更高效。因无模式写入会自动建表且支持动态更改表结构。
- 避免乱序:相同子表的数据需按时间戳升序提交。乱序数据会导致服务端执行额外的排序操作,影响写入性能。
- 开启压缩:当网络带宽成为瓶颈,或写入数据存在大量重复时,启用压缩可有效提升整体性能。
客户端程序要充分且恰当地利用以上几个因素。比如选择参数绑定写入方式,提前建好子表,在单次写入中尽量只向同一张表(或子表)写入数据,每批次写入的数据量和并发写入的线程数经过测试和调优后设定为一个最适合当前系统处理能力的数值,一般可以实现在当前系统中的最佳写入速度。
数据源方面
客户端程序通常需要从数据源读取数据再写入 TDengine。从数据源角度来说,以下几种情况需要在读线程和写线程之间增加队列:
- 有多个数据源,单个数据源生成数据的速度远小于单线程写入的速度,但数据量整体比较大。此时队列的作用是把多个数据源的数据汇聚到一起,增加单次写入的数据量。
- 单个数据源生成数据的速度远大于单线程写入的速度。此时队列的作用是增加写入的并发度。
- 单张表的数据分散在多个数据源。此时队列的作用是将同一张表的数据提前汇聚到一起,提高写入时数据的相邻性。
如果写应用的数据源是 Kafka, 写应用本身即 Kafka 的消费者,则可利用 Kafka 的特性实现高效写入。比如:
- 将同一张表的数据写到同一个 Topic 的同一个 Partition,增加数据的相邻性。
- 通过订阅多个 Topic 实现数据汇聚。
- 通过增加 Consumer 线程数增加写入的并发度。
- 通过增加每次 Fetch 的最大数据量来增加单次写入的最大数据量。
服务端配置方面
首先看数据库建库参数中的几个重要性能相关参数:
- vgroups:在服务端配置层面,创建数据库时,需综合考虑系统内磁盘数量、磁盘 I/O 能力以及处理器能力,合理设置 vgroups 数量,从而充分挖掘系统性能潜力。若 vgroups 数量过少,系统性能将难以充分释放;若数量过多,则会引发不必要的资源竞争。建议将每个 vgroup 中的表数量控制在 100 万以内,在硬件资源充足的情况下,控制在 1 万以内效果更佳。
- buffer:buffer 指的是为一个 vnode 分配的写入内存大小,默认值为 256 MB。当 vnode 中实际写入的数据量达到 buffer 大小的约 1/3 时,会触发数据落盘操作。适当调大该参数,能够尽可能多地缓存数据,实现一次性落盘,提高写入效率。然而,若参数配置过大,在系统宕机恢复时,恢复时间会相应变长。
- cachemodel:用于控制是否在内存中缓存子表的最近数据。开启此功能会对写入性能产生一定影响,因为在数据写入过程中,系统会同步检查并更新每张表的 last_row 和每列的 last 值。可通过将原选项 ‘both’ 调整为‘last_row’或‘last_value’,来减轻其对写入性能的影响。
- stt_trigger:用于控制 TSDB 数据落盘策略以及触发后台合并文件的文件个数。企业版的默认配置为 2,而开源版仅能配置为 1。当 stt_trigger = 1 时,适用于表数量少但写入频率高的场景;当 stt_trigger > 1 时,则更适合表数量多但写入频率低的场景。
其他参数请参考 数据库管理。
然后看 taosd 配置中的几个性能相关参数:
- compressMsgSize:对于带宽是瓶颈的情况,开启 rpc 消息压缩可以提升性能。
- numOfCommitThreads:服务端后台落盘线程个数,默认为 4。落盘线程数并非越多越好。线程越多,硬盘写入争抢越严重,写入性能反而可能下降。配置了多块盘的服务器可以考虑将此参数放大,从而利用多块硬盘的并发 IO 能力。
- 日志级别:以
debugFlag为代表的一批参数,控制相关日志输出级别。日志级别决定日志输出压力,开的日志级别越高,对写入性能的影响越大,一般建议默认配置。
其他参数请参考 服务端配置。
高效写入实现原理
通过上文的写入性能影响因素可知,开发高性能数据写入程序需掌握多线程编程与数据切分技术,存在一定技术门槛。为降低用户开发成本,TDengine 连接器提供高效写入特性,支持用户在不涉及底层线程管理与数据分片逻辑的前提下,充分利用 TDengine 强大的写入能力。
下面是连接器实现高效写入特性的原理图:
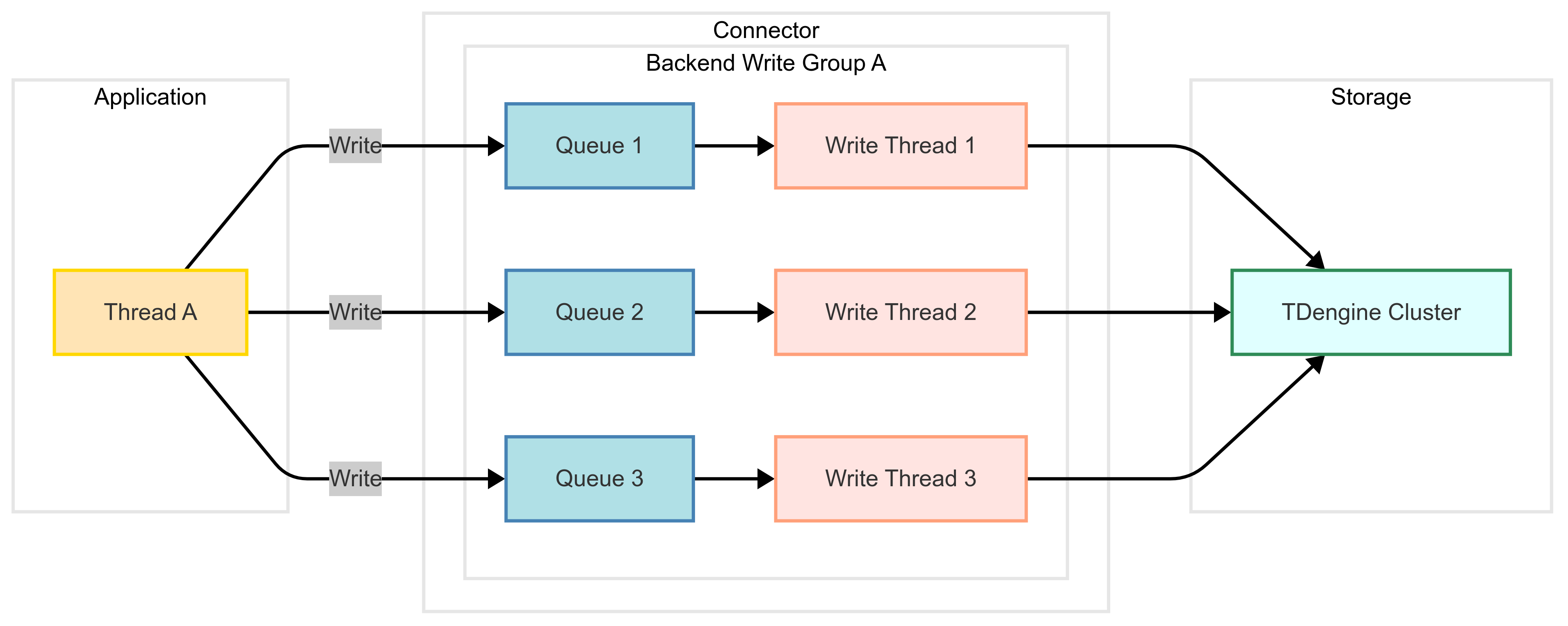
设计原理
-
自动线程与队列创建:
连接器根据配置参数动态创建独立的写入线程及对应的写入队列,每个队列与子表一一绑定,形成“子表数据 - 专属队列 - 独立线程”的处理链路。 -
数据分片与批量触发:
当应用写入数据时,连接器自动按子表维度切分数据,缓存至对应队列。当满足以下任一条件时触发批量发送:- 队列数据量达到预设阈值。
- 达到预设的等待超时时间(避免延迟过高)。
此机制通过减少网络请求次数,显著提升写入吞吐量。
功能优势
- 单线程高性能写入:
应用层只需通过单线程调用写入接口,连接器底层自动实现多线程并发处理,性能可接近传统客户端多线程写入能力,完全屏蔽底层线程管理复杂度。 - 可靠性增强机制:
- 同步校验接口:提供同步方法确保已提交数据的写入成功状态可追溯;
- 连接自愈能力:支持连接断开后的自动重连,结合超时重试策略(可配置重试次数与间隔),保障数据不丢失;
- 错误隔离设计:单个队列或线程异常不影响其他子表的数据写入,提升系统容错性。
:::note
连接器高效写入特性仅支持写入超级表,不支持写入普通表。
:::
访问官网
更多内容欢迎访问 TDengine 官网
:专项能力评测与行业垂直场景)





)