文章目录
- 1. 什么是二叉搜索树?
- 2. 二叉搜索树的性能分析
- 3. 二叉搜索树的插入
- 4. 二叉搜索树的查找
- 5. 二叉搜索树的删除
- 6. 代码实现
- 7. 二叉搜索树 key 版本和 key/value 版本
1. 什么是二叉搜索树?
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 左子树所有节点的键值 小于 当前节点的键值。
- 右子树所有节点的键值 大于 当前节点的键值。
- 左右子树也必须是二叉搜索树。
- 二叉搜索树中可以支持插入相等的值,也可以不支持插入相等的值,具体看使用场景定义,map/set/multimap/multiset 系列容器底层就是二叉搜索树,其中map/set 不支持插入相等值,multimap/multiset 支持插入相等值
2. 二叉搜索树的性能分析
| 操作 | 最佳/平均情况 | 最坏情况 | 原因 |
|---|---|---|---|
| 查找 | O(logN) | O(N)退化为链表 | 树高决定路径长度 |
| 插入 | O(logN) | O(N) | 需要找到合适位置并调整 |
| 删除 | O(logN) | O(N) | 查找+替换节点 |
| 遍历 | O(N) | O(N) | 必须访问所有节点 |
关键因素:
- 树的高度:
- 平衡BST(如AVL树、红黑树):高度为 O(log n),操作高效。
- 非平衡BST:插入有序数据(如1,2,3,4)会退化为链表,高度为 O(n),性能急剧下降。
3. 二叉搜索树的插入
- 树为空,则直接新增结点,赋值给root指针
- 树不空,按二叉搜索树性质,插入值比当前结点大往右走,插入值比当前结点小往左走,找到空位置,插入新结点。
- 如果支持插入相等的值,插入值跟当前结点相等的值可以往右走,也可以往左走,找到空位置,插入新结点。(要注意的是要保持逻辑一致性,插入相等的值不要一会往右走,一会往左走)
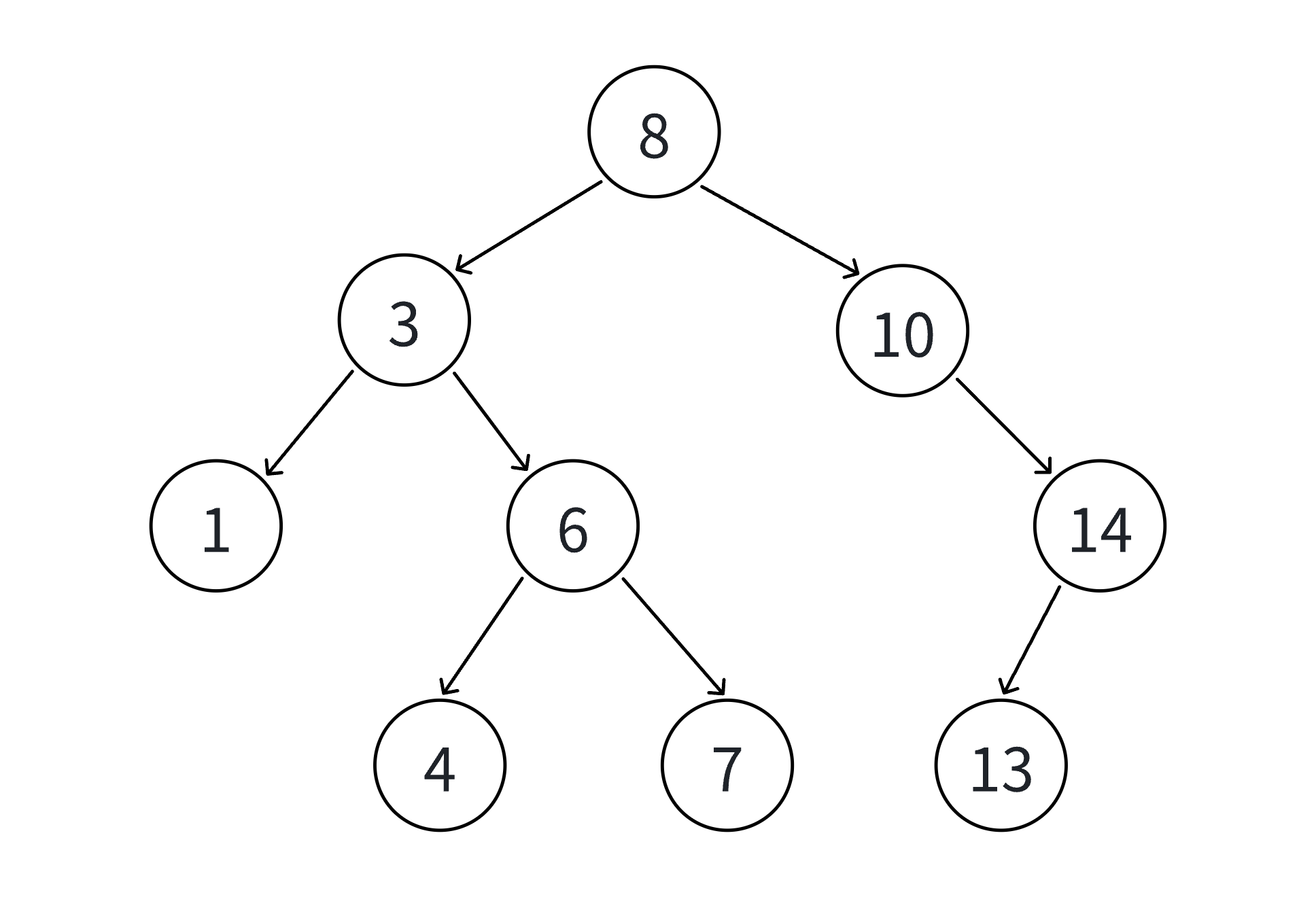
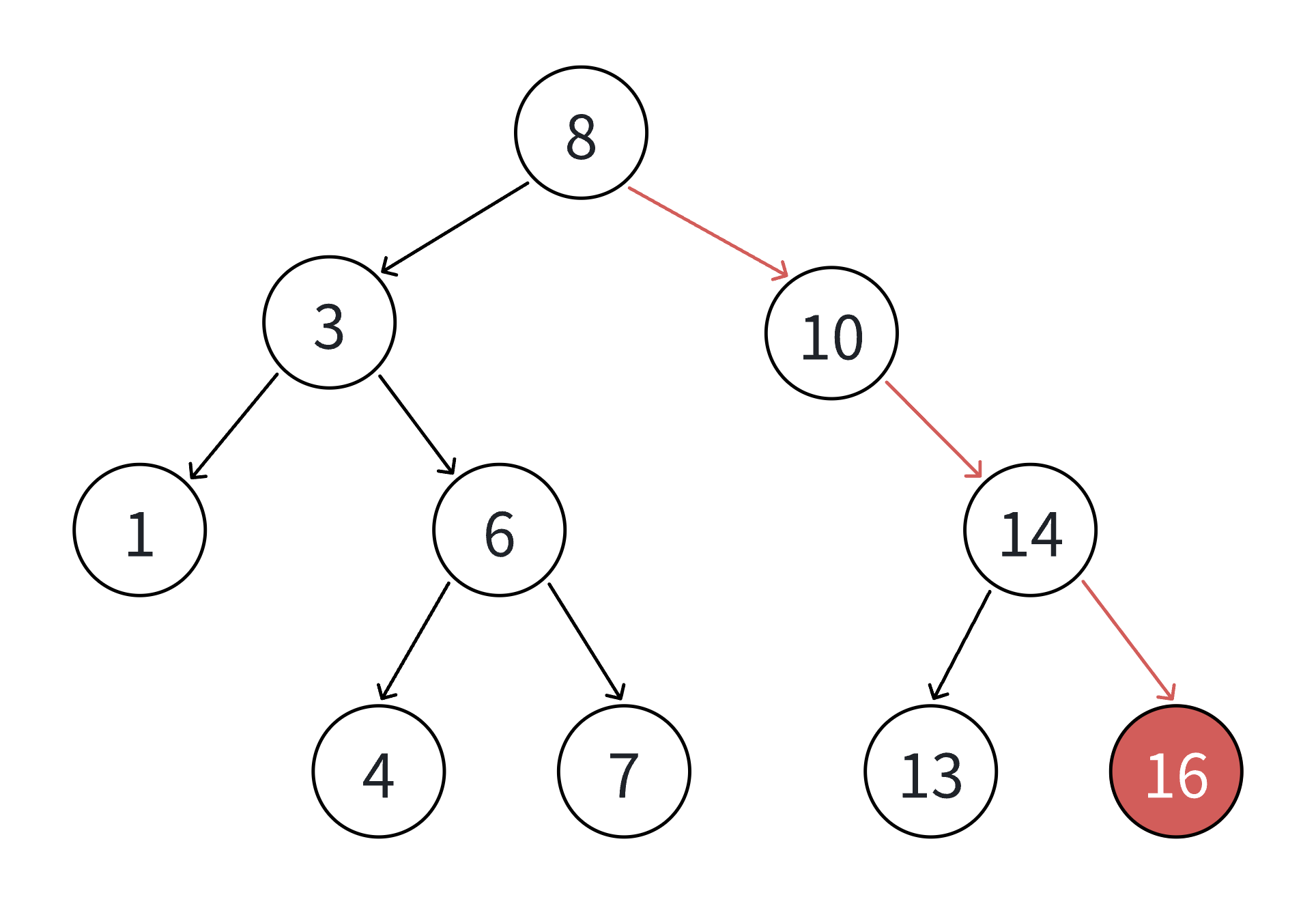
4. 二叉搜索树的查找
- 从根开始比较,查找x,x比根的值大则往右边走查找,x比根值小则往左边走查找。
- 最多查找高度次,走到到空,还没找到,这个值不存在。
- 如果不支持插入相等的值,找到x即可返回
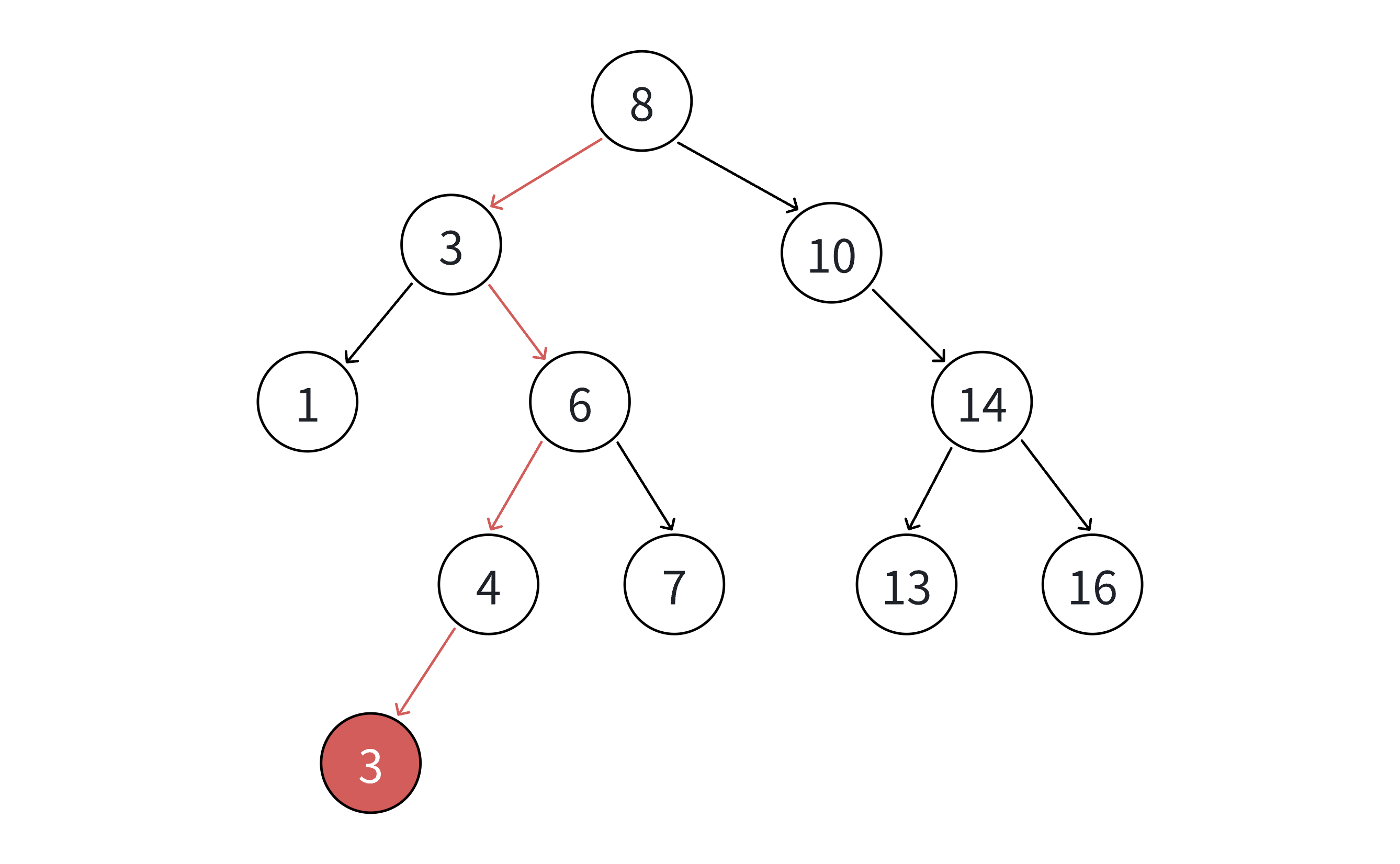
- 如果支持插入相等的值,意味着有多个x存在,一般要求查找中序的第一个x。如下图,查找3,要找到1的右孩子的那个3返回
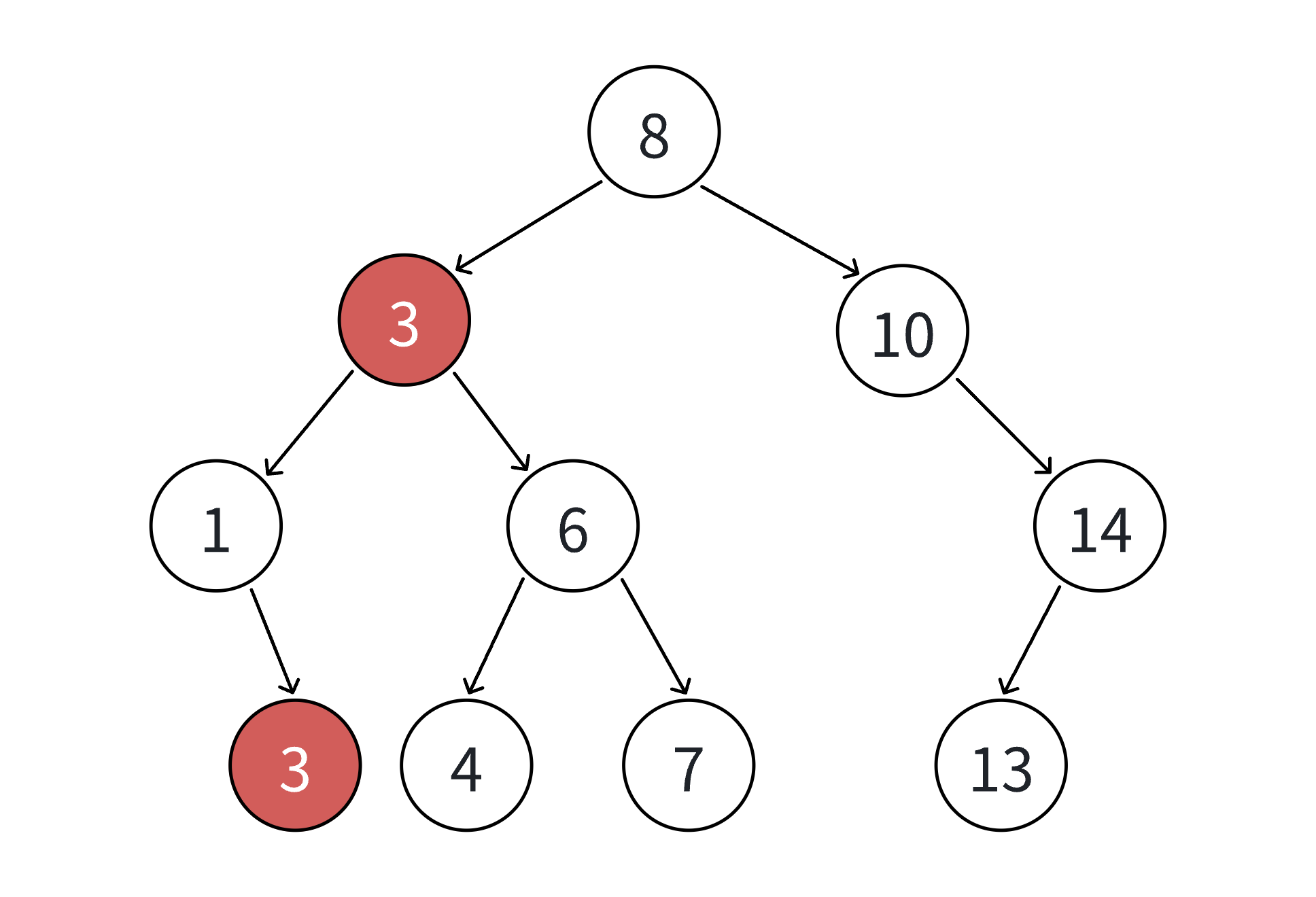
5. 二叉搜索树的删除
首先查找元素是否在二叉搜索树中,如果不存在,则返回false。
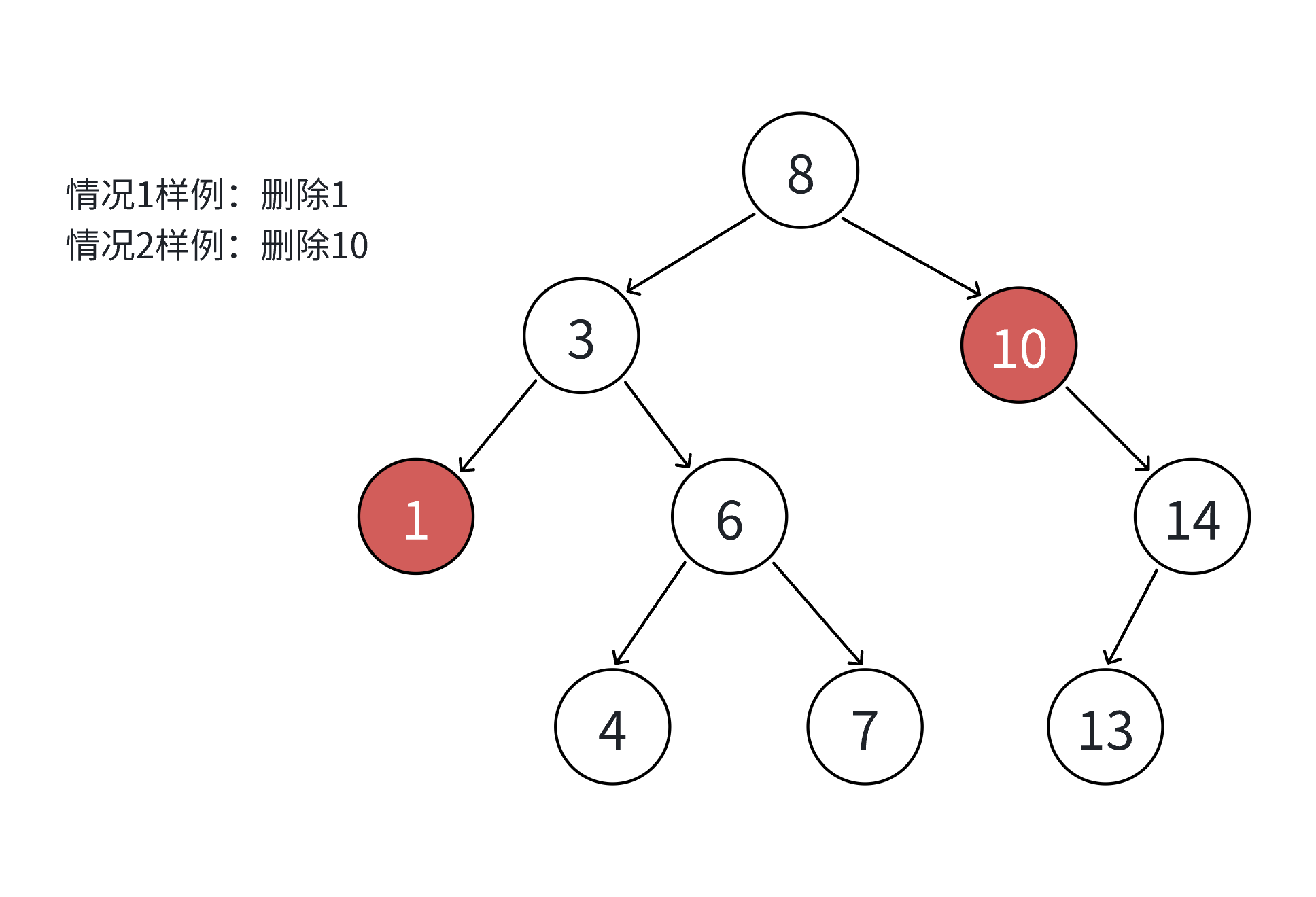
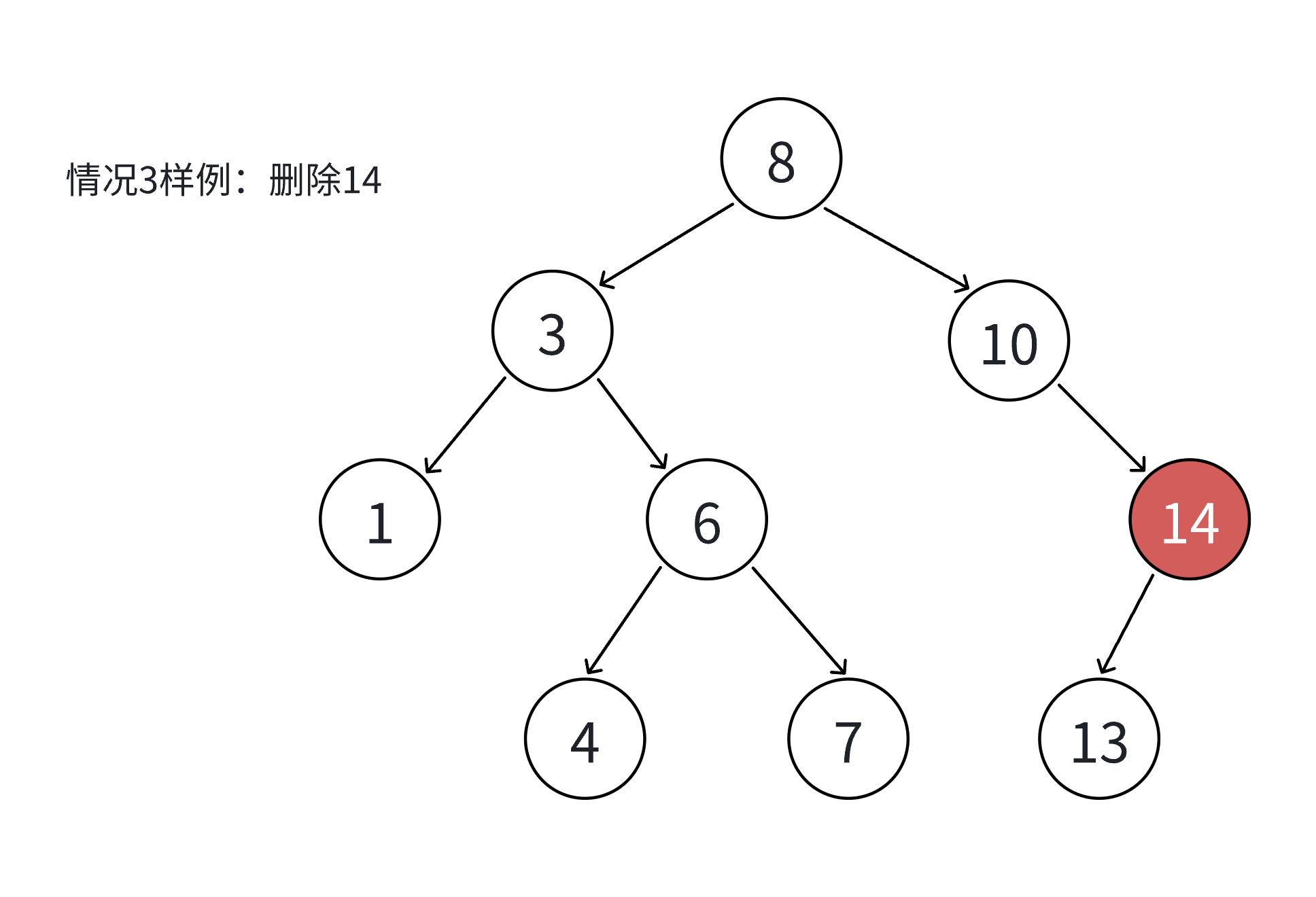
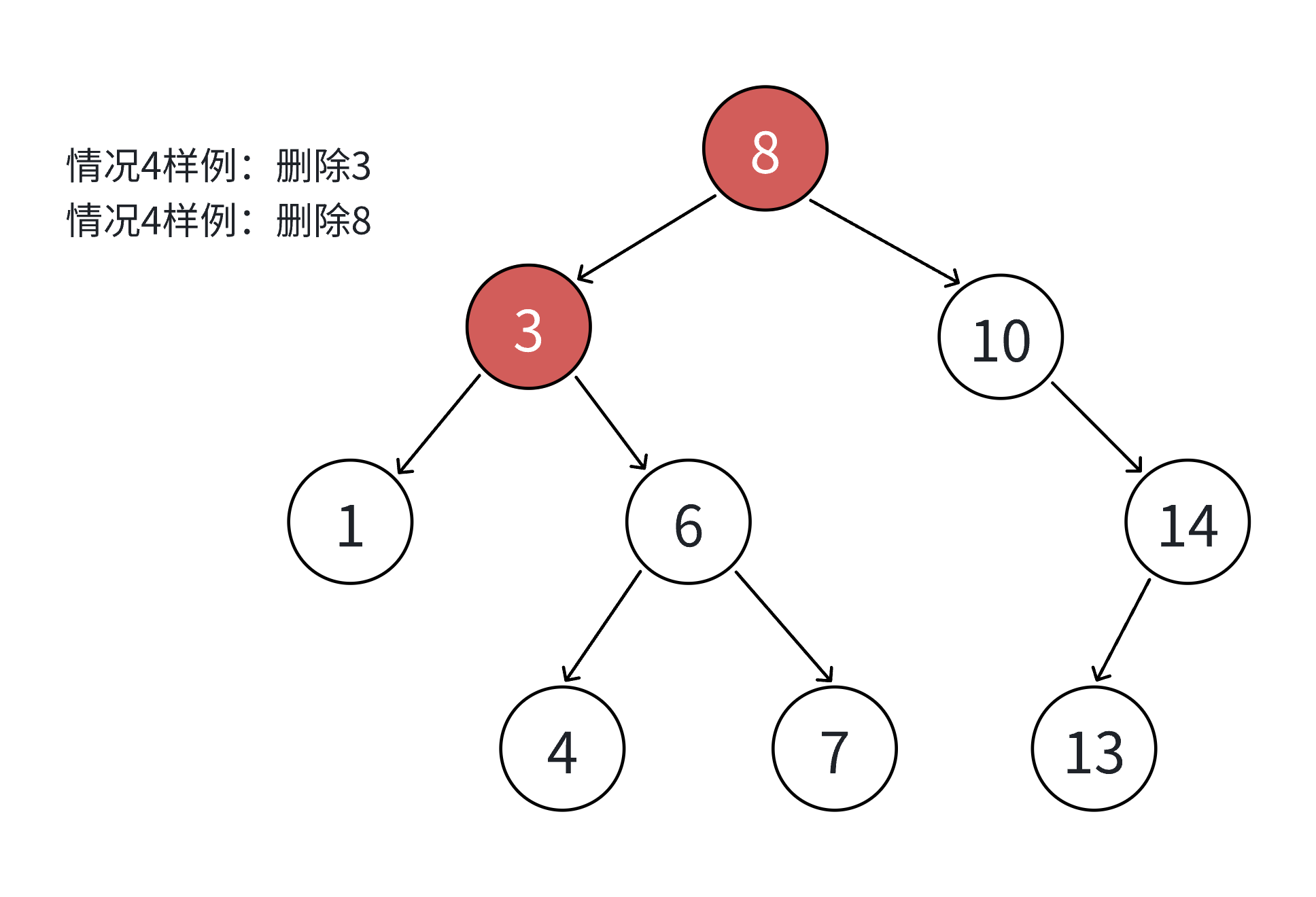
如果查找元素存在则分以下四种情况分别处理:(假设要删除的结点为N)
- 要删除结点N左右孩子均为空
- 要删除的结点N左孩子位空,右孩子结点不为空
- 要删除的结点N右孩子位空,左孩子结点不为空
- 要删除的结点N左右孩子结点均不为空
对应以上四种情况的解决方案:
5. 把N结点的父亲对应孩子指针指向空,直接删除N结点(情况1可以当成2或者3处理,效果是一样的)
6. 把N结点的父亲对应孩子指针指向N的右孩子,直接删除N结点
7. 把N结点的父亲对应孩子指针指向N的左孩子,直接删除N结点
8. 无法直接删除N结点,因为N的两个孩子无处安放,只能用替换法删除。找N左子树的值最大结点R(最右结点)或者N右子树的值最小结点R(最左结点)替代N,因为这两个结点中任意一个,放到N的位置,都满足二叉搜索树的规则。替代N的意思就是N和R的两个结点的值交换,转而变成删除R结点,R结点符合情况2或情况3,可以直接删除。
6. 代码实现
其实整体上都不难,不管是插入、查找还是删除,都是要根据二叉搜索树根节点和左右子树的关系去查找对应的位置,然后再进行操作。稍微难一点点的就是删除,但说是难一点点,其实也就是几种情况分类讨论,不清楚为什么是那几种情况的话,画图应该就可以理解了。
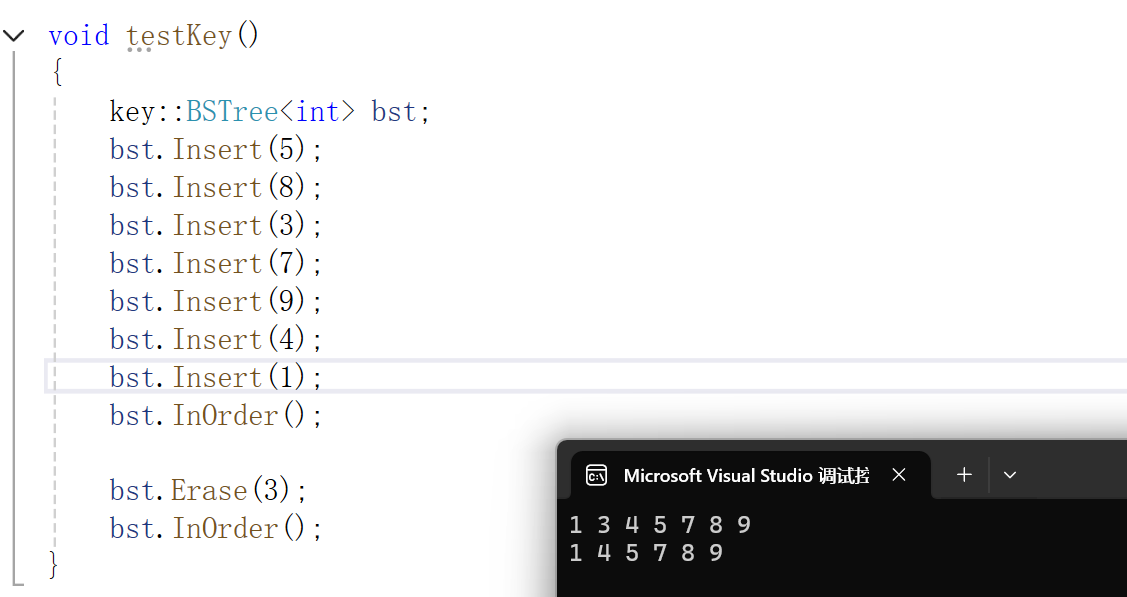
这里的实现以不能重复插入、K 版本的代码为例
#pragma once#include <iostream>
using namespace std;namespace key
{template<class K>struct BSTNode{K _key;BSTNode<K>* _left;BSTNode<K>* _right;BSTNode(const K& key):_key(key), _left(nullptr), _right(nullptr){}};template<class K>class BSTree{using Node = BSTNode<K>;public:bool Insert(const K& key){if (_root == nullptr){_root = new Node(key);return true;}Node* parent = nullptr;Node* cur = _root;while (cur) // 先找到父节点所在的叶节点的位置,此时cur为nullptr{if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{return false;}}cur = new Node(key); // 申请新节点if (parent->_key < key){parent->_right = cur;}else{parent->_left = cur;}return true;}bool Find(const K& key){Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->_right;}else if (cur->_key > key){cur = cur->_left;}else{return true;}}return false;}bool Erase(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else // 到这就找到了,接下来就是删除逻辑{// 左为空if (cur->_left == nullptr){if (cur == _root) // 注意,如果此时cur为根节点,那么父节点是为nullptr的,所以特判一下{cur = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}delete cur;}else if (cur->_right == nullptr) // 右为空的操作和左为空的刚好相反{if (cur == _root) // 注意,如果此时cur为根节点,那么父节点是为nullptr的,所以特判一下{cur = cur->_left;}else{if (parent->_left == nullptr){parent->_left = cur->_left;}else{parent->_right = cur->_left; }}delete cur;}else // 左右都不为空采取替换法{// 这里选择右子树的最左节点Node* replaceParent = cur;Node* replace = cur->_right;while (replace->_left){replaceParent = replace;replace = replace->_left;}cur->_key = replace->_key; // 进行替换if (replaceParent->_left == replace)replaceParent->_left = replace->_right;elsereplaceParent->_right = replace->_right;delete replace;}return true;}}return false;}void InOrder(){_InOrder(_root);cout << endl;}private:void _InOrder(Node* root){if (root == nullptr){return;}_InOrder(root->_left);cout << root->_key << " ";_InOrder(root->_right);}private:Node* _root = nullptr;};
}
7. 二叉搜索树 key 版本和 key/value 版本
- Key版本(纯键存储)
- 特点:每个节点仅存储一个键(Key),无额外关联值。
- 核心用途:维护一个唯一键的集合,支持快速存在性检查。
- 典型场景:
- 集合(Set):存储不重复的元素(如黑名单、唯一用户名列表)。
- 存在性查询:快速判断某元素是否已存在(如数据库索引中的唯一性约束)。
- 排序遍历:直接输出有序键序列(如按顺序打印所有用户ID)。
- 算法辅助:标记已访问的节点(如DFS/BFS中的访问记录)。
- Key/Value版本(键值对存储)
- 特点:每个节点存储键(Key)和关联的值(Value),形成键值对。
- 核心用途:通过键快速检索、更新或删除关联值。
- 典型场景:
- 字典/映射(Map/Dictionary):存储键到值的映射(如学号一学生信息)。
- 缓存系统:键作为缓存标识,值存储数据(如Redis缓存)。
- 数据库索引:键为索引字段(如商品ID),值为数据地址或元数据。
- 统计计数:键为统计对象(如单词),值为出现次数。
key/value 版本的代码其实就是在 key 版本上加了个 value 参数,查找的时候仍然是通过 key 来进行检索,只不过是在操作具体的元素时改成操作 value。直接看代码吧。
namespace key_value
{template<class K, class V>struct BSTNode{K _key;V _value;BSTNode<K, V>* _left;BSTNode<K, V>* _right;BSTNode(const K& key, const V& value):_key(key), _value(value), _left(nullptr), _right(nullptr){}};template<class K, class V>class BSTree{using Node = BSTNode<K, V>;public:BSTree() = default;BSTree(const BSTree& t){_root = Copy(t._root);}BSTree& operator=(BSTree tmp){swap(_root, tmp._root);return *this;}~BSTree(){Destroy(_root);_root = nullptr;}bool Insert(const K& key, const V& value){if (_root == nullptr){_root = new Node(key, value);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{return false;}}cur = new Node(key, value);if (parent->_key < key){parent->_right = cur;}else{parent->_left = cur;}return true;}Node* Find(const K& key){Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->_right;}else if (cur->_key > key){cur = cur->_left;}else{return cur;}}return nullptr;}bool Erase(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{// 删除// 左为空if (cur->_left == nullptr){if (cur == _root){_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}delete cur;}else if (cur->_right == nullptr){if (cur == _root){_root = cur->_left;}else{// 右为空if (parent->_left == cur){parent->_left = cur->_left;}else{parent->_right = cur->_left;}}delete cur;}else{// 左右都不为空// 右子树最左节点Node* replaceParent = cur;Node* replace = cur->_right;while (replace->_left){replaceParent = replace;replace = replace->_left;}cur->_key = replace->_key;if (replaceParent->_left == replace)replaceParent->_left = replace->_right;elsereplaceParent->_right = replace->_right;delete replace;}return true;}}return false;}void InOrder(){_InOrder(_root);cout << endl;}private:void _InOrder(Node* root){if (root == nullptr){return;}_InOrder(root->_left);cout << root->_key << ":" << root->_value << endl;_InOrder(root->_right);}void Destroy(Node* root){if (root == nullptr)return;Destroy(root->_left);Destroy(root->_right);delete root;}Node* Copy(Node* root){if (root == nullptr)return nullptr;Node* newRoot = new Node(root->_key, root->_value);newRoot->_left = Copy(root->_left);newRoot->_right = Copy(root->_right);return newRoot;}private:Node* _root = nullptr;};
}



