无论是归档网站、测试页面设计,还是为报告记录网页内容,一个可靠的截图工具都能大大提升效率。本文将介绍如何使用Python、Selenium和wxPython构建一个用户友好的网页截图工具。该工具能在浏览器中显示网页,自动平滑滚动到底部以触发懒加载内容,并将整个网页截图保存为PNG文件。
C:\pythoncode\new\webpage_screenshot.py
为什么需要一个网页截图工具?
现代网页通常是动态的,会随着用户滚动加载内容(即懒加载)。传统的截图方法只能捕获可见区域,可能会遗漏动态加载的内容。我们的工具解决了以下问题:
- 显示网页:通过可见的浏览器窗口,让用户可以看到网页加载和滚动的过程。
- 平滑滚动:自动以平滑动画滚动到底部,确保所有懒加载内容都加载完成。
- 完整截图:捕获整个网页,包括超出视口的部分。
- 用户友好界面:提供图形界面,方便输入URL、选择保存路径,并显示进度反馈。
使用技术
- Python:核心编程语言,用于编写工具逻辑。
- Selenium:浏览器自动化框架,用于控制Chrome浏览器并捕获截图。
- wxPython:用于创建跨平台的图形用户界面(GUI)。
- ChromeDriver:Chrome的WebDriver,通过
webdriver_manager自动管理。
工作原理
该工具基于wxPython构建,提供简单的图形界面。用户输入网页URL,选择保存路径,点击按钮即可开始截图。以下是工作流程:
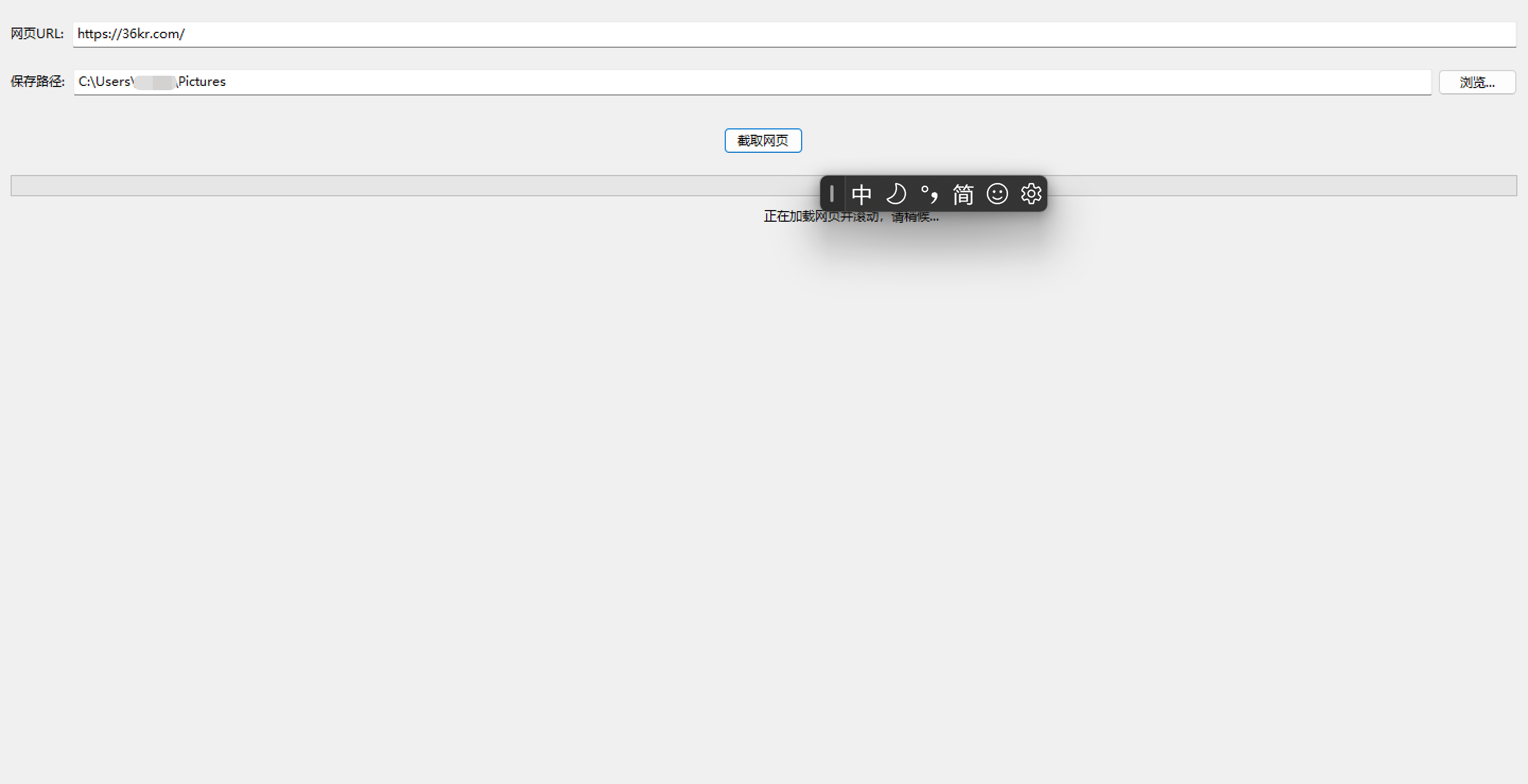
1. 用户界面
工具使用wxPython创建了一个简洁的GUI,包含以下组件:
- URL输入框:用户输入目标网页的URL(若无
http://或https://前缀,自动添加https://)。 - 保存路径选择:允许用户选择截图保存的文件夹,默认路径为用户的“图片”文件夹。
- 截图按钮:触发网页加载和截图过程。
- 进度条:实时显示滚动和截图进度。
- 状态栏:显示当前操作状态(如“正在加载网页”或“截图已保存”)。
2. 网页加载与滚动
- 非无头模式:工具使用Selenium控制Chrome浏览器,并以可见窗口运行(移除
--headless选项),让用户看到网页的加载和滚动过程。 - 平滑滚动:通过JavaScript的
window.scrollTo方法实现平滑滚动(behavior: 'smooth'),每次滚动一小段(基于页面高度和视口高度计算步数),并暂停0.5秒以确保内容加载。 - 进度反馈:滚动过程中,进度条根据滚动步数更新,增强用户体验。
3. 截图捕获
- CDP方法:使用Chrome DevTools Protocol(CDP)的
Page.captureScreenshot方法,一次性捕获整个网页(captureBeyondViewport: True),无需拼接。 - 保存为PNG:截图以PNG格式保存,文件名为
{域名}_{时间戳}.png,例如example.com_20250516_194023.png。
4. 错误处理
- 验证URL和保存路径的有效性,若无效则弹出提示。
- 捕获所有异常,确保浏览器在错误发生时正确关闭,并通过弹窗和状态栏向用户反馈详细错误信息。
代码实现
以下是核心代码片段,展示了滚动和截图逻辑:
import wx
import os
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import base64
from urllib.parse import urlparse
import threadingclass ScreenshotApp(wx.Frame):def __init__(self, parent, title):super(ScreenshotApp, self).__init__(parent, title=title, size=(600, 300))self.InitUI()self.Centre()self.Show()def InitUI(self):panel = wx.Panel(self)vbox = wx.BoxSizer(wx.VERTICAL)# URL输入区域url_box = wx.BoxSizer(wx.HORIZONTAL)url_label = wx.StaticText(panel, label="网页URL:")self.url_text = wx.TextCtrl(panel, size=(400, -1))url_box.Add(url_label, flag=wx.RIGHT | wx.ALIGN_CENTER_VERTICAL, border=8)url_box.Add(self.url_text, proportion=1)# 保存路径区域path_box = wx.BoxSizer(wx.HORIZONTAL)path_label = wx.StaticText(panel, label="保存路径:")self.path_text = wx.TextCtrl(panel, size=(300, -1))browse_button = wx.Button(panel, label="浏览...")path_box.Add(path_label, flag=wx.RIGHT | wx.ALIGN_CENTER_VERTICAL, border=8)path_box.Add(self.path_text, proportion=1, flag=wx.RIGHT, border=5)path_box.Add(browse_button)# 截图按钮screenshot_button = wx.Button(panel, label="截取网页")# 进度条self.progress_bar = wx.Gauge(panel, range=100, size=(400, 20))self.progress_bar.SetValue(0)# 状态显示区域self.status_text = wx.StaticText(panel, label="")# 添加到垂直布局vbox.Add((-1, 20))vbox.Add(url_box, flag=wx.EXPAND | wx.LEFT | wx.RIGHT, border=10)vbox.Add((-1, 20))vbox.Add(path_box, flag=wx.EXPAND | wx.LEFT | wx.RIGHT, border=10)vbox.Add((-1, 30))vbox.Add(screenshot_button, flag=wx.ALIGN_CENTER)vbox.Add((-1, 20))vbox.Add(self.progress_bar, flag=wx.EXPAND | wx.LEFT | wx.RIGHT, border=10)vbox.Add((-1, 10))vbox.Add(self.status_text, flag=wx.ALIGN_CENTER)# 绑定事件browse_button.Bind(wx.EVT_BUTTON, self.OnBrowse)screenshot_button.Bind(wx.EVT_BUTTON, self.OnScreenshot)# 设置默认保存路径为用户的图片文件夹default_path = os.path.join(os.path.expanduser("~"), "Pictures")self.path_text.SetValue(default_path)panel.SetSizer(vbox)def OnBrowse(self, event):dialog = wx.DirDialog(self, "选择保存截图的文件夹", style=wx.DD_DEFAULT_STYLE)if dialog.ShowModal() == wx.ID_OK:self.path_text.SetValue(dialog.GetPath())dialog.Destroy()def OnScreenshot(self, event):url = self.url_text.GetValue().strip()save_path = self.path_text.GetValue().strip()# 验证URLif not url:wx.MessageBox("请输入有效的URL", "错误", wx.OK | wx.ICON_ERROR)return# 如果URL没有http前缀,添加https://if not url.startswith(('http://', 'https://')):url = 'https://' + urlself.url_text.SetValue(url)# 验证保存路径if not os.path.exists(save_path):try:os.makedirs(save_path)except Exception as e:wx.MessageBox(f"创建保存路径失败: {str(e)}", "错误", wx.OK | wx.ICON_ERROR)returnself.status_text.SetLabel("正在加载网页并滚动,请稍候...")self.progress_bar.SetValue(0)self.Layout()# 使用线程避免界面冻结thread = threading.Thread(target=self.take_screenshot, args=(url, save_path))thread.daemon = Truethread.start()def scroll_page(self, driver):"""滚动页面以触发所有懒加载内容,显示滚动效果"""total_height = driver.execute_script("return document.body.scrollHeight")viewport_height = driver.execute_script("return window.innerHeight")steps = max(1, total_height // viewport_height) # 计算滚动步数step_height = total_height / stepsfor i in range(steps + 1):scroll_position = int(i * step_height)driver.execute_script(f"window.scrollTo({{top: {scroll_position}, behavior: 'smooth'}});")wx.CallAfter(self.progress_bar.SetValue, int((i + 1) / (steps + 1) * 100))time.sleep(0.5) # 等待平滑滚动和内容加载time.sleep(1) # 确保所有内容加载完成def take_screenshot(self, url, save_path):try:# 设置Chrome选项,移除无头模式以显示浏览器chrome_options = Options()chrome_options.add_argument("--disable-gpu")chrome_options.add_argument("--disable-infobars")chrome_options.add_argument("--disable-extensions")chrome_options.add_argument("--window-size=1920,1080") # 设置初始窗口大小# 启动浏览器service = Service(ChromeDriverManager().install())driver = webdriver.Chrome(service=service, options=chrome_options)# 访问网页driver.get(url)time.sleep(3) # 等待页面初始加载# 滚动页面以触发懒加载内容self.scroll_page(driver)# 获取域名和时间戳domain = urlparse(url).netloc or "webpage"timestamp = time.strftime("%Y%m%d_%H%M%S")# 使用CDP方法获取完整页面截图result = driver.execute_cdp_cmd('Page.captureScreenshot', {'format': 'png', 'captureBeyondViewport': True})image_data = base64.b64decode(result['data'])save_file = os.path.join(save_path, f"{domain}_{timestamp}.png")with open(save_file, 'wb') as f:f.write(image_data)driver.quit()wx.CallAfter(self.screenshot_complete, save_file)except Exception as e:if 'driver' in locals():driver.quit()wx.CallAfter(self.screenshot_error, str(e))def screenshot_complete(self, filepath):self.status_text.SetLabel(f"截图已保存至: {filepath}")self.progress_bar.SetValue(100)wx.MessageBox(f"截图已保存至:\n{filepath}", "成功", wx.OK | wx.ICON_INFORMATION)def screenshot_error(self, error_msg):self.status_text.SetLabel(f"截图失败: {error_msg}")self.progress_bar.SetValue(0)wx.MessageBox(f"截图失败: {error_msg}", "错误", wx.OK | wx.ICON_ERROR)if __name__ == '__main__':app = wx.App()ScreenshotApp(None, title='网页截图工具')app.MainLoop()安装与运行
环境要求
- Python 3.8+
- 依赖库:
pip install wxPython selenium webdriver_manager
运行步骤
- 安装依赖库。
- 运行代码,打开GUI窗口。
- 输入网页URL(如
example.com)。 - 选择保存路径(或使用默认路径)。
- 点击“截取网页”,观察浏览器打开、平滑滚动并截图。
- 截图完成后,查看保存的PNG文件。
优势与局限性
优势
- 直观体验:可见的浏览器窗口和进度条让用户清楚操作进程。
- 完整截图:支持动态网页,确保捕获所有内容。
- 易用性:简单的GUI适合非技术用户。
- 跨平台:wxPython和Selenium支持Windows、macOS和Linux。
局限性
- 性能:对于超长网页,滚动和加载可能需要较长时间。
- 依赖性:需要安装Chrome浏览器和ChromeDriver。
- CDP限制:某些Chrome版本可能不支持CDP截图(可回退到拼接方法)。
运行结果