一、引言:数据导出的演进驱动力
在数字化时代,数据导出功能已成为企业数据服务的基础能力。随着数据规模从GB级向TB级甚至PB级发展,传统导出方案面临三大核心挑战:
- 数据规模爆炸:单次导出数据量从万级到亿级的增长
- 业务需求多样化:实时导出、增量同步、跨云传输等新场景
- 系统稳定性要求:避免导出作业影响在线业务
本文将基于Java技术栈,通过架构演进视角解析不同阶段的解决方案,特别结合阿里EasyExcel等开源工具的最佳实践。
二、基础方案演进
1. 全量内存加载(原始阶段)
实现思想:
- 一次性加载全量数据到内存
- 直接写入输出文件
// 反模式:全量内存加载
public void exportAllToExcel() {List<Data> allData = jdbcTemplate.query("SELECT * FROM big_table", rowMapper);EasyExcel.write("output.xlsx").sheet().doWrite(allData); // OOM风险点
}优缺点:
- ✅ 实现简单直接
- ❌ 内存溢出风险
- ❌ 数据库长事务问题
适用场景:开发测试环境,数据量<1万条
2. 分页流式处理(安全边界)
实现思想:
- 分页查询控制单次数据量
- 流式写入避免内存堆积
// EasyExcel分页流式写入
public void exportByPage(int pageSize) {ExcelWriter excelWriter = null;try {excelWriter = EasyExcel.write("output.xlsx").build();for (int page = 0; ; page++) {List<Data> chunk = jdbcTemplate.query("SELECT * FROM big_table LIMIT ? OFFSET ?",rowMapper, pageSize, page * pageSize);if (chunk.isEmpty()) break;excelWriter.write(chunk, EasyExcel.writerSheet("Sheet1").build());}} finally {if (excelWriter != null) {excelWriter.finish();}}
}优化点:
- 采用游标分页替代LIMIT/OFFSET(基于ID范围查询)
- 添加线程休眠避免数据库压力过大
适用场景:生产环境,1万~100万条数据
三、高级方案演进
1. 异步离线导出
架构设计:
[ API请求 ] → [ 消息队列 ] → [ Worker 消费 ] → [ 分布式存储 ] → [ 通知下载 ]
关键实现:
// Spring Boot集成示例
@RestController
public class ExportController {@Autowiredprivate JobLauncher jobLauncher;@Autowiredprivate Job exportJob;@PostMapping("/export")public ResponseEntity<String> triggerExport() {JobParameters params = new JobParametersBuilder().addLong("startTime", System.currentTimeMillis()).toJobParameters();jobLauncher.run(exportJob, params);return ResponseEntity.accepted().body("导出任务已提交");}
}// EasyExcel批处理Writer
public class ExcelItemWriter implements ItemWriter<Data> {@Overridepublic void write(List<? extends Data> items) {String path = "/data/export_" + System.currentTimeMillis() + ".xlsx";EasyExcel.write(path).sheet().doWrite(items);}
}优缺点:
- ✅ 资源隔离,不影响主业务
- ✅ 支持失败重试
- ❌ 时效性较差(分钟级)
适用场景:百万级数据,对实时性要求不高的后台作业
2. 堆外内存优化方案
实现思想:
- 使用ByteBuffer分配直接内存
- 通过内存映射文件实现零拷贝
- 结合分页查询构建双缓冲机制
public class OffHeapExporter {private static final int BUFFER_SIZE = 64 * 1024 * 1024; // 64MB/缓冲区public void export(String filePath) throws IOException {// 1. 初始化堆外缓冲区ByteBuffer buffer = ByteBuffer.allocateDirect(BUFFER_SIZE);// 2. 创建文件通道(NIO)try (FileChannel channel = FileChannel.open(Paths.get(filePath), StandardOpenOption.CREATE, StandardOpenOption.WRITE)) {// 3. 分页填充+批量写入while (hasMoreData()) {buffer.clear(); // 重置缓冲区fillBufferFromDB(buffer); // 从数据库分页读取buffer.flip(); // 切换为读模式channel.write(buffer); // 零拷贝写入}}}private void fillBufferFromDB(ByteBuffer buffer) {// 示例:分页查询填充逻辑List<Data> chunk = jdbcTemplate.query("SELECT * FROM table WHERE id > ? LIMIT 10000",rowMapper, lastId);chunk.forEach(data -> {byte[] bytes = serialize(data);if (buffer.remaining() < bytes.length) {buffer.flip(); // 立即写入已填充数据channel.write(buffer);buffer.clear();}buffer.put(bytes);});}
}方案优缺点
| 优势 | 局限性 |
| ✅ 规避GC停顿(实测降低90%以上) | ⚠️ 需手动管理内存释放 |
| ✅ 提升吞吐量(实测提升30%~50%) | ⚠️ 存在内存泄漏风险 |
| ✅ 支持更大数据量(突破JVM堆限制) | ⚠️ 调试工具支持较少 |
| ✅ 减少CPU拷贝次数(DMA技术) | ⚠️ 需处理字节级操作 |
适用场景
- 数据规模
- 单次导出数据量 > 500万条
- 单文件大小 > 1GB
- 性能要求
- 要求导出P99延迟 < 1s
- 系统GC停顿敏感场景
- 特殊环境
- 容器环境(受限堆内存)
- 需要与Native库交互的场景
四、进阶方案详解
方案1:Spark分布式导出
实现步骤:
- 数据准备:将源数据加载为Spark DataFrame
- 转换处理:执行必要的数据清洗
- 输出生成:分布式写入Excel
// Spark+EasyExcel集成方案
public class SparkExportJob {public static void main(String[] args) {SparkSession spark = SparkSession.builder().appName("DataExport").getOrCreate();// 读取数据源Dataset<Row> df = spark.read().format("jdbc").option("url", "jdbc:mysql://host:3306/db").option("dbtable", "source_table").load();// 转换为POJO列表List<Data> dataList = df.collectAsList().stream().map(row -> convertToData(row)).collect(Collectors.toList());// 使用EasyExcel写入EasyExcel.write("hdfs://output.xlsx").sheet("Sheet1").doWrite(dataList);}
}注意事项:
- 大数据量时建议先输出为Parquet再转换
- 需要合理设置executor内存
适用场景:
- 数据规模:TB级结构化/半结构化数据
- 典型业务:全库历史数据迁移、跨数据源合并报表
方案2:CDC增量导出
架构图:
[ MySQL ] → [ Debezium ] → [ Kafka ] → [ Flink ] → [ Excel ]
实现步骤:
- 数据捕获
- MySQL事务提交触发binlog生成
- Debezium解析binlog,提取变更事件并转为JSON/Avro格式
- 队列缓冲
- Kafka按"库名.表名"创建Topic
- 主键哈希分区保证同一主键事件有序
- 流处理
- Flink消费Kafka数据,每小时滚动窗口聚合
- 通过状态管理实现主键去重和版本覆盖
- 文件输出
- 触发式生成Excel文件(行数超100万或超1小时滚动)
- 计算CRC32校验码并保存断点位置
- 容错机制
- 异常数据转入死信队列
- 校验失败时自动重试最近3次Checkpoint
关键代码:
// Flink处理CDC事件
public class CdcExportJob {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("kafka:9092").setTopics("cdc_events").setDeserializer(new SimpleStringSchema()).build();env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source").process(new ProcessFunction<String, Data>() {@Overridepublic void processElement(String json, Context ctx, Collector<Data> out) {Data data = parseChangeEvent(json);if (data != null) {out.collect(data);}}}).addSink(new ExcelSink());env.execute("CDC Export");}
}// 自定义Excel Sink
class ExcelSink extends RichSinkFunction<Data> {private transient ExcelWriter writer;@Overridepublic void open(Configuration parameters) {writer = EasyExcel.write("increment_export.xlsx").build();}@Overridepublic void invoke(Data value, Context context) {writer.write(Collections.singletonList(value), EasyExcel.writerSheet("Sheet1").build());}@Overridepublic void close() {if (writer != null) {writer.finish();}}
}适用场景:
- 数据规模:高频更新的百万级数据
- 典型业务:实时订单导出、财务流水同步
五、架构视角总结
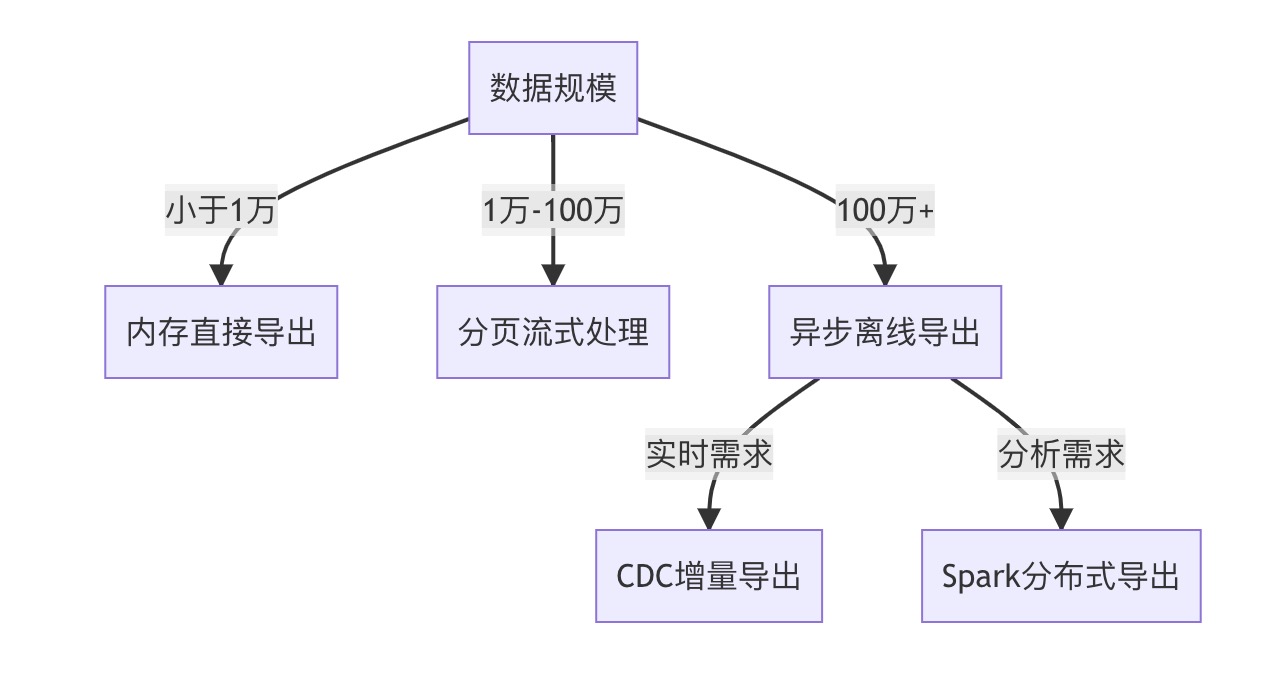
架构选型建议:
- 成本敏感型:分页流式+EasyExcel组合性价比最高
- 实时性要求:CDC方案配合Flink实现秒级延迟
- 超大规模数据:采用Spark分布式处理+分阶段存储
通过架构的持续演进,数据导出能力从简单的功能实现发展为完整的技术体系。建议企业根据自身业务发展阶段,选择合适的演进路径实施。






