(一)SVN
(1)介绍
SVN(Subversion)是用来帮我们进行一个版本控制的一个系统,用来我们管理文件和目录的变更历史,帮助团队共同开发,恢复代码版本等功能,确保了多人开发的一致性和可恢复性
(2)基本概念
仓库:中央存储库,也就是我们保存历史版本代码的地方,我们恢复版本代码就是从这边来
工作副本:用户本地下载的仓库副本,用来提交和修改
提交:就是将本地修改的代码上传到中央仓库,生成一个新的版本
更新:从中央仓库下载最新版本到本地,保持同步
版本号:每次提交偶会生成一个全局递增的版本号
(3)核心功能:
1.协作开发
我们可以通过SVN来提交代码和更新代码,这样一个人提交代码,其他人只需要更新代码,然后在这个基础上,进行修改,这样就可以同步团队成员的操作
注:当多人同时修改同一文件时,SVN就会检测他的冲突并爆出提示
2.版本管理
SVN在每次我们提交代码时,都会记录本次提交的信息,比如:修改的内容,时间,修改人,版本号等,我们可以通过这个功能来恢复到之前的代码,避免误操作导致数据丢失
3.分支与合入
SVN支持创建分支进行独立开发,完成后可以进行合入
这里来简单说一下这里的分支与合入
在说这个之前还需要说几个概念
主干:主干就是一个开发线,在主干稳定后我们切分支就都可以基于主干切出,主干一般也是我们最先更改代码的地方(以游戏为例,我们从主干切一个预发布,那这个主干,我们就需要合入下一个版本要发布的内容,也就是更改代码的地方)
分支:分支就是SVN仓库的一个独立的开发线,可以基于某个时间点的代码创建一个副本(我们可以理解为copy一个一模一样的代码)之后我们在这个副本上进行修改,就不会影响到之前的代码
合入:将修改从一个分支同步到另一个分支的过程,就比如我们在主干修了一个BUG,然后我们已经切出了预发布,那如果我们需要在预发布也修复这个BUG,我们有两个办法,,一个就是再切一个预发布(这个方法费时费力不推荐),另一个就是我们可以选择合入,合入BUG相对于切分支,更加的轻量影响也更小
那说完这三个概念,我们来说一下分支的使用场景,以及他的优势
其实刚刚在上面三个概念,已经说了他的使用场景
1.开发新功能(这个拉的分支,我们一般叫他开发分支),但是不想影响主分支的稳定性
2.修复线上版本BUG(这个拉的分支,我们一般叫预发布分支),而主分支在开发其他功能
3.并行开发多个功能,避免代码的混乱
优势:
1.隔离风险:我们多个分支代码独立,即使开发分支改坏了什么东西,也不影响其他分支的稳定性
2.版本维护:为不同版本修复BUG(但是很多游戏,都是预发布从主干切分支,发布从预发布切分支)所以要修的话应该是所有版本都要修,也就是在主干修好,合入到预发布,然后再到发布
3.并行开发:多个隔离的任务同时开发,提升效率
(4)对比SVN和Git
我们在学习编程的时候,应该很少人会先接触SVN,大部分人都是使用Git来做代码管理多一点,我也是这样,那这边就来简单的说一下,SVN和Git的一个区别
区别:
SVN相对是集中式的,而Git则偏向于分布式
架构:SVN的所有历史代码存储在一个统一的中央服务器中,用户只是保存了当前版本,而Git是每个用户都有完整的仓库克隆(也就是每个用户都有完整的历史)
存储方式:SVN的存储方式,是存储了文件的增量变化(也就是代码的更改),Git存储的是文件的快照,快照在我们学习Redis中也有涉及到过,其实跟我们手机截图一样把我们当前的状态全部都保存下来
分支与合入:SVN的分支创建和合入速度是比较慢的操作比较复杂,Git的创建和合并速度快,适合频繁创建分支,这也就是为什么使用SVN时,我们很少去创建一个分支的原因
离线工作:我们说SVN是由一个中央仓库的所以他提交代码或者进行操作,是需要联网的,但是Git我们是可以在本地进行操作的,可以离线操作
权限管理:SVN的权限管理比较精细,是目录级权限控制(也就是不同的目录需要设置不同访问权限,比如:只读,写,或者无权限),Git通常是仓库级权限控制,我们如果想实现目录级权限控制,就需要使用第三方的插件
速度:SVN的速度较慢,Git的速度更快适合大型项目
那之所以SVN比较慢是因为他的架构方式,存储机制,分支与合入效率有关系
上面说SVN是集中式,有一个中央仓库来帮我们管理代码以及版本,而Git是使用本地仓库,这样就有一个问题是我们SVN提交代码,每次更改都需要与中央服务器通信,网络通信是很慢的,Git是在本地即可修改代码,多次提交代码只需要最后一次与服务器通信即可
同时上面说SVN存储文件,是存储了文件之间的变化,而Git存储的是快照,这也是一种差异
相似:
1.都支持代码版本的管理,提交代码,回滚代码的作用
2.分支与合入
3.解决代码冲突
4.支持给特定版本打标签(如 标记发布版本)
5.协作开发:都支持多人共同开发
这里是两者的工作流程
SVN: 检出代码 → 修改 → 更新 → 解决冲突 → 提交到中央服务器
Git: 克隆仓库 → 修改 → 暂存 → 提交到本地 → 拉取远程变更 → 解决冲突 → 推送到远程仓库
注: 不同职位什么情况下使用SVN的提交和更新?
1.提交
我们在SVN上提交代码,是将本地修改的代码,上传到SVN中央仓库,形成一个新版本记录。所以提交一般都是开发人员去做的,如果我们是测试人员且不涉及到自动化测试那么通常是不需要我们提交代码的
在我们提交代码时,要确保通过了冒烟测试,避免提交有问题代码,以及要填写好清晰的日志信息,说明好修改了什么,同时我们提交代码时最好按照模块提交2
2.更新
更新代码是开发和测试人员都要频繁使用的功能,确保自己的版本是最新的,开发人员需要在最新的代码基础上进行修改,而测试人员需要在最新的代码基础上进行测试
所以我们每天工作前,都需要先更新一下代码
(二)蓝盾流水线
蓝盾流水线是一种用于子哦当年规划持续集成(CI)和持续交付(CD)的平台,用来帮助我们快速完成代码构建,测试,打包,部署的操作,减少人工操作
CI:自动从仓库拉取代码(可以从SVN也可以从Git),编译构建,运行单元测试
CD:将构建的产物自动部署当环境上
简单来写一个蓝盾流水线的流程:
1. 代码提交 → 触发蓝盾流水线(如 SVN 提交后自动启动)。
2. 代码拉取 → 从 SVN 仓库获取最新代码。
3. 编译构建 → 执行编译命令(如 Maven/Gradle/NPM)。
4. 单元测试 → 运行自动化测试,生成测试报告。
5. 代码扫描 → 检查代码规范、安全漏洞。
6. 构建产物打包 → 生成可部署的包(如 JAR/WAR/Docker 镜像)。
7. 部署到测试环境 → 自动部署,供测试团队验证。
8. 人工审批 → 通过后继续部署到生产环境(可选)。
9. 生产环境发布 → 全自动或半自动完成。
蓝盾流水线的优势
1.效率提升:通过大量自动化操作,减少人工的重复劳动
2.质量保障:通过自动化测试和代码扫描,提前显示问题
3.规范流程:团队统一构建,部署,避免环境上差异
SVN与蓝盾的分工
SVN负责代码控制,团队协作(合并冲突,代码共享),权限管理
蓝盾流水线负责,自动化构建(编译打包),自动化测试,自动化部署(部署到测试环境,生产环境)
SVN与蓝盾的协作流程
1.开发阶段:
先从SVN拉取最新代码,在最新代码的基础上进行修改,编译并简单测试,然后提交代码到SVN上
2,触发蓝盾流水线
蓝盾流水线的触发方式又分为自动触发和手动触发
自动触发:SVN提交到特定的分支后(可手动设定)蓝盾通过Webhook或定时轮询的方式检测到有代码的提交,就会自动启动流水线
手动触发:在蓝盾界面手动选择分支或者版本,触发流水线(我们目前使用的是这种方式,需要人手动去触发,我觉得这样也是比较好的,因为如果使用SVN那么他的速度是很慢的,这就导致频繁的去构建,是很耗时的,如果中间又发现什么问题需要修改,但是还没构建完,此时就需要重新构建或者等下一个包)
这里先来说一下什么是构建
构建其实是多个步骤的统称,包括以下阶段:
1.代码编译:将源代码转为可执行文件或者中间代码(比如Java就转为.class文件)
2.依赖管理:解决一些依赖间都冲突,下载第三方库
3.代码处理(这一步我们可以简单理解为对代码的优化,适配和分析)
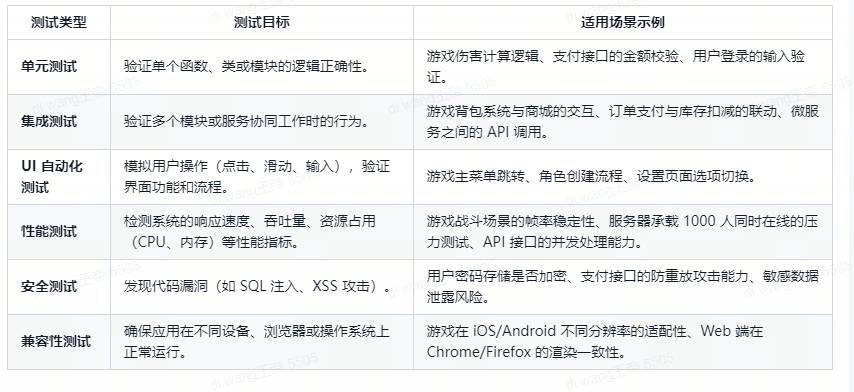
4.运行测试:这个测试跟我们说的功能测试不太一样,这个测试包含了 代码质量,功能正确性,性能,安全性和用户体验多个维度 具体包括:
蓝盾流水线是通过自动化脚本来执行的,这个自动化脚本是需要我们自己写的,也就是测开人员需要完成的一个工作
这是我们的一个工作流程
开发提交代码到 SVN → 蓝盾触发流水线 → 拉取代码 → 构建 → 测试 → 部署到测试环境 → 人工测试 → 审批 → 部署到生产环境 ↑ ↓ └失败则修复并重新提交 ┘
总结:SVN是我们的一个基础,负责代码的存储,版本控制和团队协作,蓝盾则通过自动化帮我们节省时间把SVN中的代码转为可部署的服务






