前言
本文所有的分析都基于以下配置---kernel 5.10 crash_arm64_8.0.5
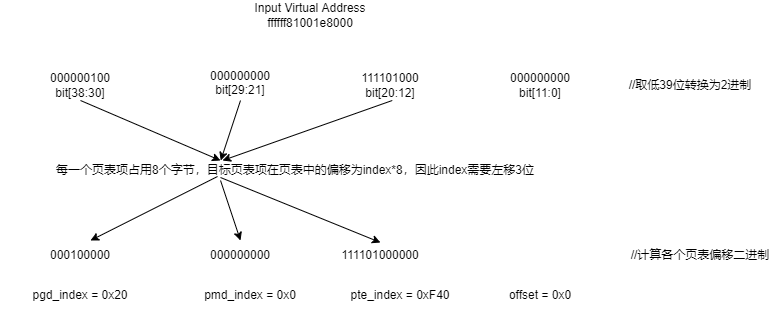
目标板基于ARM64 A72处理器,aarch64,armv8,内存16G,4KBpage,3级页表,39位虚拟地址
AArch64 Linux memory layout with 4KB pages + 3 levels:
Start End Size Use
-----------------------------------------------------------------------
0000000000000000 0000007fffffffff 512GB user
ffffff8000000000 ffffffffffffffff 512GB kernel
————————————————
一、页表转换寄存器描述符
1、页表/页目录结构
基于前言中的内核配置,内核采用39位虚拟地址,因此可寻址范围为2^39 = 512G,采用(linux默认为五级页表,另外还有PUD、P4D,由于本文只配置三级,其它两项不予罗列)3级页表结构,分别为:
PGD (Page Global Directory) bit[39:30] level1
PMD (Page Middle Directory) bit[29:21] level2
PTE (Page Table Entry) bit[20:12] level3每一级索引占9bit,也就是每一个页目录表/页表都有2^9 = 512个页目录项/页表项,使用4K页面大小,2^12 = 4096,因此虚拟地址中offset字段占12位,每一个PTE页表项可以映射4K个地址空间,共有512*512*512个PTE页表项,总的可寻址空间位512*512*512*4096 = 512GB。
每一个页表项占用8个字节,每一张页表有512项,所以一张页表占用空间位512*8 = 4K,因此页表的基地址都是4K对齐的,也就是页表基地址的低12位都为0;
内核页表相关重要宏如下:
gd_offset(mm,addr) ---接受内存描述符mm,和一个虚拟地址作为参数,这个宏产生addr在页全局目录在相应表项中的线性地址
pgd_offset_k(addr) ---用来产生内核页全局目录在相应表项中的线性地址
pgd_index(addr) ---从addr中提取页全局目录表项的索引pmd_index(addr) ---从addr中提取页中间目录表项的索引
pmd_offset(pud,addr) ---接受页上级目录指针,和虚拟地址作为参数,这个宏产生目录项addr在页中间目录项中的偏移地址pte_index(addr) ---从addr中提取页中间目录表项的索引
pge_offset_kernel(dir,addr) ---线性地址addr在页中间目录dir中有一个对应项,该宏就产生这个对应项,即页表的线性地址
2、转换相关寄存器描述符
转换基址寄存器
TTBR1:(Translation Table Base Register)转换表基地址寄存器,用来存放内核(init_mm.pgd)PGD全局转换表的基地址;
TTBR0:(Translation Table Base Register)转换表基地址寄存器,用来存放用户(task_struct.mm.pgd)PGD全局转换表的基地址;
转换描述符格式
ARMv8规定,所有页级别都是用同一个描述符格式,PGD只能输出下一级目录表的基地址。PTE描述符不能指向另一个表的基地址,只能输出块地址。那么反过来PMD,PUD是可以直接输出地址块的,也就是直接指向一个块地址,下一级页表就不会再被映射,这种情况我们称之为巨页。
PTE映射 页大小=4K 2^12
PMD映射 页大小=2M 2^(12+9)
PUD映射 页大小=1G 2^(12+9+9)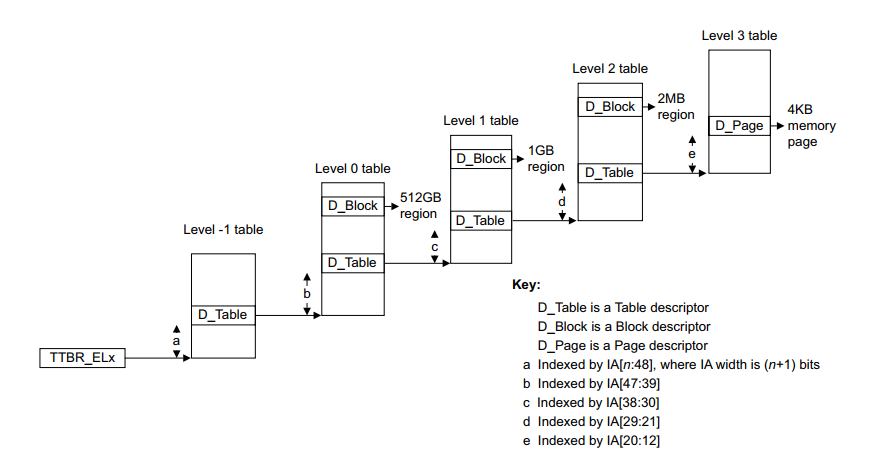
如上图是一个48bit地址的例子,可以看出来,其D_Block在各个页表中的映射块大小,这里我们的描述以实例只针对PTE的映射,也就是页大小4K。
所有页目录/页表项描述符由低bit[1:0]位指出,有以下三种情况:
a、下一级表的地址,在这种情况下,内存可以进一步细分为更小的块(页表级数越多,PTE映射的页大小就越小)。
b、可变大小的内存块的地址(如果为块地址,其还需要加上va[offset]才能构成物理地址,所以称可变大小)。
c、可以标记为fault或invalid(无效条目)。
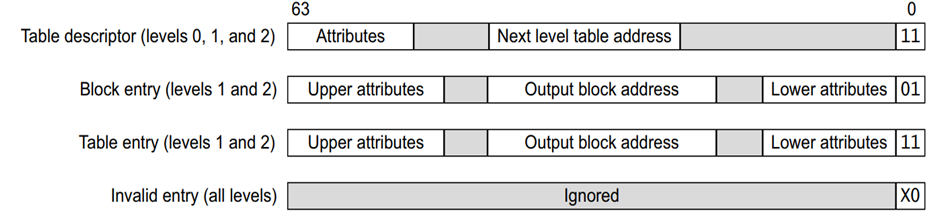
我们主要关注bit[1:0],由图可以得出以下重要结论,页表项中:
当bit[1:0] = {0,1}时,为block entry,其中间部分为物理地址的高位PA[39:12];
当bit[1:0] = {1,1}时,为table entry,其中间部分为[39:12]为下一级页表的物理基地址;
当bit[1:0] = {1,0|0,0}时,该表项为无效项;
转换表描述符中lower attributes中存储相关属性信息,mmu在查找到相应的表项时,首先会查询属性信息,确认地址的相关属性(可执行权限,访问权限,共享属性,访问标志,安全标志等)后,根据需要取出下一级页表的基地址。
3、用户/内核PGD表基地址
基于之前的分析可知,用户虚拟地址和内核虚拟地址转换为物理地址的时候使用不同的页表基地址寄存器(TTBRx),因此它们的转换是基于不同的全局页目录表PGD。
其中内核全局页目录表PGD存储在init_mm.pgd中,我们知道内核是常驻内存的,因此内核的PGD表只有一份,它不会因为进程的切换而改变,所有内核地址访问都依赖这一个PGD表;用户全局页目录表PGD存储在进程描述符task_struct.mm.pgd中,它是在用户进程被创建时同步被创建的,每一个进程描述符task_struct都对应有自己的task_struct.mm.pgd表,进程所有地址的访问都依赖于对应的task_struct.mm.pgd页表的查询,因此在进程切换时,TTBR0的值(task_struct.mm.pgd)是要同时改变的,这也与linux中每一个进程都独占整个虚拟(以此512G)地址空间相对应;
二、转换流程
据此可以画出如下转换框图:
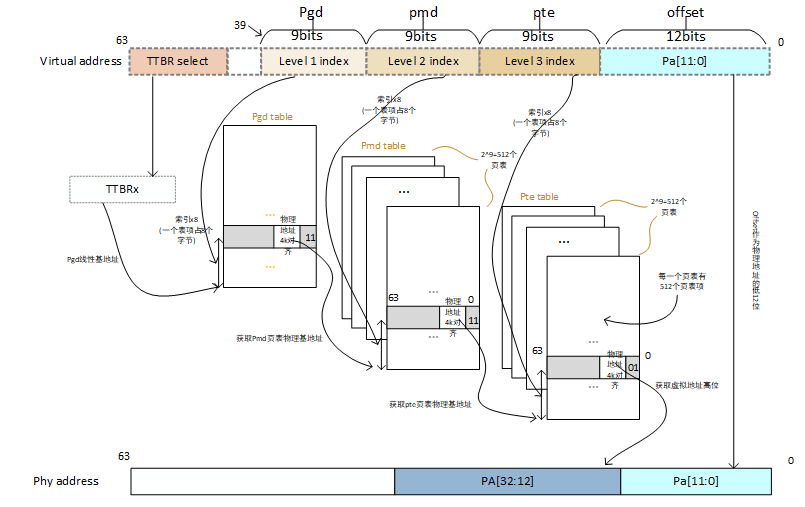
MMU在转换虚拟地址的时候遵循以下步骤(基于以上配置):
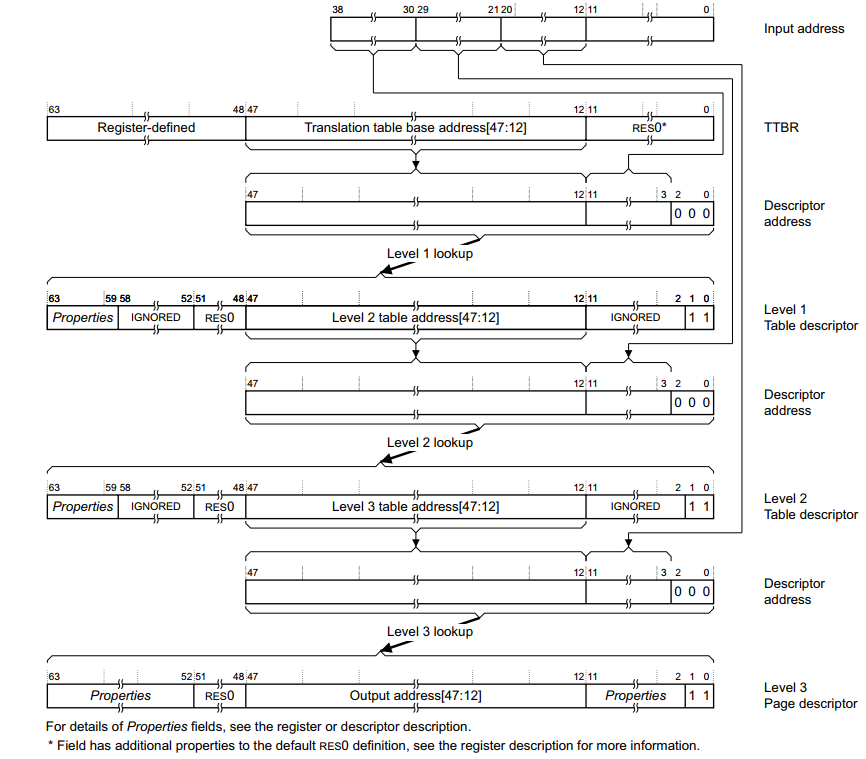
1,如果虚拟地址bit[63:40]都为1,则使用TTBR1作为第一级页目录表基地址,当bit[63:40]都为0时,使用TTBR0作为第一级页目录表基地址;2,PGD包含512个64位PMD表,从虚拟地址中获取VA[39:31]进行索引,找到对应条目为PGD+index[39:31]);4,MMU检查PGD目录项的有效性(bit[1:0]),以及其属性标志判断是否允许请求的内存访问。假设它有效,且允许访问内存;5,MMU从PGD目录表项中获取bit[39:12],作为PMD页表的物理基址(table descriptor)。6,PMD包含512个64位PTE表,从虚拟地址中获取VA[29:21]进行索引,*PMD+(index[29:21]*8),MMU从PMD表项中读取PTE表的基地址;7,MMU检查PMD目录项的有效性(bit[1:0]),以及其属性标志判断是否允许请求的内存访问。假设它有效,且允许访问内存;8,pmd目录表项中获取bit[39:12],作为pte页表的物理基基址,9,pte指向一个4k的页(page descriptor),mmu获取pte的bit[39:12]作为最终物理地址的pa[39:12];10,取出va[11:0]作为pa[11:0],然后返回完整的PA[39:0],以及来自页表项的附加信息。基于4K Page大小的一个完整转换过程,如下图:
三、实例分析
1、基于crash测试流程
本文通过使能内核kdump,然后通过echo c > /proc/sysrq-trigger触发内核panic后加载kdump内核,保存vmcoredump重启,具体流程可以参考如下链接:ARM64使能kdump_arm64 kdump-CSDN博客
2、内核虚拟地址的转换举例
crash tool使用示例如下:
crash vmlinux vmcoredump进入crash tool环境后,我们选择1号进程,也就是init进程来分析。首先用bt命令看下1号进程当前的调用栈。
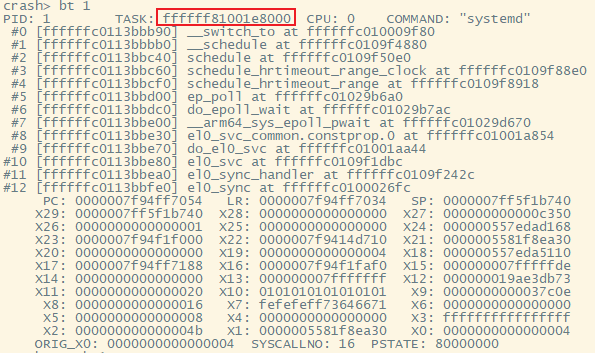
我们选择该进程TASK的地址来进行实际分析。TASK的高位地址全为1,为内核空间的虚拟地址。
手动转换步骤:
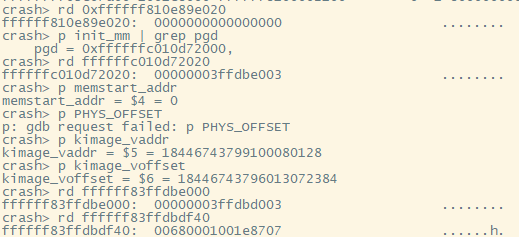
首先我们要知道内核空间的PGD,结合前面分析的linux内核数据结构,内核空间的PGD是保存在init_mm变量中,用p命令打印变量结果,可以看到PGD指针的值。
![]()
计算PGD的物理地址:
static inline pgd_t *pgd_offset_pgd(pgd_t *pgd, unsigned long address)
{return (pgd + pgd_index(address));
};/*
- a shortcut to get a pgd_t in a given mm
*/
#ifndef pgd_offset
#define pgd_offset(mm, address) pgd_offset_pgd((mm)->pgd, (address))
#endif![]()
![]()
计算pgdp = 0xffffffc010d72000 + (pgd_index) = 0xffffffc010d72020;
pgd = (*pgdp) = 00000003ffdbe003;
pgd只能指向下一个页表的基地址,且bit[1:0] = {1,1},为有效项,因此00000003ffdbe003为下一个页表的基地址。
继续计算pmdp,先计算00000003ffdbe000(4K对齐),然后使用__va宏将其转化为线性地址:
#define __va(x) ((void *)__phys_to_virt((phys_addr_t)(x)))
#define __phys_to_virt(x) ((unsigned long)((x) - PHYS_OFFSET) | PAGE_OFFSET)线性地址为:0xffffff83ffdbe000,加上pmd_index,本例中pmd_index = 0x0,得到最终的pmdp = 0xffffff83ffdbe000,pmd = (*pmdp) = 00000003ffdbd003
接着读取PMD的值,由PMD的值获取PTE的值,整个流程如下图所示:
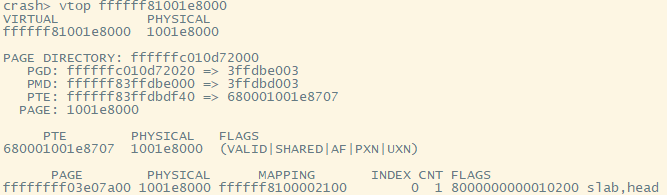
最后由PTE获取最终的物理地址:
PTE的物理地址为:0x00680001001e8707,首先取地址的[39:12]位抹去[11:0]作为基础地址为:1001e8000,再加上offset得到最终的物理地址,本例中offset=0x0,所以最终的物理地址为1001e8000,用vtop命令严重,和手动计算的结果一致。
细心的读者应该发现了一个问题,就是PGD在计算pgdp的时候pgd_index没有乘8,也就是没乘以sizeof(pgd_t)如下所示:
static inline pgd_t *pgd_offset_pgd(pgd_t *pgd, unsigned long address)
{return (pgd + pgd_index(address));
};但是如果找一个pgd_index不为0的堆/栈虚拟地址,计算会发现结果是已经乘过8的,其实它是通过地址的形式隐式的乘以8:
注意PGD的类型pgd == init_mm.pgd == &(init_mm)->pgd三个变量类型均为pgd_t*型,(pmd,pte则都为一个数据类型,并不是地址),其为一个64位的地址类型,占8个字节,因此(pgd_t*类型)pgd+n == (char *)pgd + n*8,因此在计算pgd表内偏移的时候,其实是默认乘以8的。



