引言
在当今数据驱动的环境中,组织需要高效的方法来提取、处理和分析网络内容。传统的网络抓取面临着诸多挑战:反机器人保护、复杂的JavaScript渲染以及持续的维护需求。此外,理解非结构化的网络数据则需要复杂的处理能力。
本指南演示了如何使用 n8n 工作流自动化、Scrapeless 网络抓取、Claude AI 进行智能提取,以及 Qdrant 向量数据库进行语义存储,构建完整的网络数据管道。无论您是构建知识库、进行市场研究,还是开发 AI 助手,此工作流都提供了强大的基础。
您将构建的内容
我们的 n8n 工作流结合了几种尖端技术:
- Scrapeless 网络解锁器:先进的网络抓取与 JavaScript 渲染
- Claude 3.7 诗集:人工智能驱动的数据提取和结构化
- Ollama 嵌入:本地向量嵌入生成
- Qdrant 向量数据库:语义存储和检索
- 通知系统:通过网络钩子实现实时监控
这个端到端的管道将凌乱的网络数据转化为结构化、向量化的信息,准备进行语义搜索和 AI 应用。
安装与设置
安装 n8n
n8n 需要 Node.js v18、v20 或 v22。如果您遇到版本兼容性问题:
Copy
# 检查您的 Node.js 版本
node -v# 如果您有一个较新不受支持的版本(例如 v23+),请安装 nvm
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.5/install.sh | bash
# 或者对于 Windows,使用 NVM for Windows 安装程序# 安装兼容的 Node.js 版本
nvm install 20# 使用已安装的版本
nvm use 20# 全局安装 n8n
npm install n8n -g# 运行 n8n
n8n您的 n8n 实例现在应该可以在 http://localhost:5678 访问。
设置 Claude API
- 访问 Anthropic 控制台并创建一个帐户
- 导航到 API 密钥部分
- 点击“创建密钥”,并设置适当的权限
- 复制您的 API 密钥以用于 n8n 工作流(在 AI 数据检查器、Claude 数据提取器和 Claude AI 代理中)
设置 Scrapeless
- 访问 Scrapeless 并创建一个帐户
- 导航到仪表板中的通用抓取 API 部分 Effortless Web Scraping Toolkit - Scrapeless
- 复制您的令牌以用于 n8n 工作流
您可以使用此 curl 命令自定义您的 Scrapeless 网络抓取请求,并将其直接导入到 n8n 的 HTTP 请求节点中:
Copy
curl -X POST "https://api.scrapeless.com/api/v1/unlocker/request" \-H "Content-Type: application/json" \-H "x-api-token: scrapeless_api_key" \-d '{"actor": "unlocker.webunlocker","proxy": {"country": "ANY"},"input": {"url": "https://www.scrapeless.com","method": "GET","redirect": true,"js_render": true,"js_instructions": [{"wait":100}],"block": {"resources": ["image","font","script"],"urls": ["https://example.com"]}}}'
使用 Docker 安装 Qdrant
Copy
# 拉取 Qdrant 镜像
docker pull qdrant/qdrant# 以数据持久化运行 Qdrant 容器
docker run -d \--name qdrant-server \-p 6333:6333 \-p 6334:6334 \-v $(pwd)/qdrant_storage:/qdrant/storage \qdrant/qdrant验证 Qdrant 是否正在运行:
Copy
curl http://localhost:6333/healthz安装 Ollama
macOS:
Copy
brew install ollamaLinux:
Copy
curl -fsSL https://ollama.com/install.sh | shWindows:从 Ollama 的网站下载并安装。
启动 Ollama 服务器:
Copy
ollama serve安装所需的嵌入模型:
Copy
ollama pull all-minilm验证模型安装:
Copy
ollama list设置 n8n 工作流
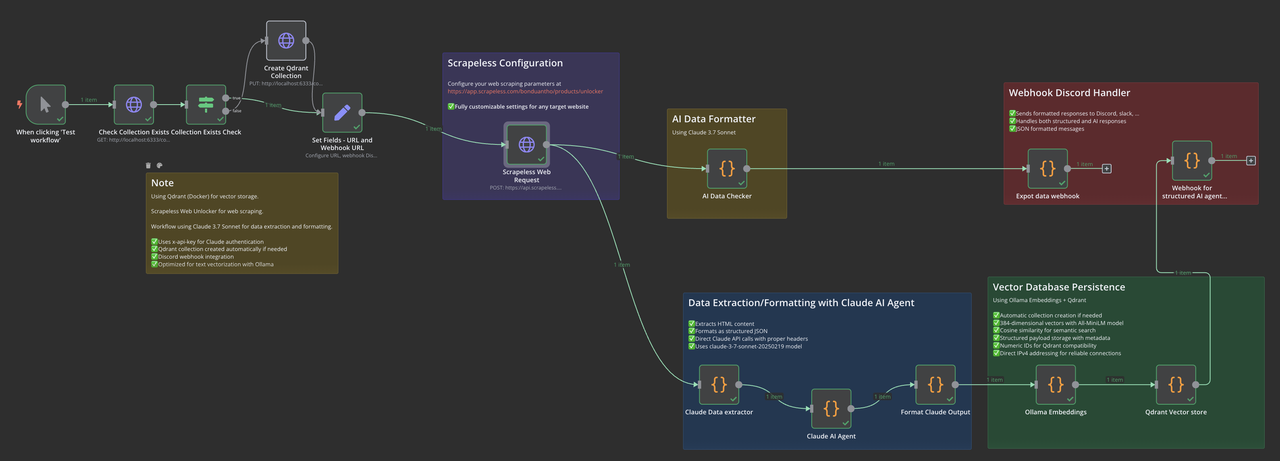
工作流概述
我们的工作流由以下关键组件组成:
- 手动/计划触发:启动工作流
- 集合检查:验证 Qdrant 集合是否存在
- URL 配置:设置目标 URL 和参数
- Scrapeless 网络请求:提取 HTML 内容
- Claude 数据提取:处理和结构化数据
- Ollama 嵌入:生成向量嵌入
- Qdrant 存储:保存向量和元数据
- 通知:通过网络钩子发送状态更新
步骤 1:配置工作流触发器和集合检查
首先添加一个手动触发节点,然后添加一个 HTTP 请求节点以检查您的 Qdrant 集合是否存在。您可以在此初始步骤中自定义集合名称 - 如果集合不存在,工作流将自动创建它。
重要说明: 如果您想使用与默认“hacker-news”不同的集合名称,请确保在所有引用 Qdrant 的节点中一致地更改它。
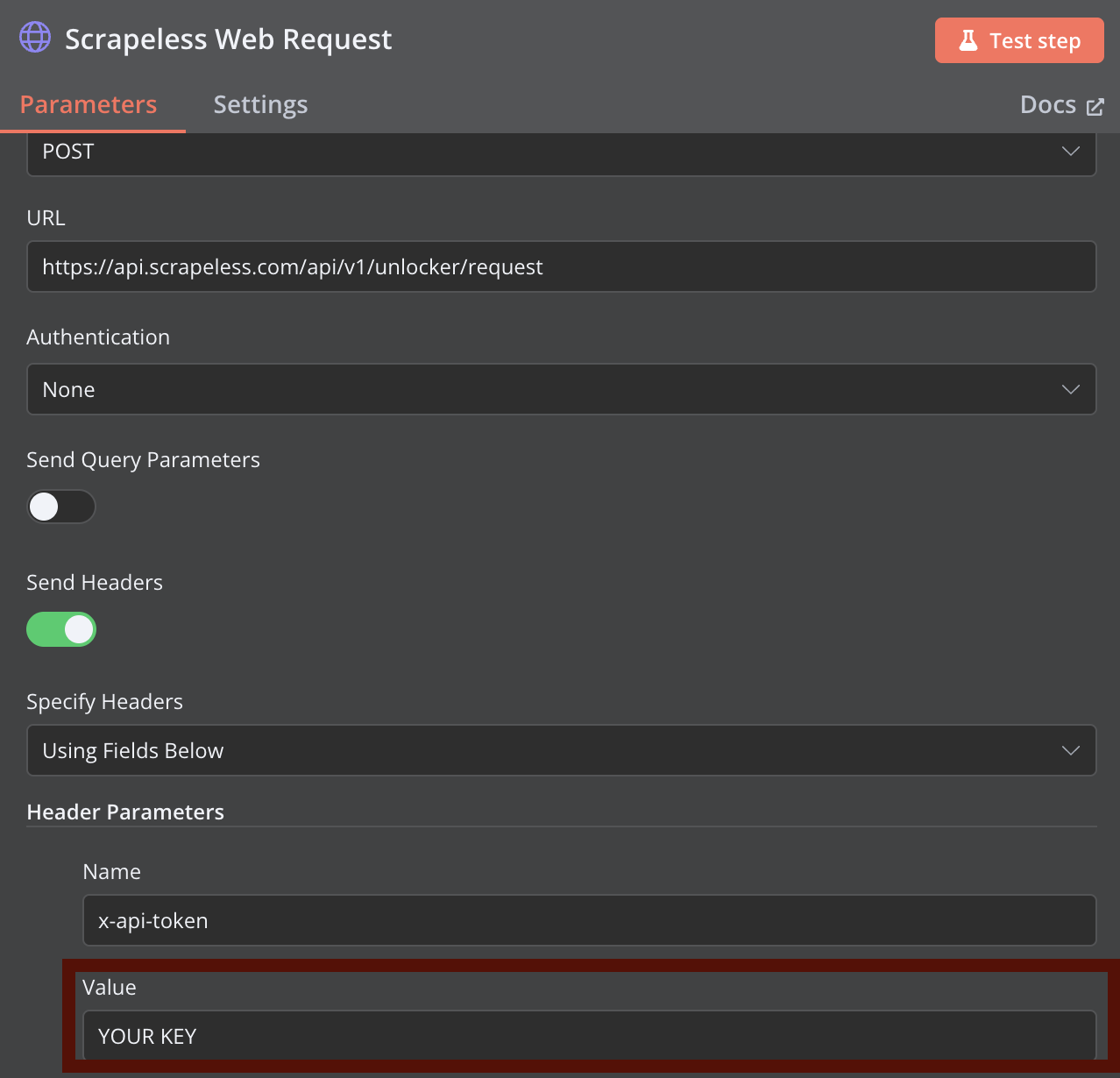
步骤 2:配置 Scrapeless 网络请求
添加一个 HTTP 请求节点用于 Scrapeless 网络抓取。使用之前提供的 curl 命令配置节点,将 YOUR_API_TOKEN 替换为您实际的 Scrapeless API 令牌。
您可以在 Scrapeless Web Unlocker 中配置更高级的抓取参数。
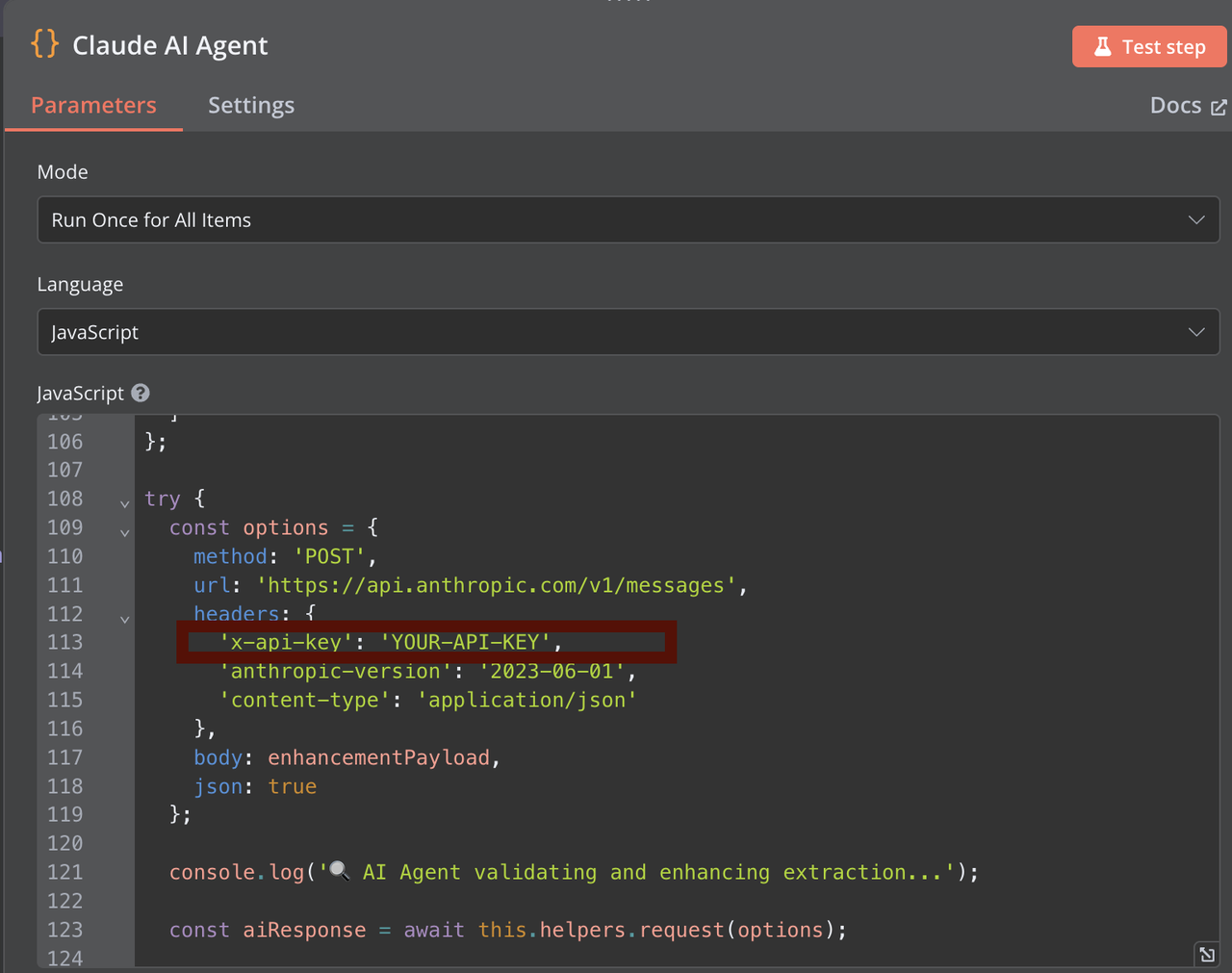
步骤 3:Claude 数据提取
添加一个节点处理 HTML 内容,使用 Claude。您需要提供您的 Claude API 密钥以进行身份验证。Claude 提取器分析 HTML 内容并以 JSON 格式返回结构化数据。
步骤 4:格式化 Claude 输出
此节点获取 Claude 的响应,并通过提取相关信息并适当地格式化来为向量化做准备。
步骤 5:生成 Ollama 嵌入
此节点将结构化文本发送到 Ollama 以生成嵌入。确保您的 Ollama 服务器正在运行,并且已安装 all-minilm 模型。
步骤 6:Qdrant 向量存储
此节点将生成的嵌入存储在您的 Qdrant 集合中,连同相关的元数据。
步骤 7:通知系统
最后一个节点通过您配置的网络钩子发送工作流执行状态的通知。
常见问题排查
n8n Node.js 版本问题
如果您看到如下错误:
Copy
您的 Node.js 版本 X 当前不受 n8n 支持。
请使用 Node.js v18.17.0(推荐)、v20 或 v22! 通过安装 nvm 并使用兼容的 Node.js 版本来修复,如设置部分所述。
Scrapeless API 连接问题
- 验证您的 API 令牌是否正确
- 检查您是否超出了 API 速率限制
- 确保 URL 格式正确
Ollama 嵌入错误
常见错误:connect ECONNREFUSED ::1:11434
修复:
- 确保 Ollama 正在运行:ollama serve
- 验证模型是否已安装:ollama pull all-minilm
- 使用直接 IP(127.0.0.1)而不是 localhost
- 检查是否有其他进程在使用端口 11434
高级用法场景
批处理多个 URL
要在一次工作流执行中处理多个 URL:
- 使用批次拆分节点并行处理 URL
- 为每个批次配置适当的错误处理
- 使用合并节点合并结果
定期数据更新
通过定期更新保持您的向量数据库最新:
- 用计划节点替换手动触发
- 配置更新频率(每日、每周等)
- 使用如果节点仅处理新或更改的内容
自定义提取模板
为不同内容类型调整 Claude 的提取:
- 为新闻文章、产品页面、文档等创建特定提示
- 使用开关节点选择合适的提示
- 将提取模板存储为环境变量
结论
此 n8n 工作流创建了一个强大的数据管道,结合了 Scrapeless 网络抓取、Claude AI 提取、向量嵌入和 Qdrant 存储的优势。通过自动化这些复杂的过程,您可以专注于使用提取的数据,而不是获取它的技术挑战。
n8n 的模块化特性使您能够扩展此工作流,增加更多处理步骤、与其他系统的集成或自定义逻辑,以满足您的特定需求。无论您是构建 AI 知识库、进行竞争分析,还是监控网络内容,这个工作流都提供了坚实的基础。






