SpringBoot + Druid + Dynamic Datasource 多数据源配置
- 1、依赖
- 2、application.yml
- 3、多数据源 Duid 自动装配详解
- 3.1、自动装配 spring.datasource.dynamic
- 3.2、自动装配多数据源 datasource
- 3.3、自动装配每个数据源下的 duid 配置
- 3.4、自动装配 StatViewServlet
- 3.5、自动装配 WebStatFilter
- 3.6、自动装配 AopPatterns
- 3.7、Filter 配置类
- 4、Druid 监控页面
- 4.1、首页
- 4.2、数据源列表
- 4.2、SQL 监控
- 4.3、SQL 防火墙
- 4.4、Web 应用
- 4.5、URI 监控
- 4.6、Web Session 监控
- 4.7、Spring 监控
- 4.8、JSON API
- 5、动态切换数据源
- 5.1、数据源枚举
- 5.2、Controller 层
- 5.3、AOP 根据入参自动切换数据源
- 6、日志输出效果
1、依赖
<dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>4.3.1</version><exclusions><exclusion><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId></exclusion></exclusions></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.24<</version></dependency>
2、application.yml
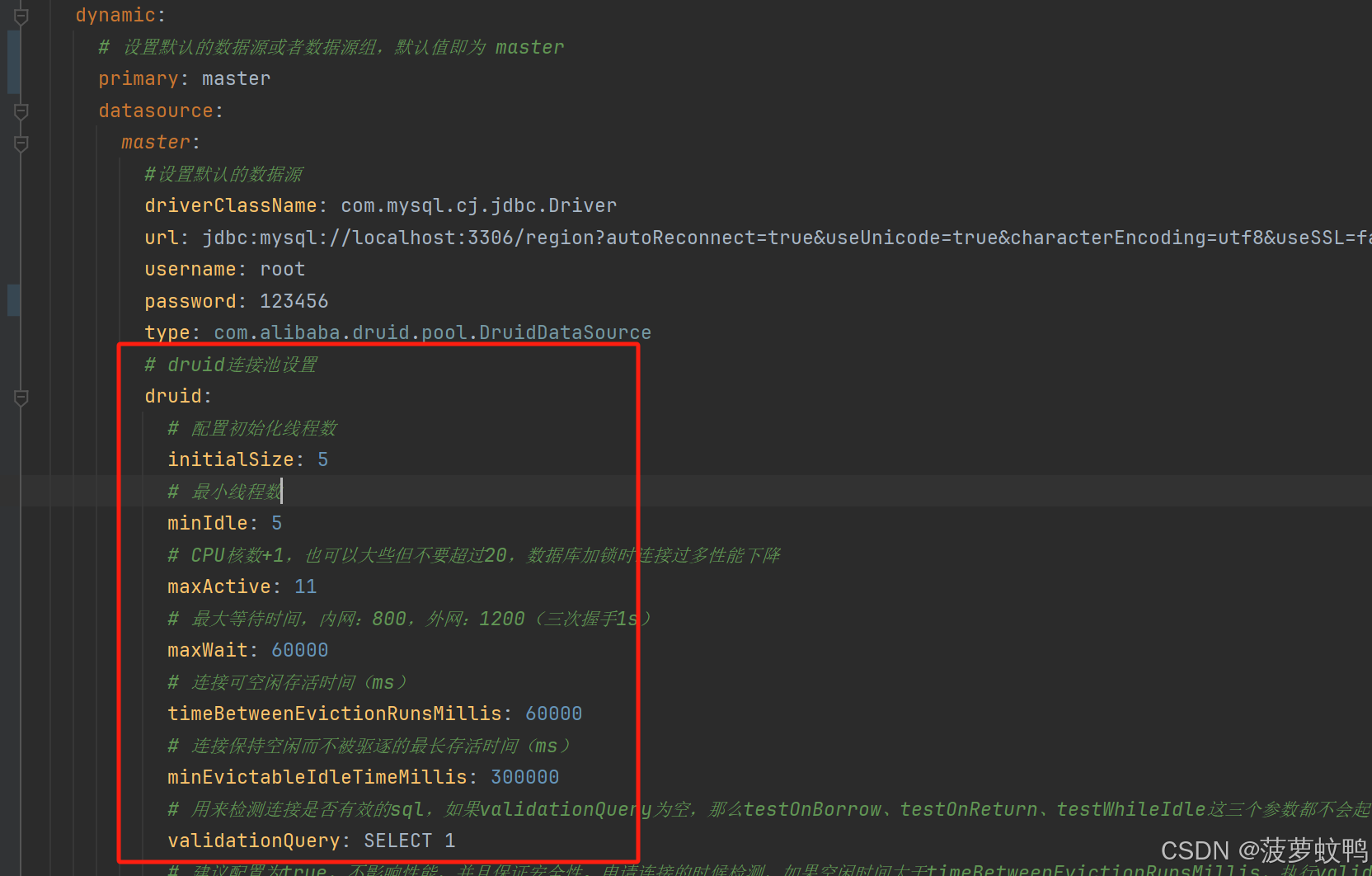
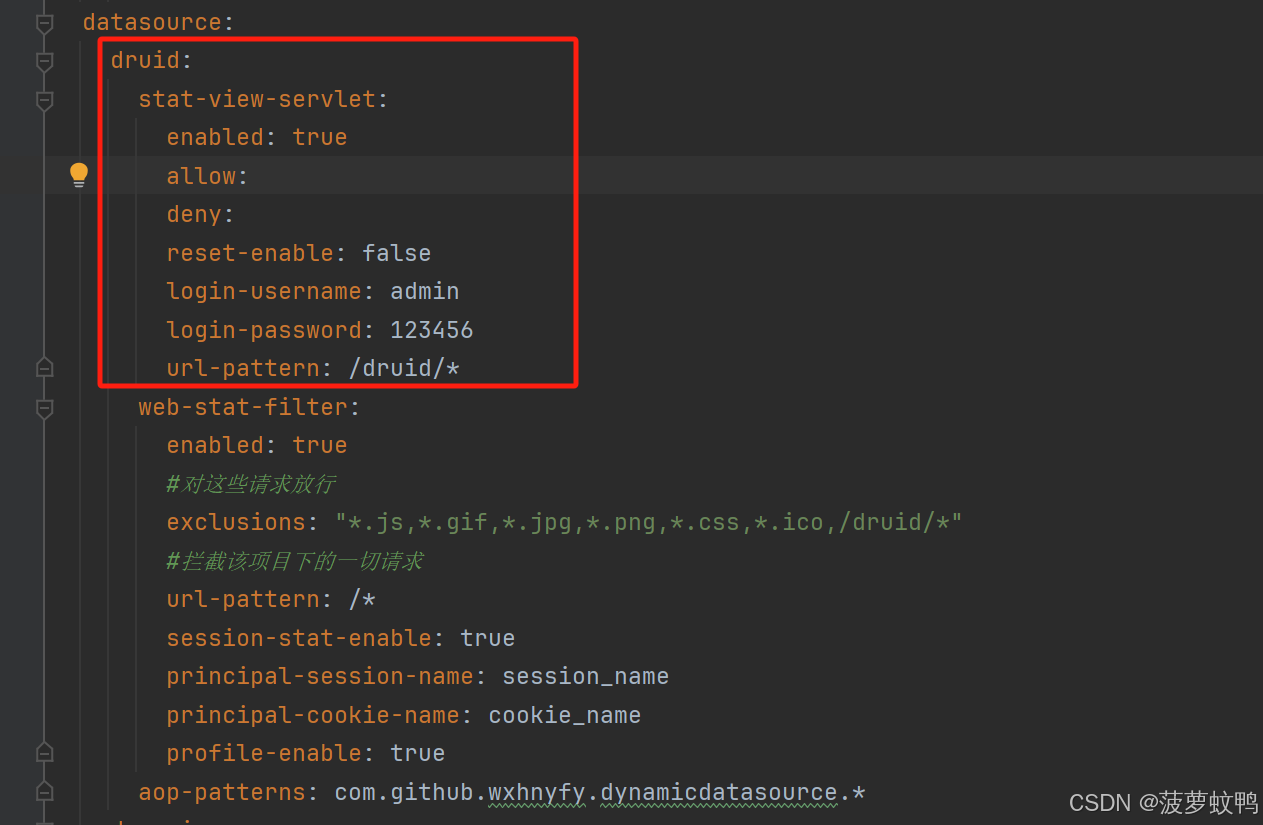
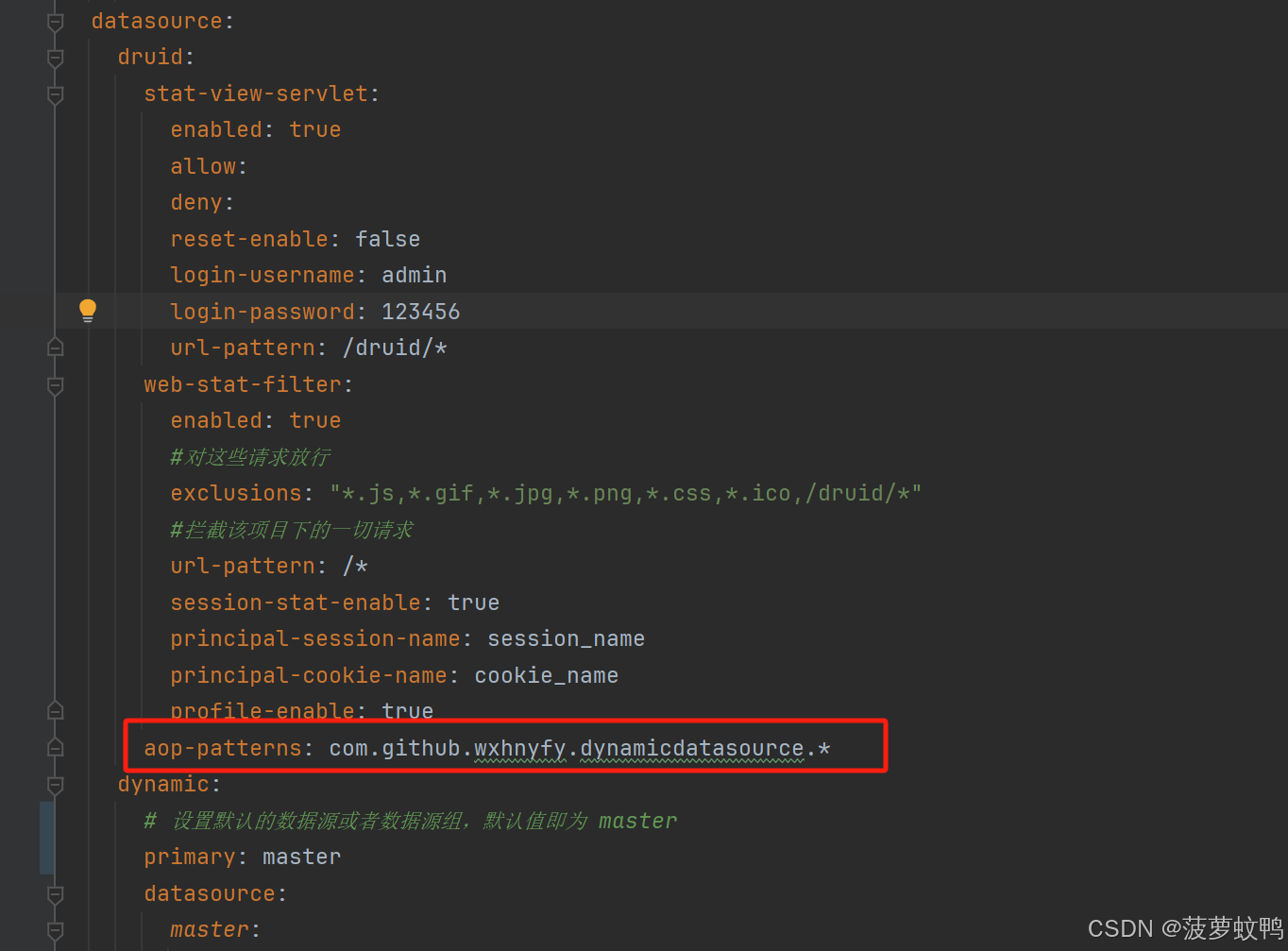
特别注意:多数据源 druid 要配置到每一个数据源里面
spring:application:name: DynamicDatasourcedatasource:druid:stat-view-servlet:enabled: trueallow:deny:reset-enable: falselogin-username: adminlogin-password: 123456url-pattern: /druid/*web-stat-filter:enabled: true#对这些请求放行exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"#拦截该项目下的一切请求url-pattern: /*session-stat-enable: trueprincipal-session-name: session_nameprincipal-cookie-name: cookie_nameprofile-enable: true# 包匹配,表示匹配以com.github.wxhnyfy.dynamicdatasource开头的包名,多个用逗号隔开aop-patterns: com.github.wxhnyfy.dynamicdatasource.*dynamic:primary: master # 设置默认的数据源或者数据源组,默认值即为 masterdatasource:master:#设置默认的数据源driverClassName: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/region?autoReconnect=true&useUnicode=true&characterEncoding=utf8&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=GMT%2B8username: rootpassword: 123456type: com.alibaba.druid.pool.DruidDataSource# druid连接池设置druid:# 配置初始化线程数initialSize: 5# 最小线程数minIdle: 5# CPU核数+1,也可以大些但不要超过20,数据库加锁时连接过多性能下降maxActive: 11# 最大等待时间,内网:800,外网:1200(三次握手1s)maxWait: 60000# 连接可空闲存活时间(ms)timeBetweenEvictionRunsMillis: 60000# 连接保持空闲而不被驱逐的最长存活时间(ms)minEvictableIdleTimeMillis: 300000# 用来检测连接是否有效的sql,如果validationQuery为空,那么testOnBorrow、testOnReturn、testWhileIdle这三个参数都不会起作用validationQuery: SELECT 1# 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效;testWhileIdle: true# 建议配置为false,申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。testOnBorrow: false# 建议配置为false,归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能;testOnReturn: false# PSCache对支持游标的数据库性能提升巨大,oracle建议开启,mysql下建议关闭poolPreparedStatements: false# 保持minIdle数量的长连接keepAlive: true# 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。# 在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100。缺省值为-1# 开启poolPreparedStatments后生效maxPoolPreparedStatementPerConnectionSize: 20# 是否合并多个DruidDataSource的监控数据useGlobalDataSourceStat: true# 配置监控统计拦截的filtersfilters: stat,wall,slf4jstat:logSlowSql: trueslowSqlMillis: 2000mergeSql: truedbType: mysqlwall:# 可配置项参考类:com.alibaba.druid.wall.WallConfigmulti-statement-allow: truealter-table-allow: falsedrop-table-allow: falseslf4j:# 只有当 isStatementExecutableSqlLogEnable() isStatementLogEnabled() 都为ture的情况才打印 可执行sql# 在{# LogFilter#logExecutableSql }使用statement-executable-sql-log-enable: true# 在{# LogFilter#logExecutableSql }使用statement-log-enabled: truestatement-create-after-log-enabled: falsestatement-log-error-enabled: trueresult-set-log-enabled: false#statementPrepareAfterLogEnable# 准备好的sql语句打印(此时为执行前)未进行参数拼接statement-prepare-after-log-enabled: false#isStatementParameterSetLogEnabled#打印参数statement-parameter-set-log-enabled: false#statementExecuteAfterLogEnable#sql语句执行完成后打印(执行后)未进行参数拼接statement-execute-after-log-enabled: false#statementCloseAfterLogEnablestatement-close-after-log-enabled: false#不打印清除参数日志statement-parameter-clear-log-enable: false# 通过connectProperties属性来打开mergeSql功能;慢SQL记录connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=2000slave:url: jdbc:mysql://localhost:3307/region?autoReconnect=true&useUnicode=true&characterEncoding=utf8&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=GMT%2B8username: rootpassword: 123456driver-class-name: com.mysql.cj.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSource# druid连接池设置druid:# 配置初始化线程数initialSize: 5# 最小线程数minIdle: 5# CPU核数+1,也可以大些但不要超过20,数据库加锁时连接过多性能下降maxActive: 11# 最大等待时间,内网:800,外网:1200(三次握手1s)maxWait: 60000# 连接可空闲存活时间(ms)timeBetweenEvictionRunsMillis: 60000# 连接保持空闲而不被驱逐的最长存活时间(ms)minEvictableIdleTimeMillis: 300000# 用来检测连接是否有效的sql,如果validationQuery为空,那么testOnBorrow、testOnReturn、testWhileIdle这三个参数都不会起作用validationQuery: SELECT 1# 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效;testWhileIdle: true# 建议配置为false,申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。testOnBorrow: false# 建议配置为false,归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能;testOnReturn: false# PSCache对支持游标的数据库性能提升巨大,oracle建议开启,mysql下建议关闭poolPreparedStatements: false# 保持minIdle数量的长连接keepAlive: true# 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。# 在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100。缺省值为-1# 开启poolPreparedStatments后生效maxPoolPreparedStatementPerConnectionSize: 20# 是否合并多个DruidDataSource的监控数据useGlobalDataSourceStat: true# 配置监控统计拦截的filtersfilters: stat,wall,slf4jstat:logSlowSql: trueslowSqlMillis: 2000mergeSql: truedbType: mysqlwall:# 可配置项参考类:com.alibaba.druid.wall.WallConfigmulti-statement-allow: truealter-table-allow: falsedrop-table-allow: falseslf4j:# 只有当 isStatementExecutableSqlLogEnable() isStatementLogEnabled() 都为ture的情况才打印 可执行sql# 在{# LogFilter#logExecutableSql }使用statement-executable-sql-log-enable: true# 在{# LogFilter#logExecutableSql }使用statement-log-enabled: truestatement-create-after-log-enabled: falsestatement-log-error-enabled: trueresult-set-log-enabled: false#statementPrepareAfterLogEnable# 准备好的sql语句打印(此时为执行前)未进行参数拼接statement-prepare-after-log-enabled: false#isStatementParameterSetLogEnabled#打印参数statement-parameter-set-log-enabled: false#statementExecuteAfterLogEnable#sql语句执行完成后打印(执行后)未进行参数拼接statement-execute-after-log-enabled: false#statementCloseAfterLogEnablestatement-close-after-log-enabled: false#不打印清除参数日志statement-parameter-clear-log-enable: false# 通过connectProperties属性来打开mergeSql功能;慢SQL记录connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=2000
3、多数据源 Duid 自动装配详解
3.1、自动装配 spring.datasource.dynamic
由于我们引入了 dynamic-datasource-spring-boot-starter,启动时会优先自动装配 com.baomidou.dynamic.datasource.spring.boot.autoconfigure.DynamicDataSourceAutoConfiguration,并且在类 com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure 之前装配
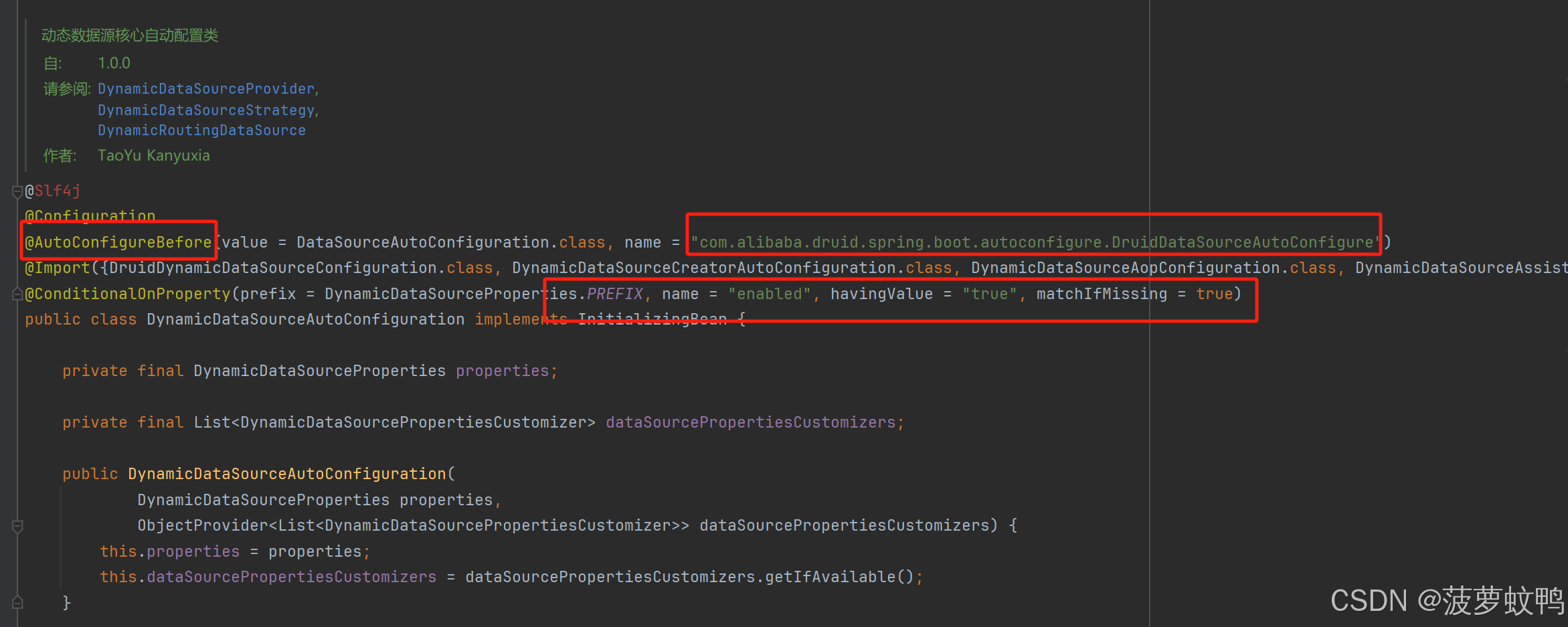
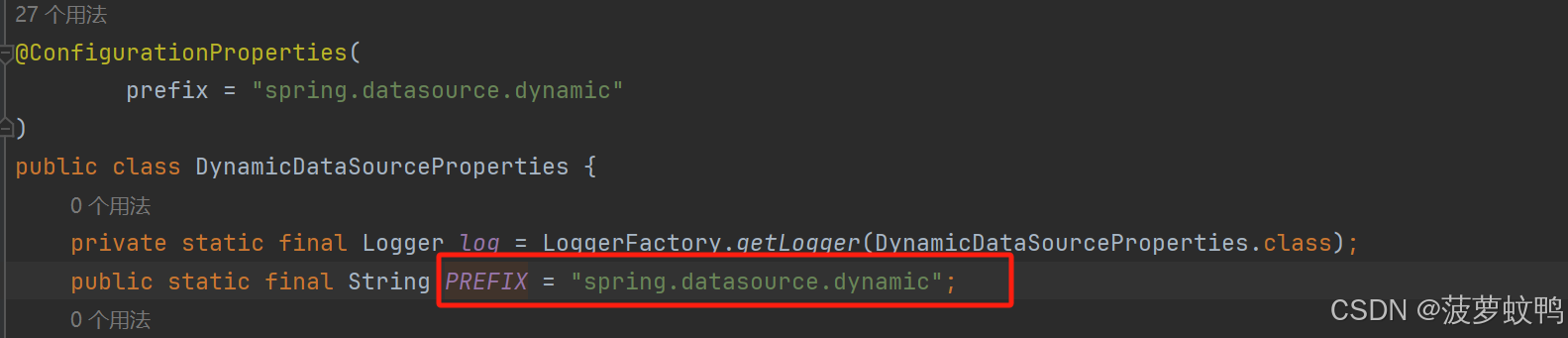
会自动装配以下属性,参考类 com.baomidou.dynamic.datasource.spring.boot.autoconfigure.DynamicDataSourceProperties,datasource 就是我们配置的多数据源
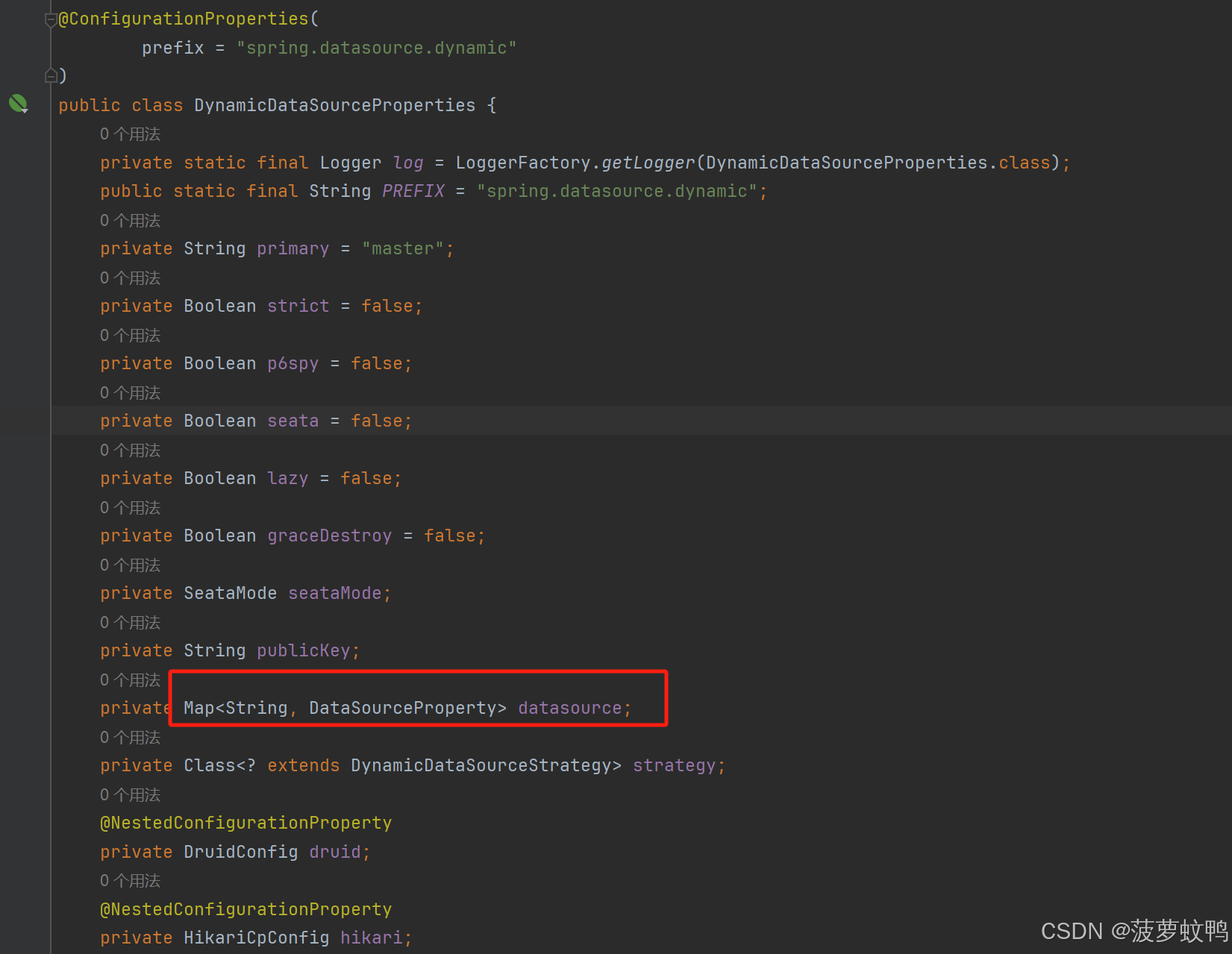
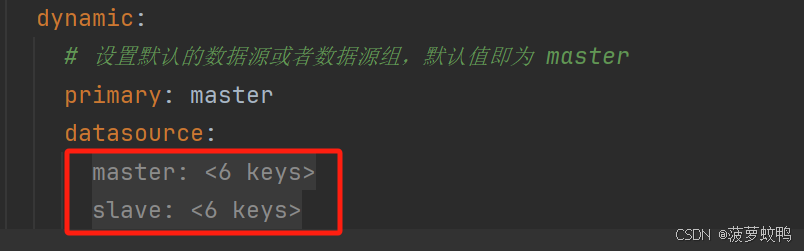
3.2、自动装配多数据源 datasource
参考类 com.baomidou.dynamic.datasource.creator.DataSourceProperty
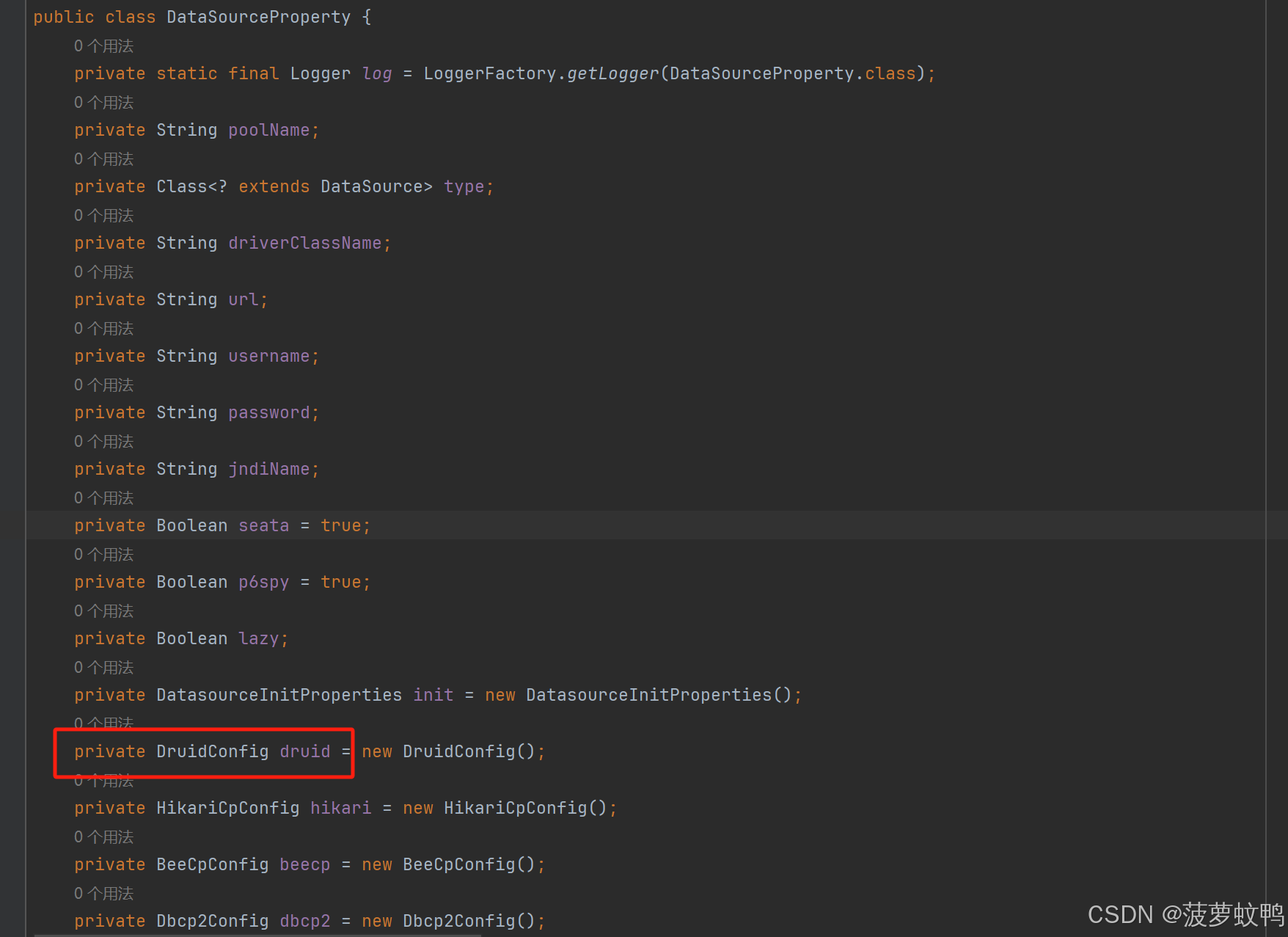
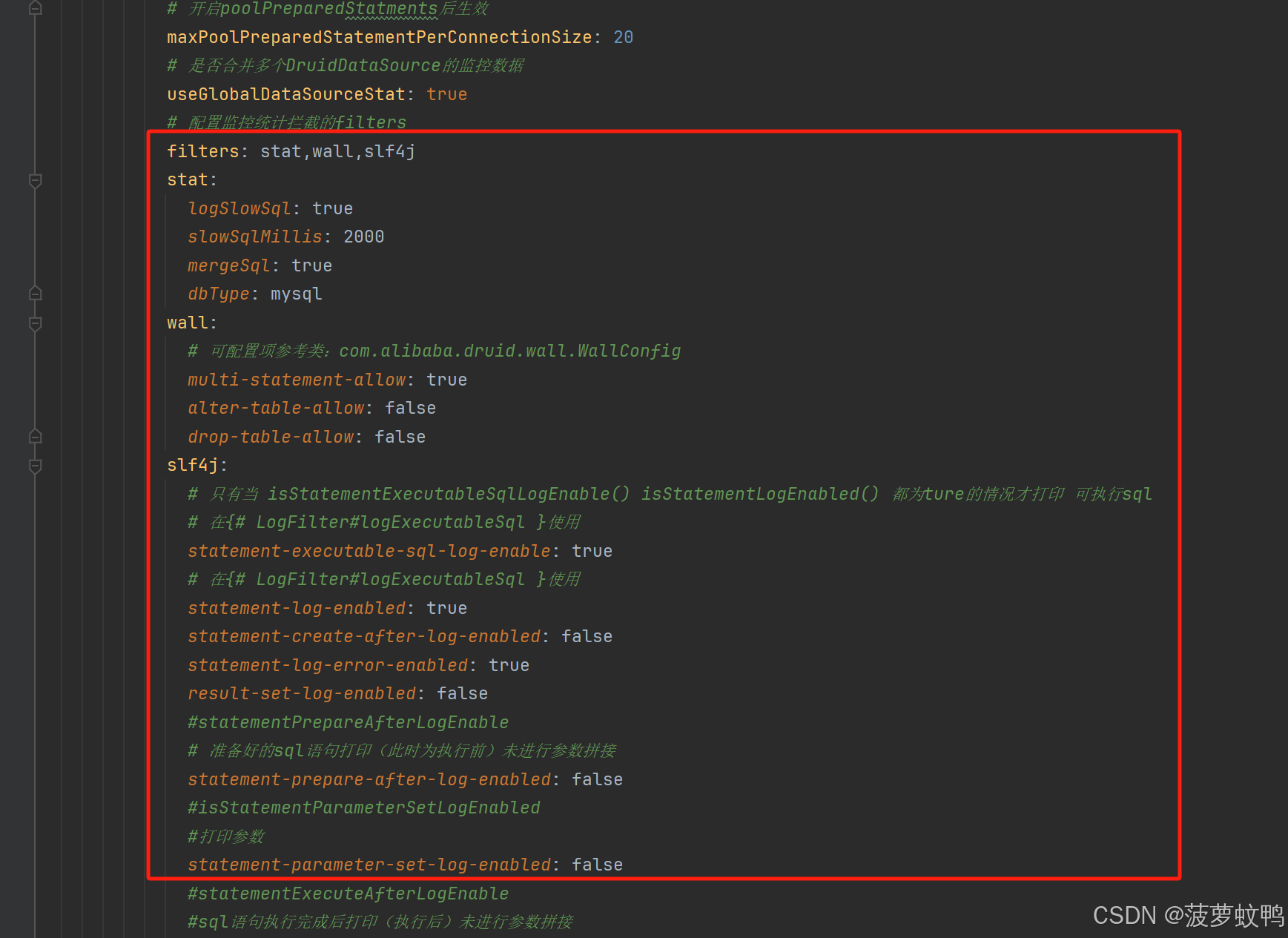
3.3、自动装配每个数据源下的 duid 配置
这个配置和 Druid 的层级稍有一些不同
参考类 com.baomidou.dynamic.datasource.creator.druid.DruidConfig
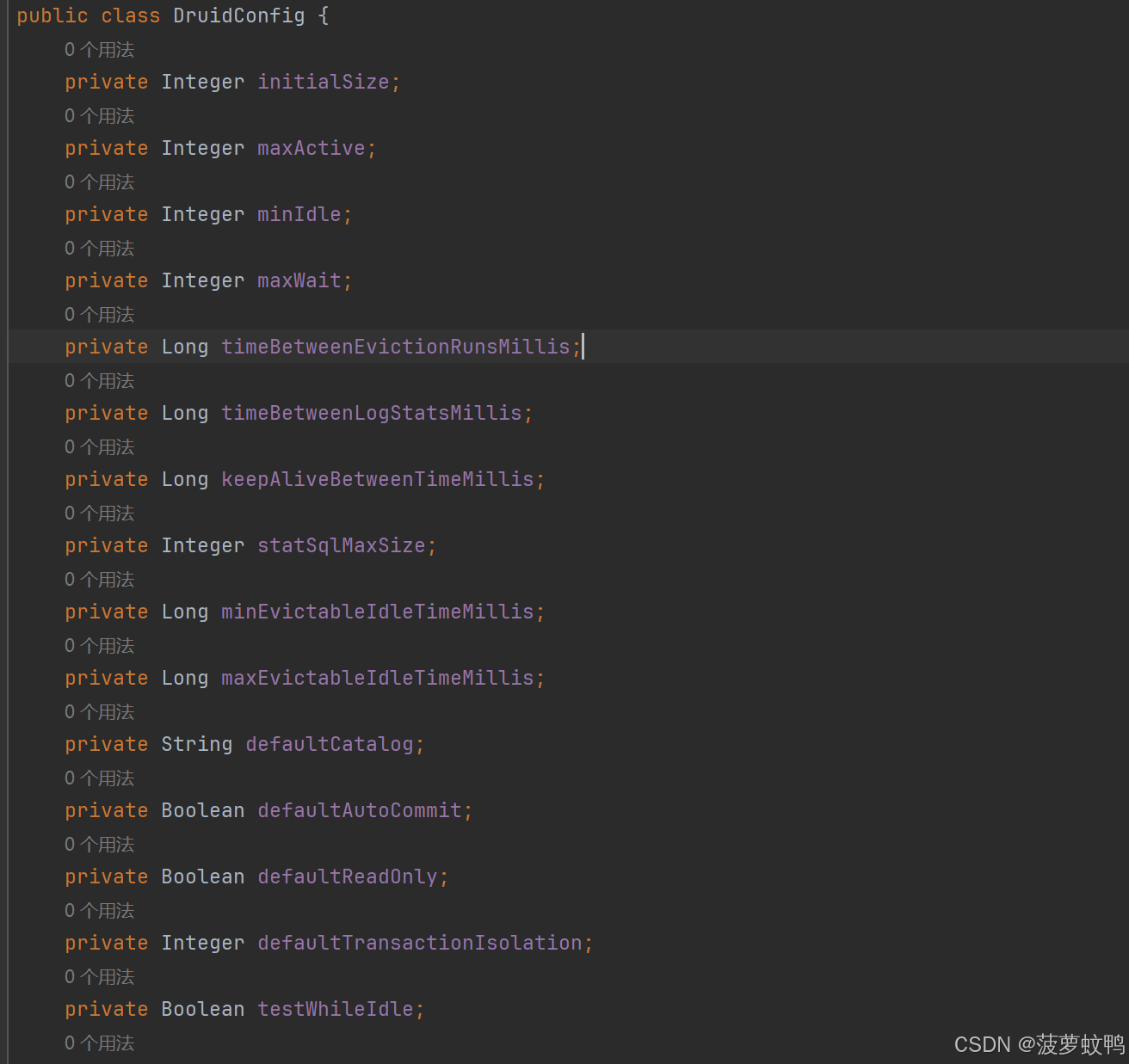
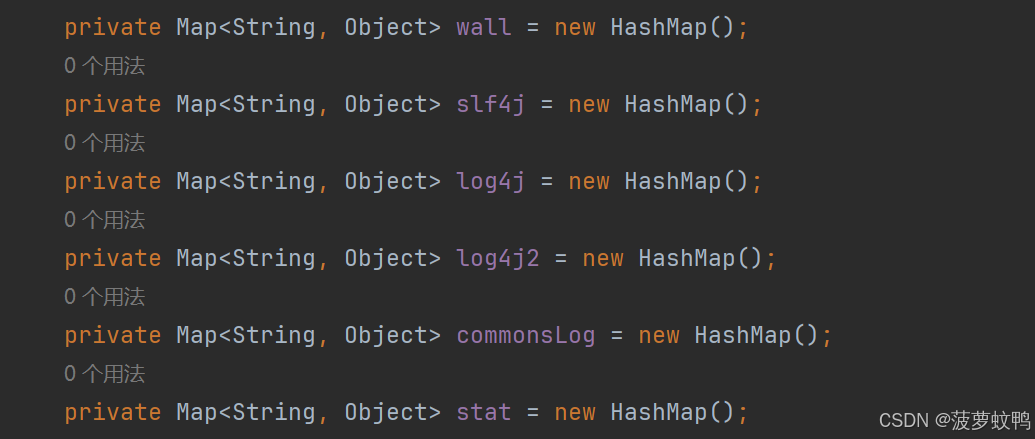
数据源的 Filter 配置

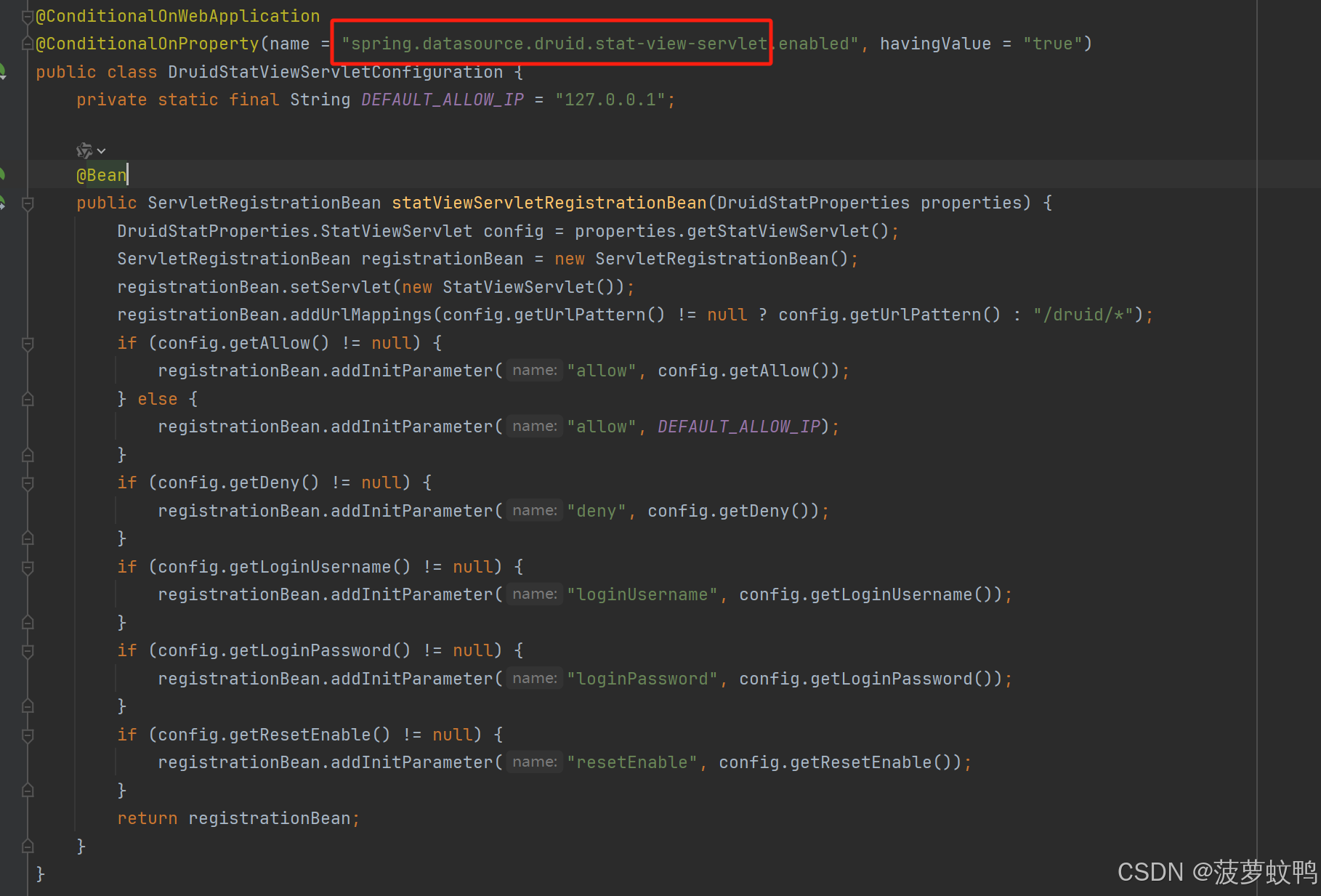
3.4、自动装配 StatViewServlet
参考类:com.alibaba.druid.spring.boot.autoconfigure.stat.DruidStatViewServletConfiguration
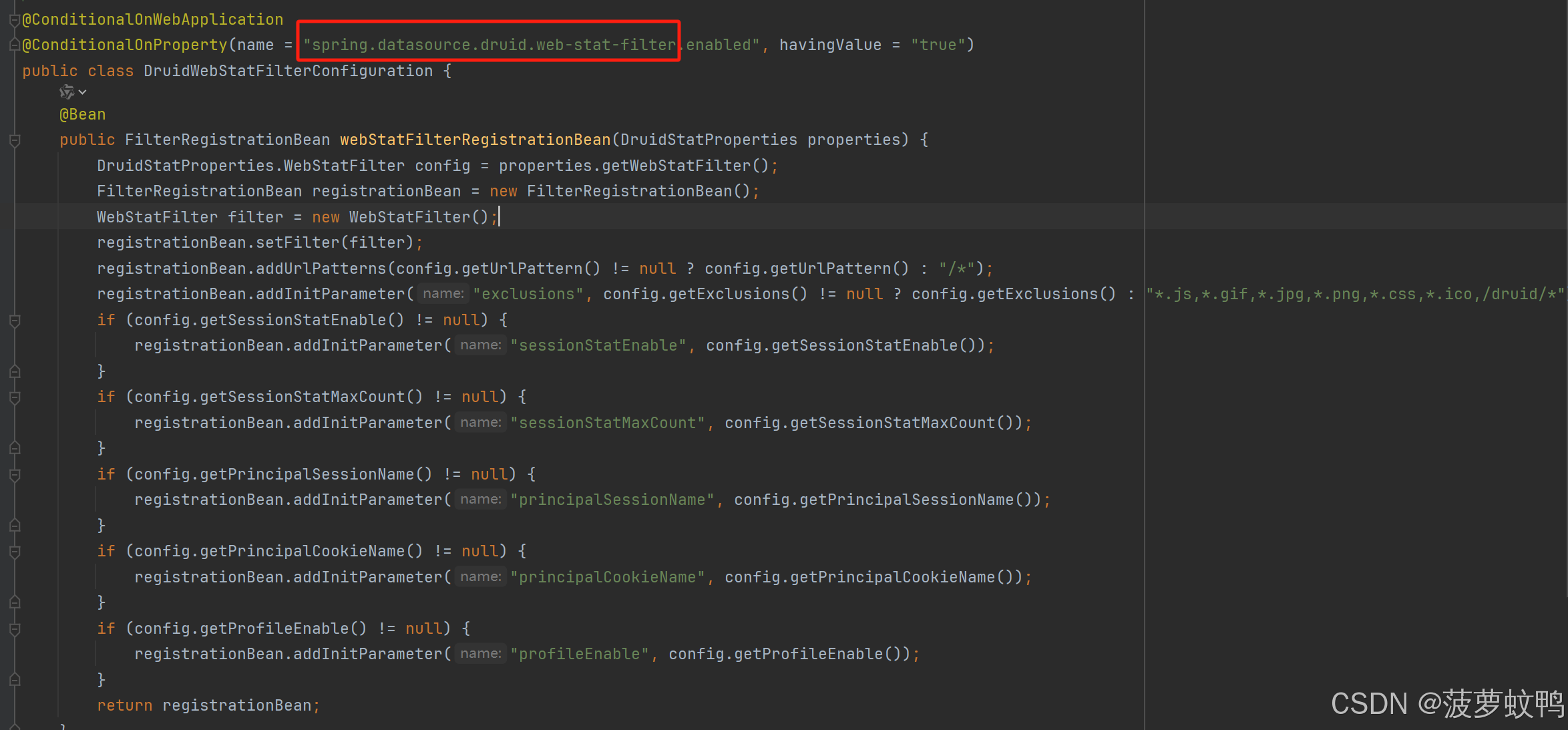
3.5、自动装配 WebStatFilter
参考类:com.alibaba.druid.spring.boot.autoconfigure.stat.DruidWebStatFilterConfiguration
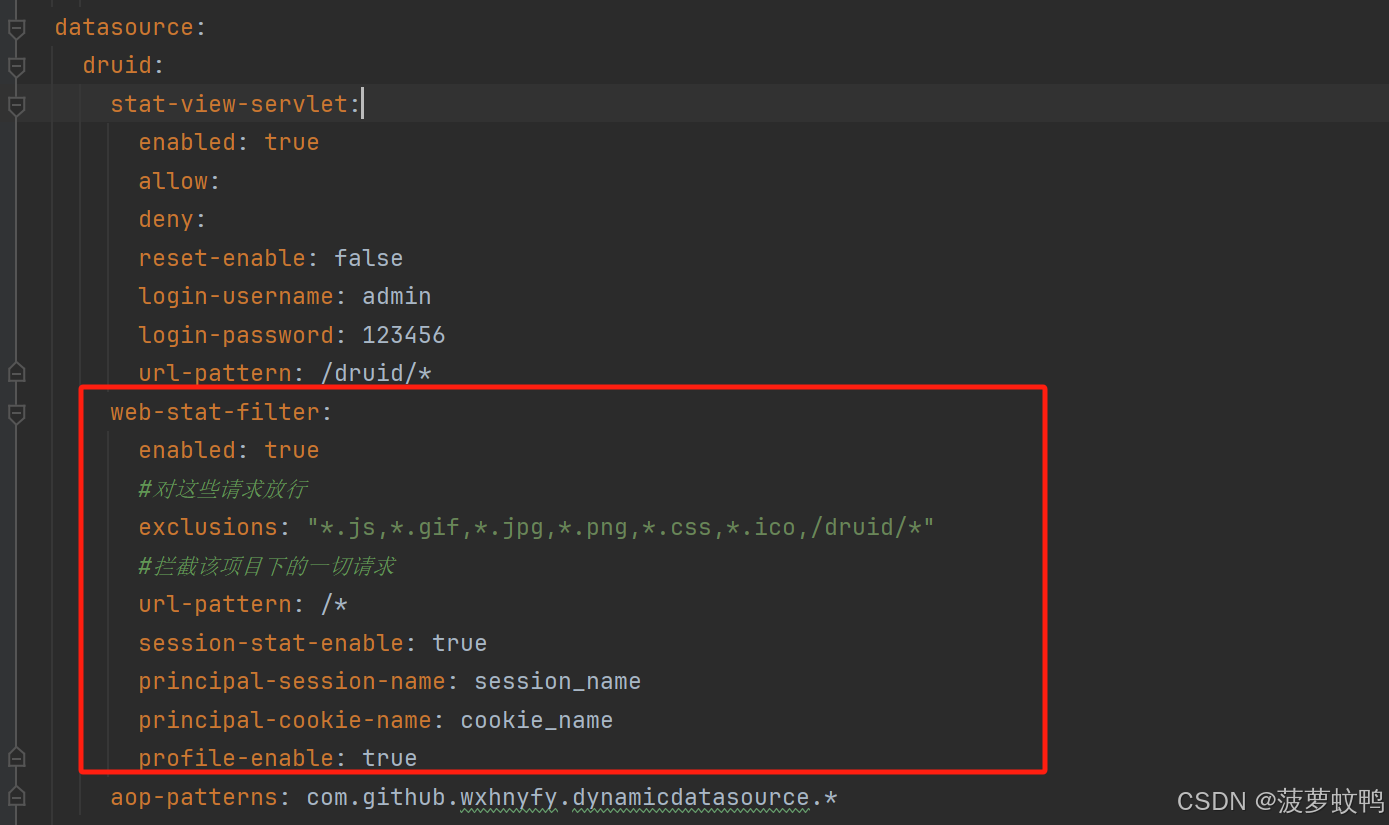
3.6、自动装配 AopPatterns
参考类:com.alibaba.druid.spring.boot.autoconfigure.stat.DruidSpringAopConfiguration
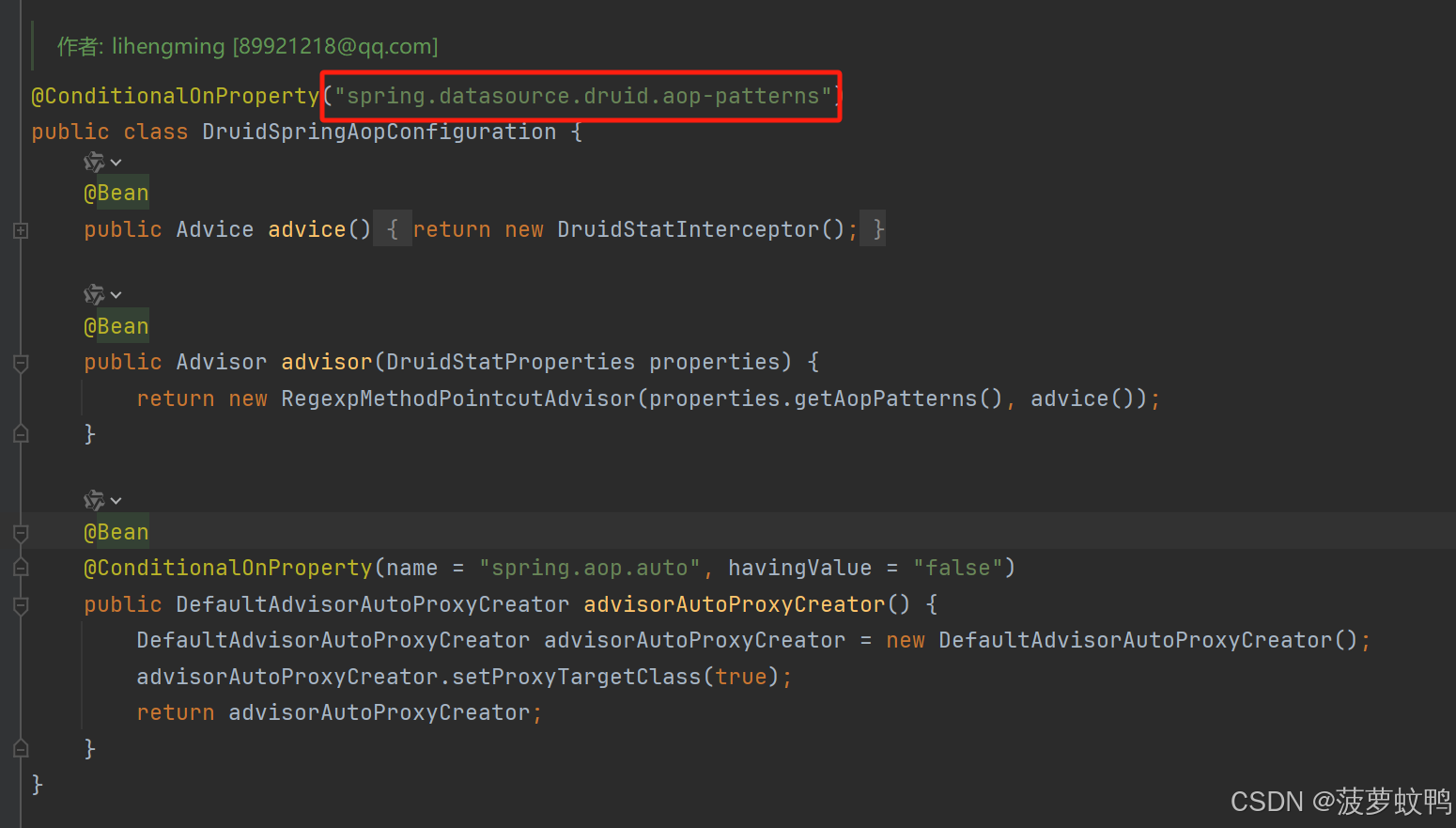
3.7、Filter 配置类
- wall: com.alibaba.druid.wall.WallConfig
- slf4j、log4j、log4j2、commonsLog: 四个日志 filter 只有实现不同,配置类都是同一个,com.alibaba.druid.filter.logging.LogFilter
- stat:com.alibaba.druid.filter.stat.StatFilter
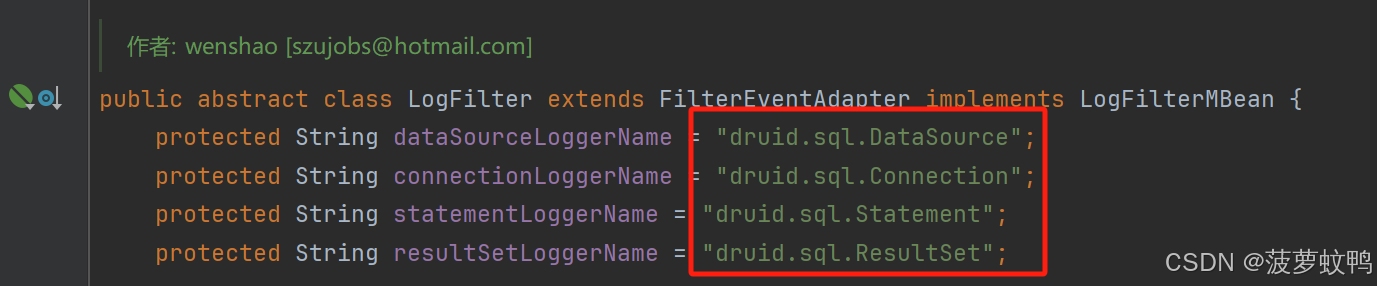
日志 Filter 要引入对应的依赖,Druid 的 LoggerName 在类 com.alibaba.druid.filter.logging LogFilter,配置日志打印级别时需要使用下面的 LoggerName
4、Druid 监控页面
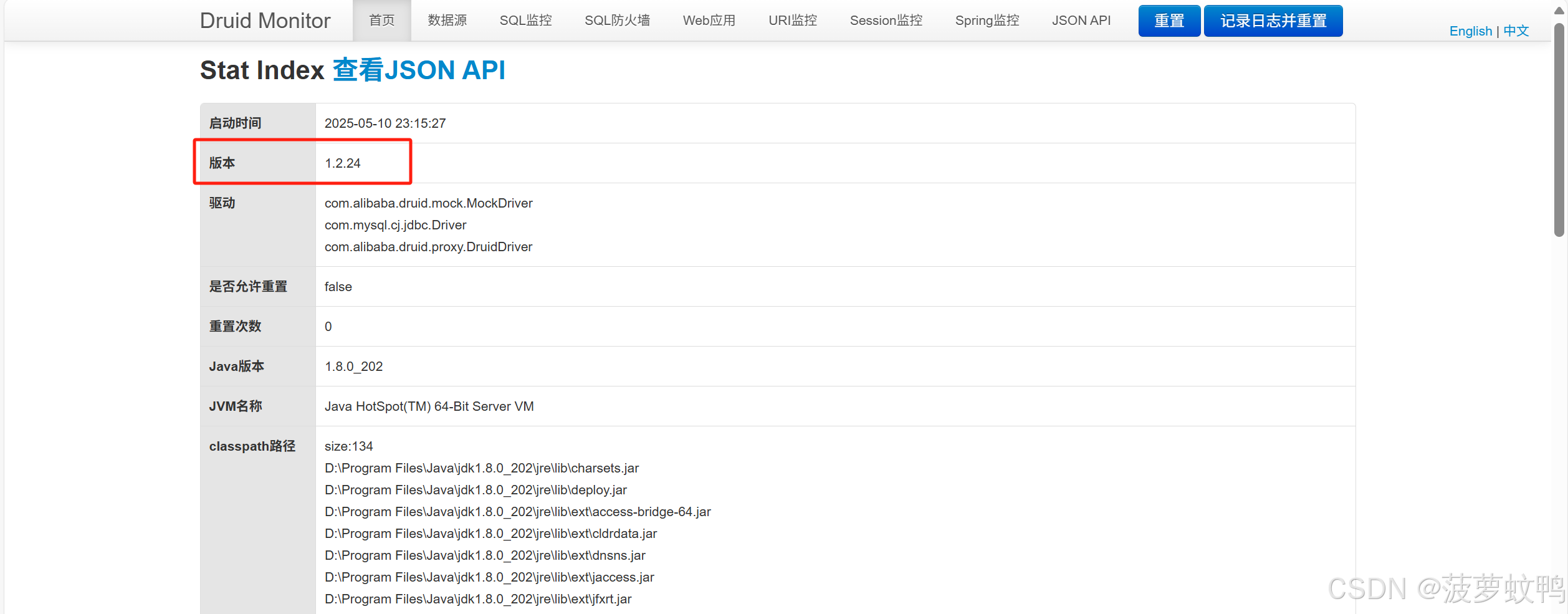
4.1、首页
访问地址:http://IP:端口/上下文/druid/index.html
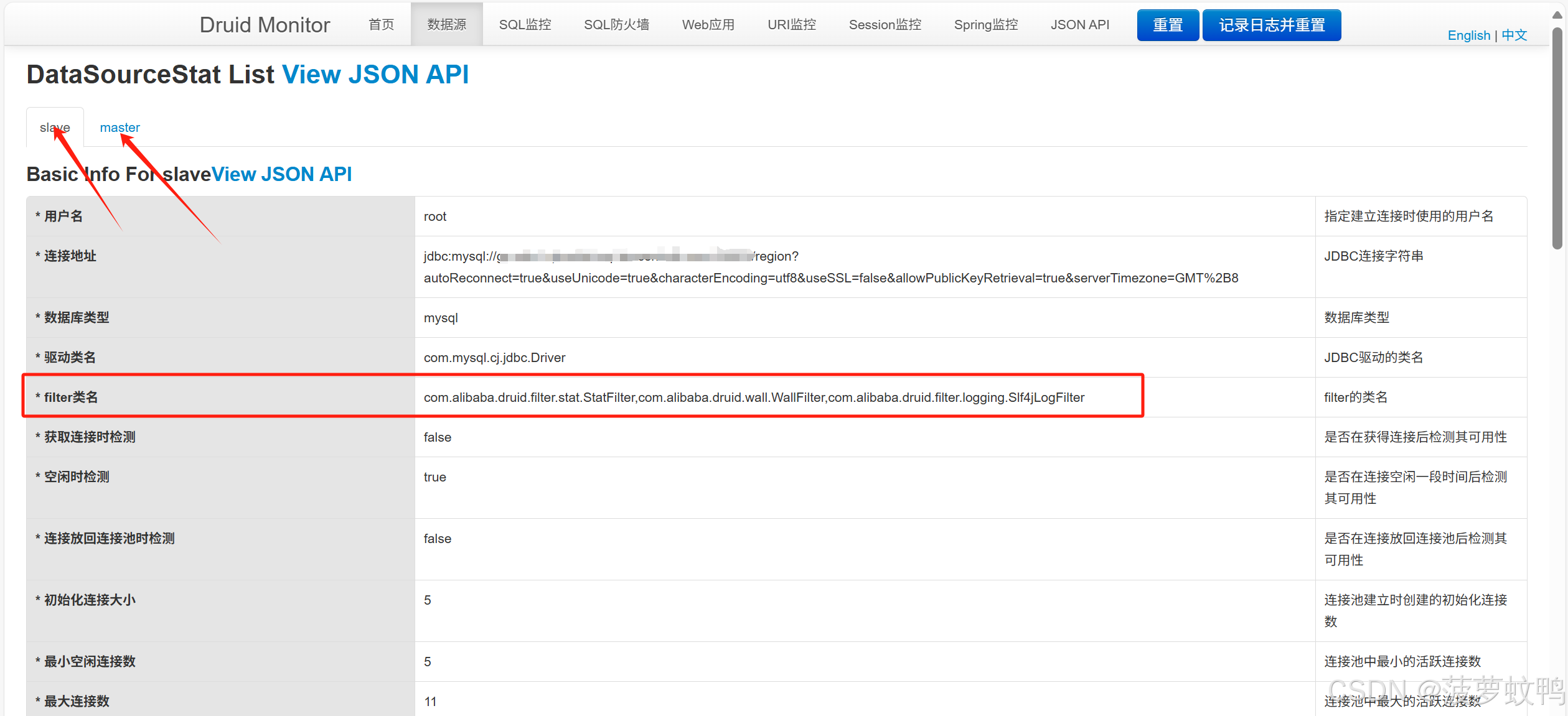
4.2、数据源列表
要看每一个数据源的 filter 类名,看一下是否和启用的 Filter 一致,再看一起其他的配置是否能正常读取
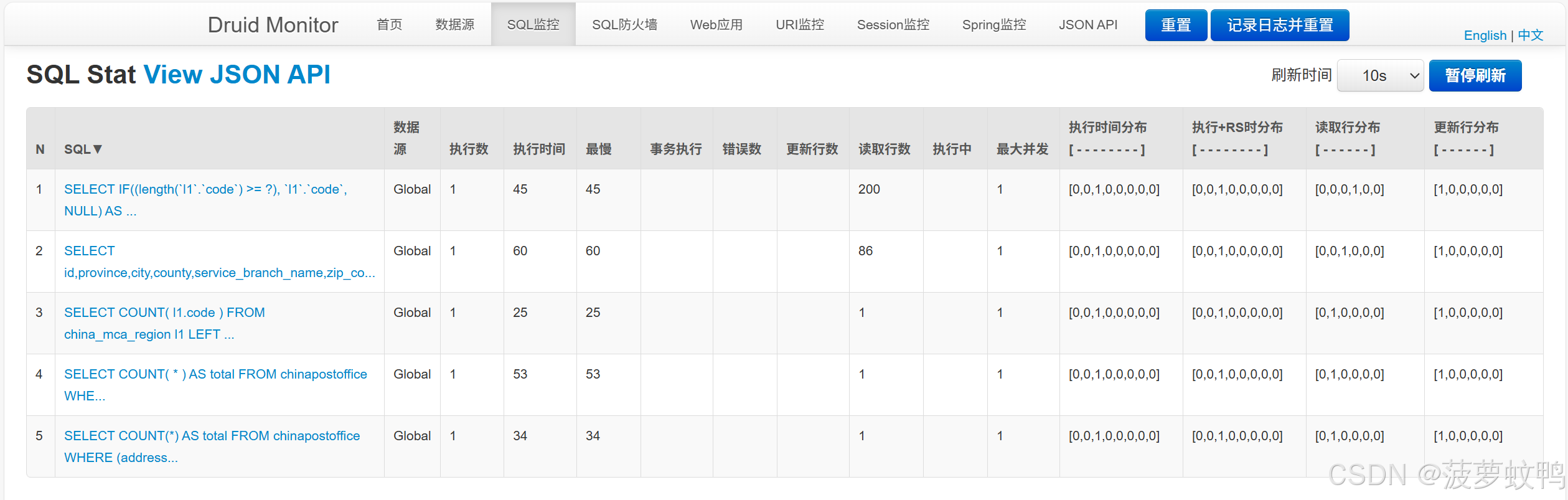
4.2、SQL 监控
执行过 SQL 后,Druid 能对 SQL 进行监控,但是不能区分是哪个数据源执行的。由于我们开启了SQL合并,所以看到的SQL都会带有占位符
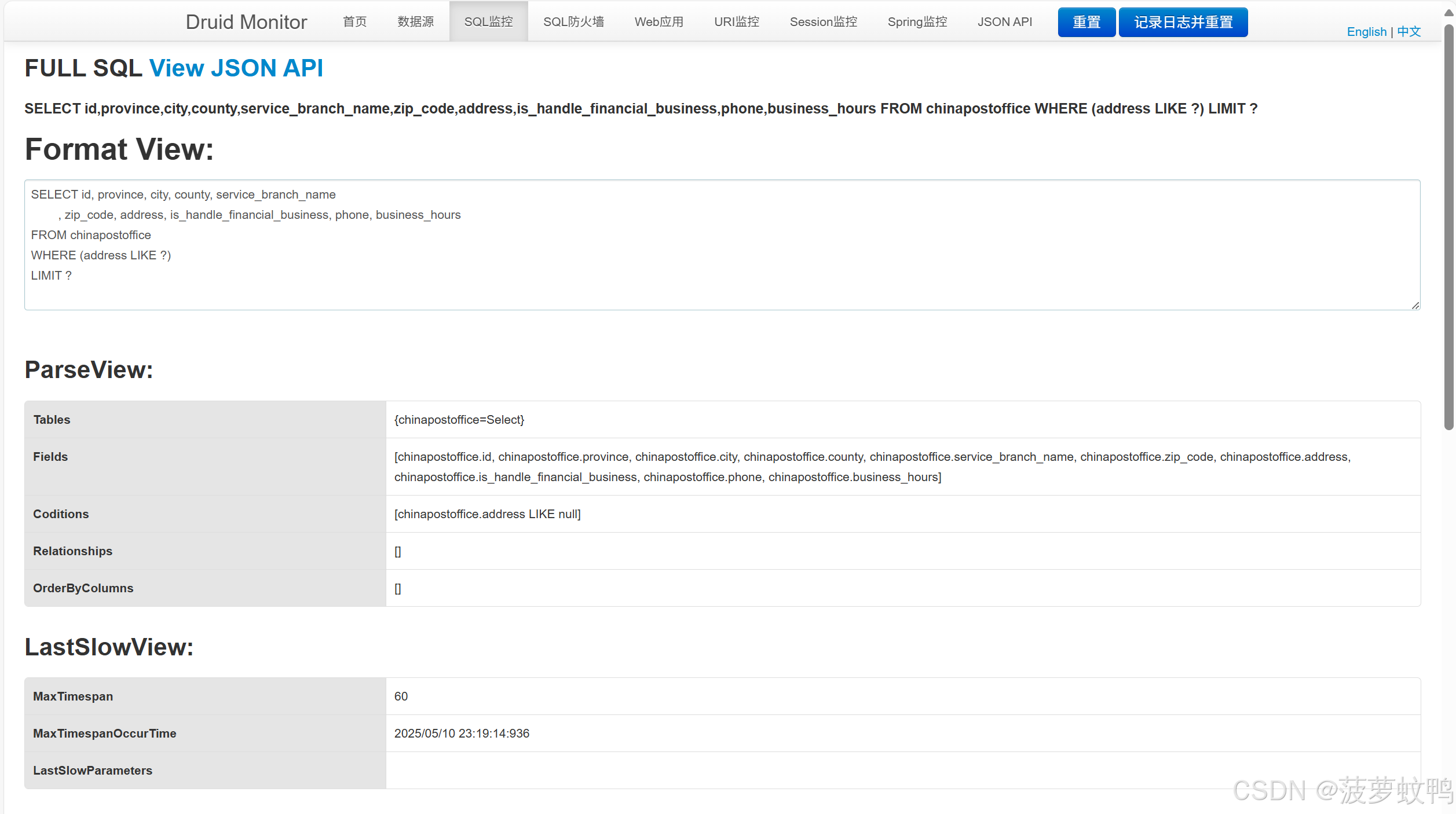
点击去能看到每条SQL的执行详情。
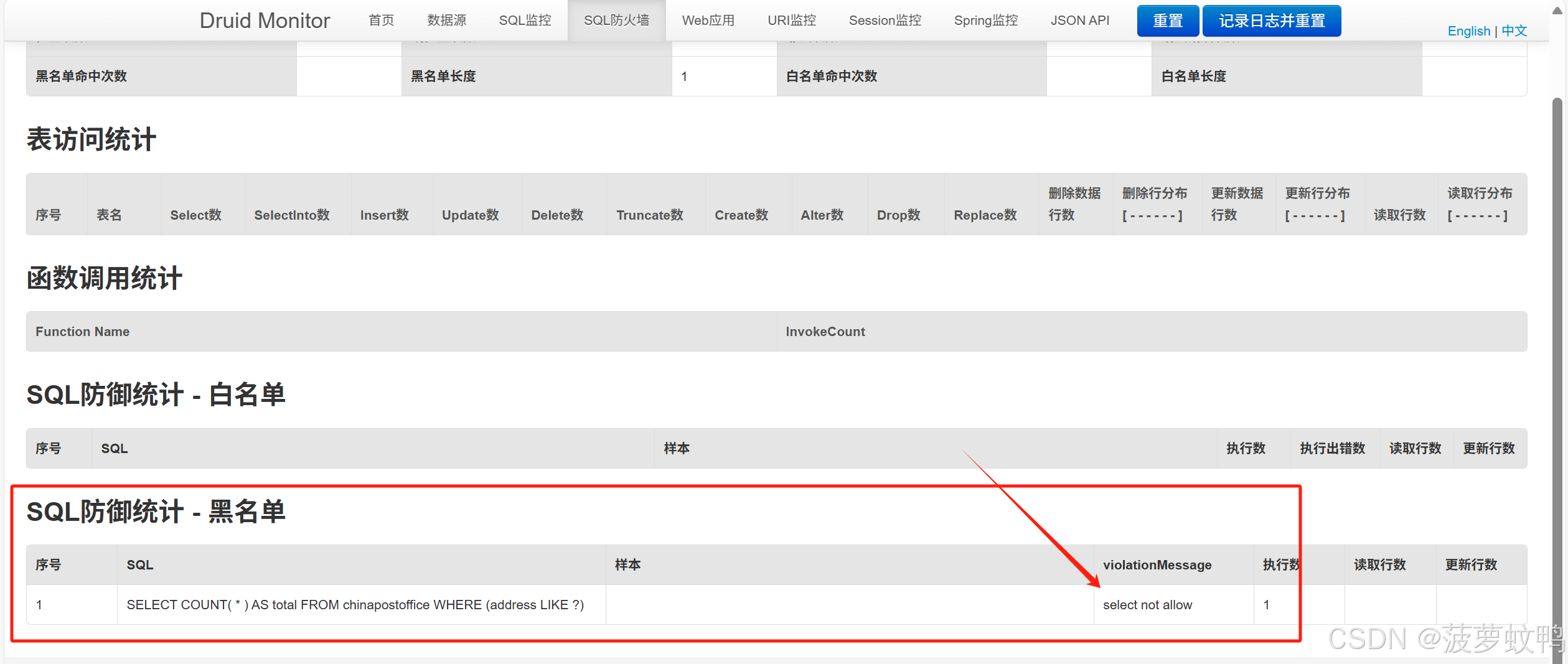
4.3、SQL 防火墙
能对黑白名单进行统计,但是不能区分是哪个数据源执行的
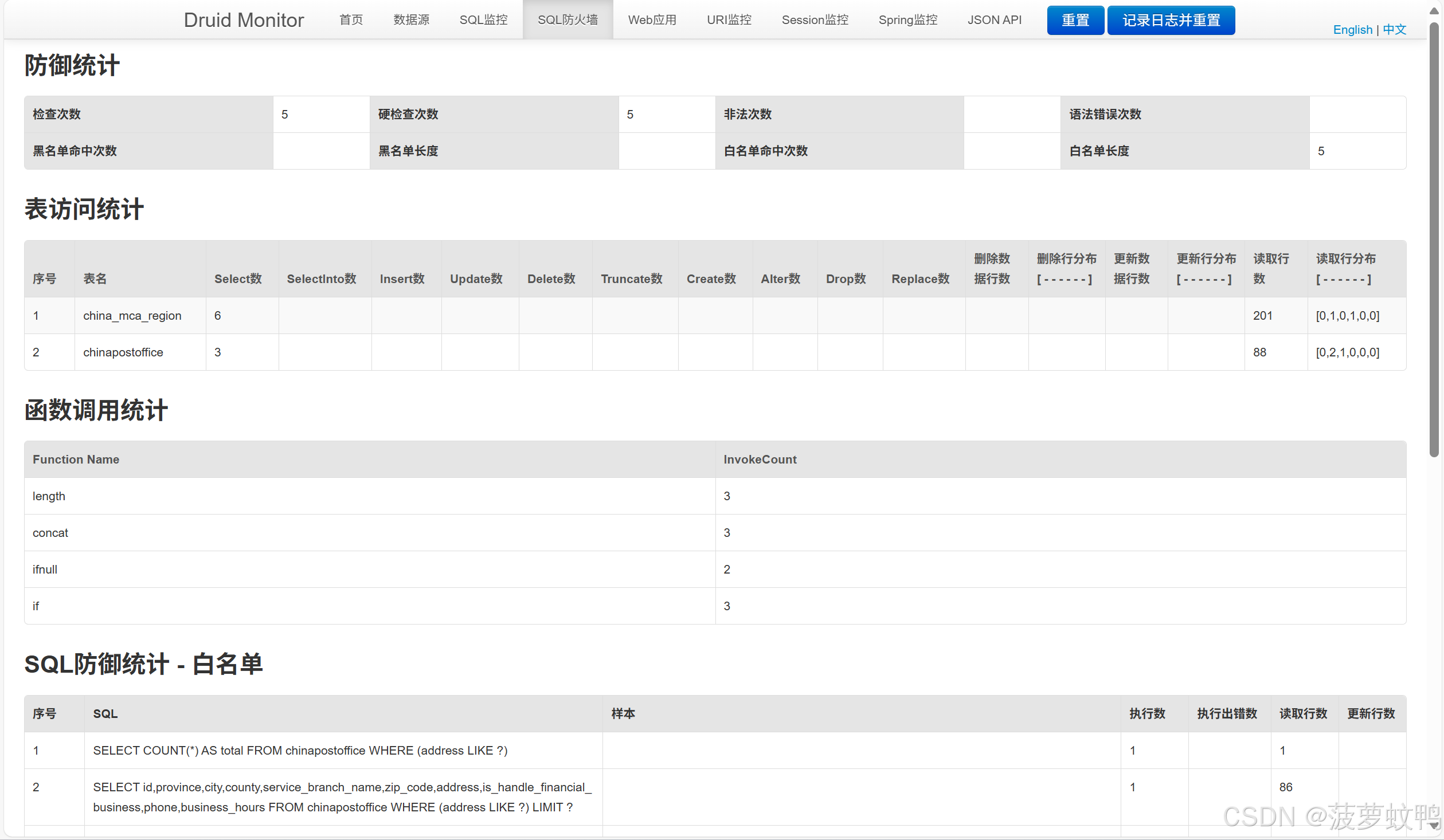
示例,我们在 spring.datasource.dynamic.datasource.master.wall 配置了不能执行 select 语句
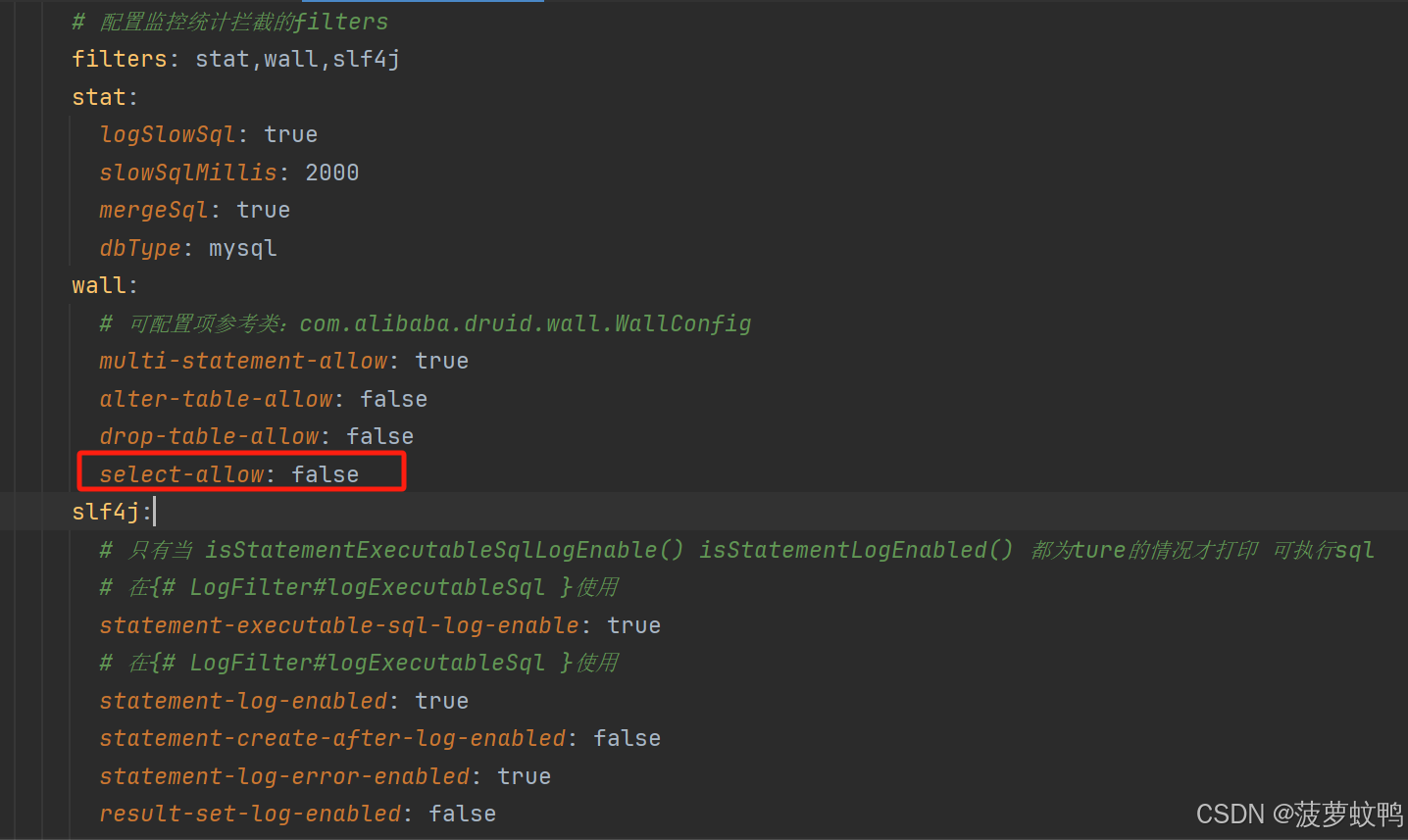
SQL 会执行报错
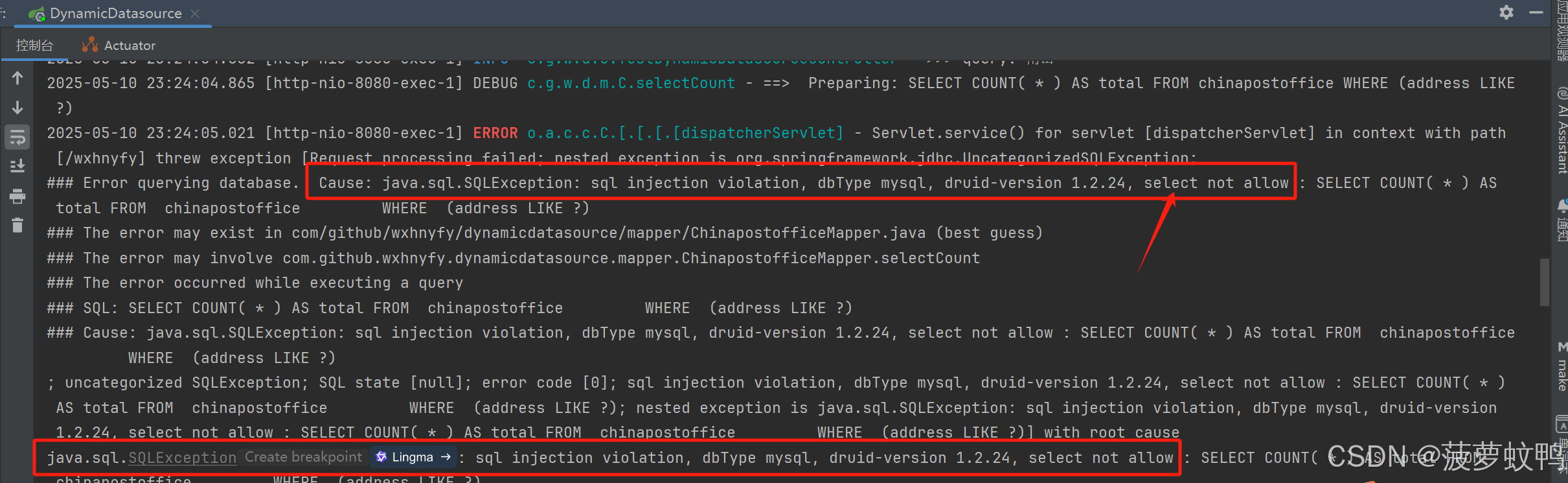
能正常监控到黑名单 SQL
4.4、Web 应用

4.5、URI 监控
能监控到执行SQL的请求

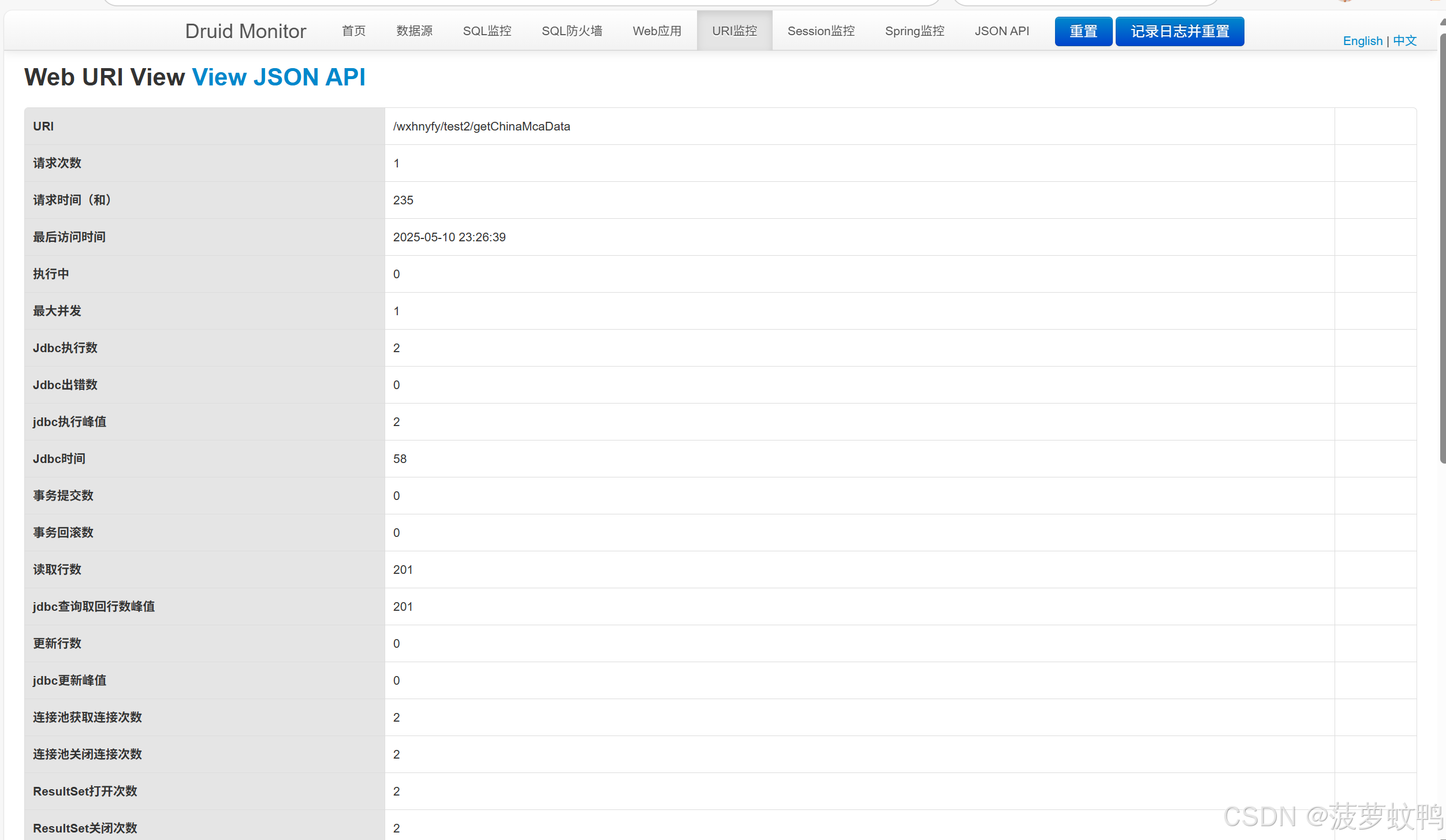
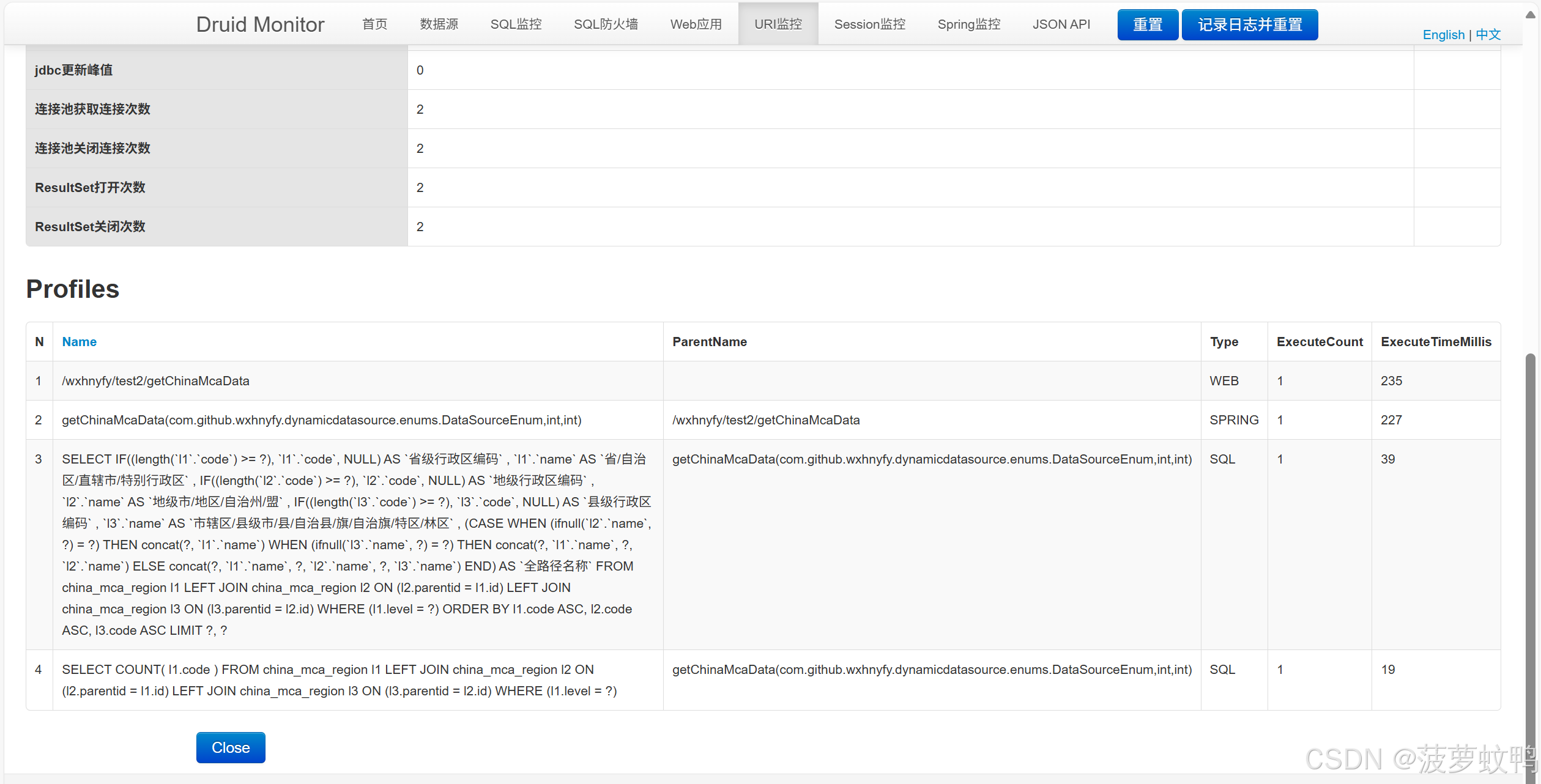
4.6、Web Session 监控

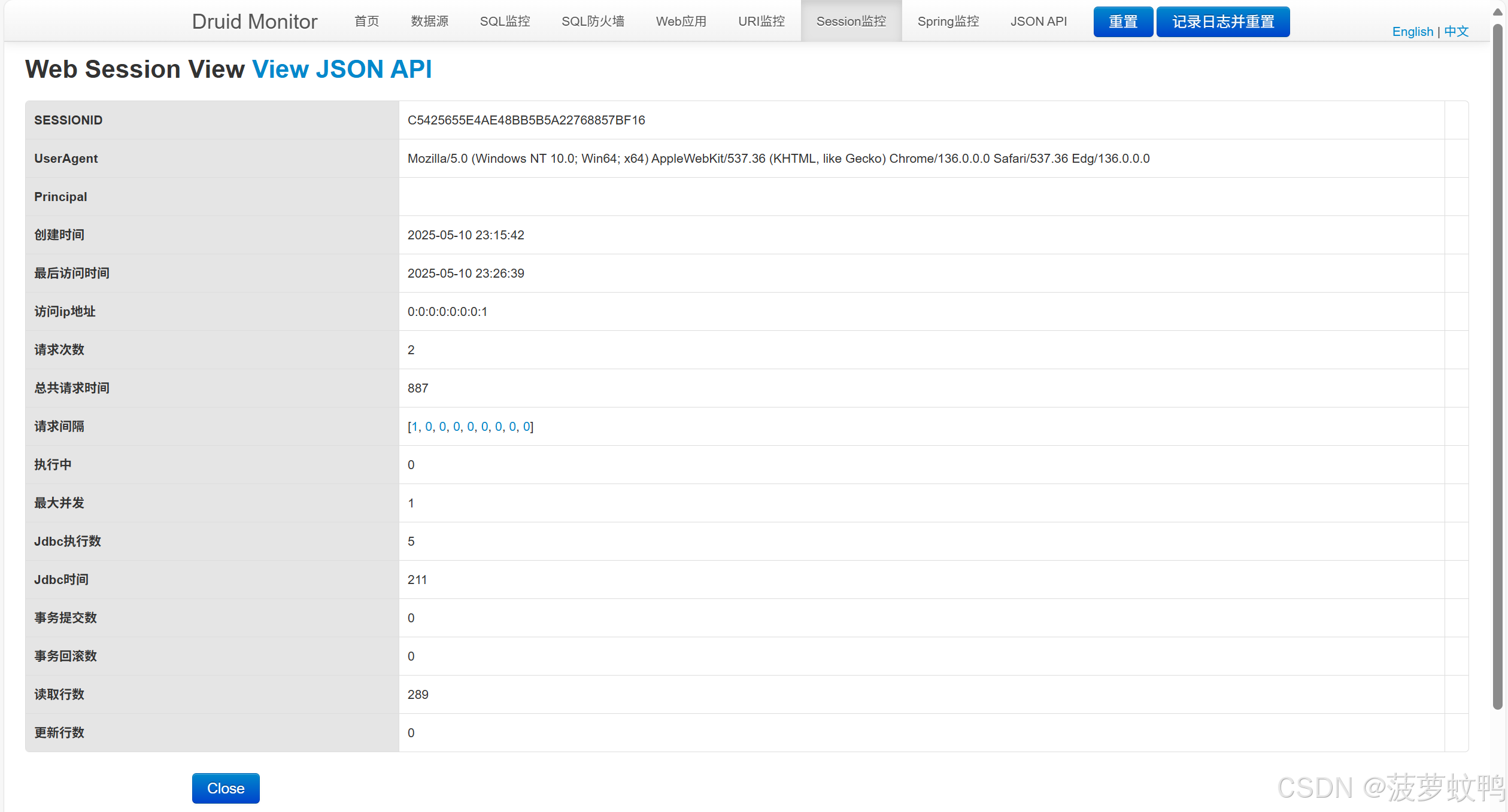
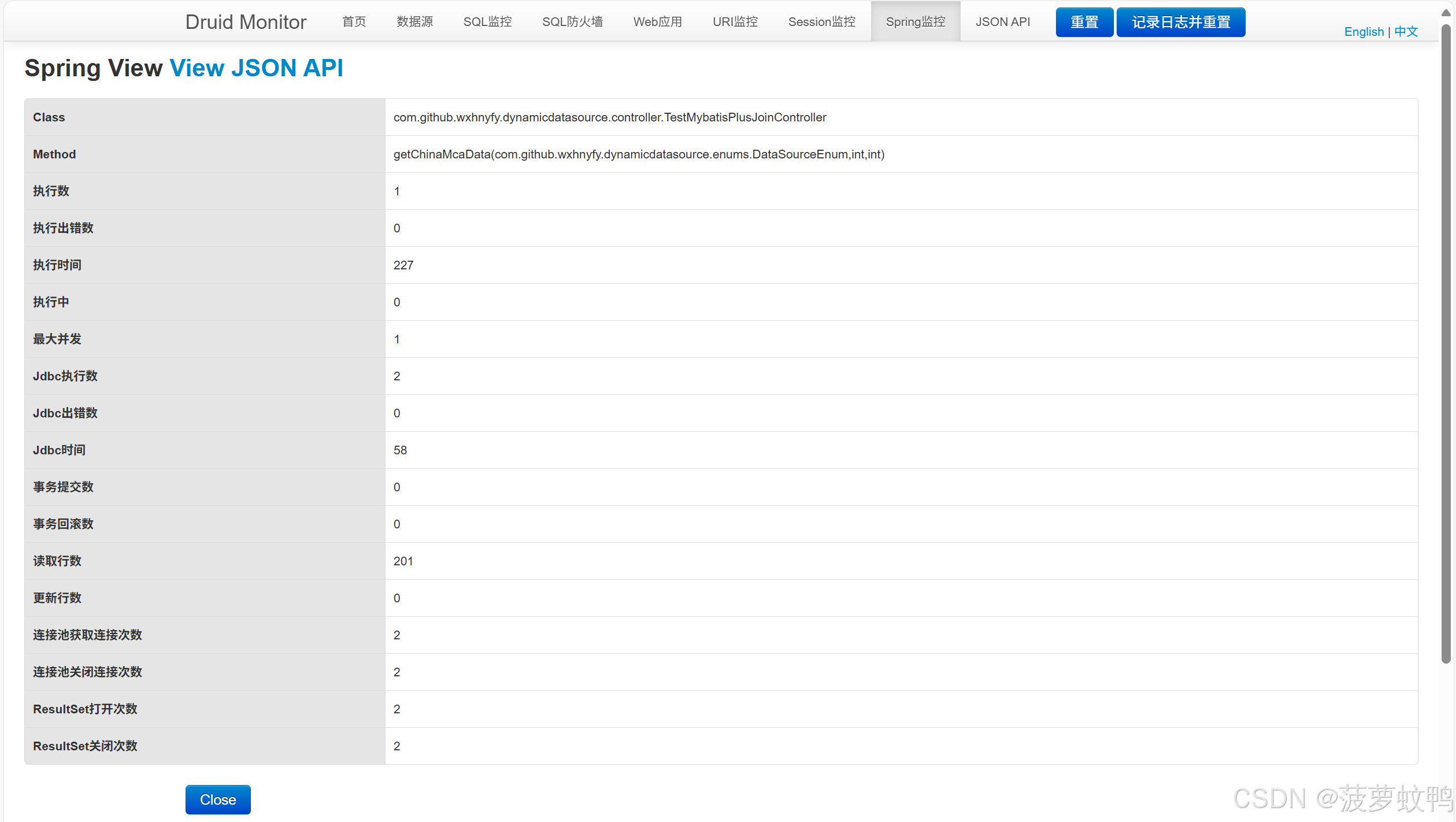
4.7、Spring 监控
根据 aop-pattern 配置包名进行监控
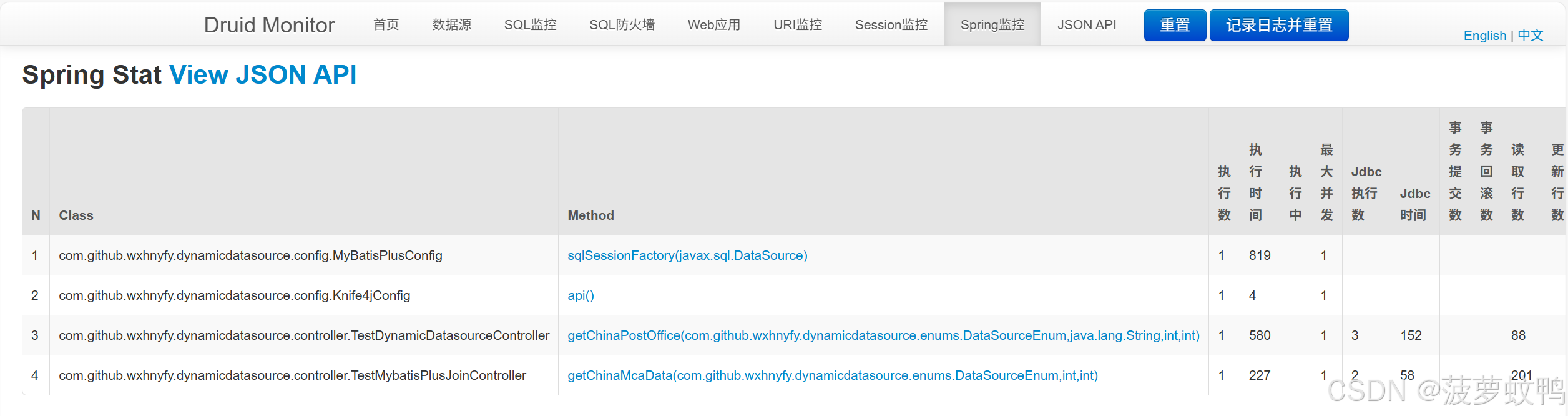
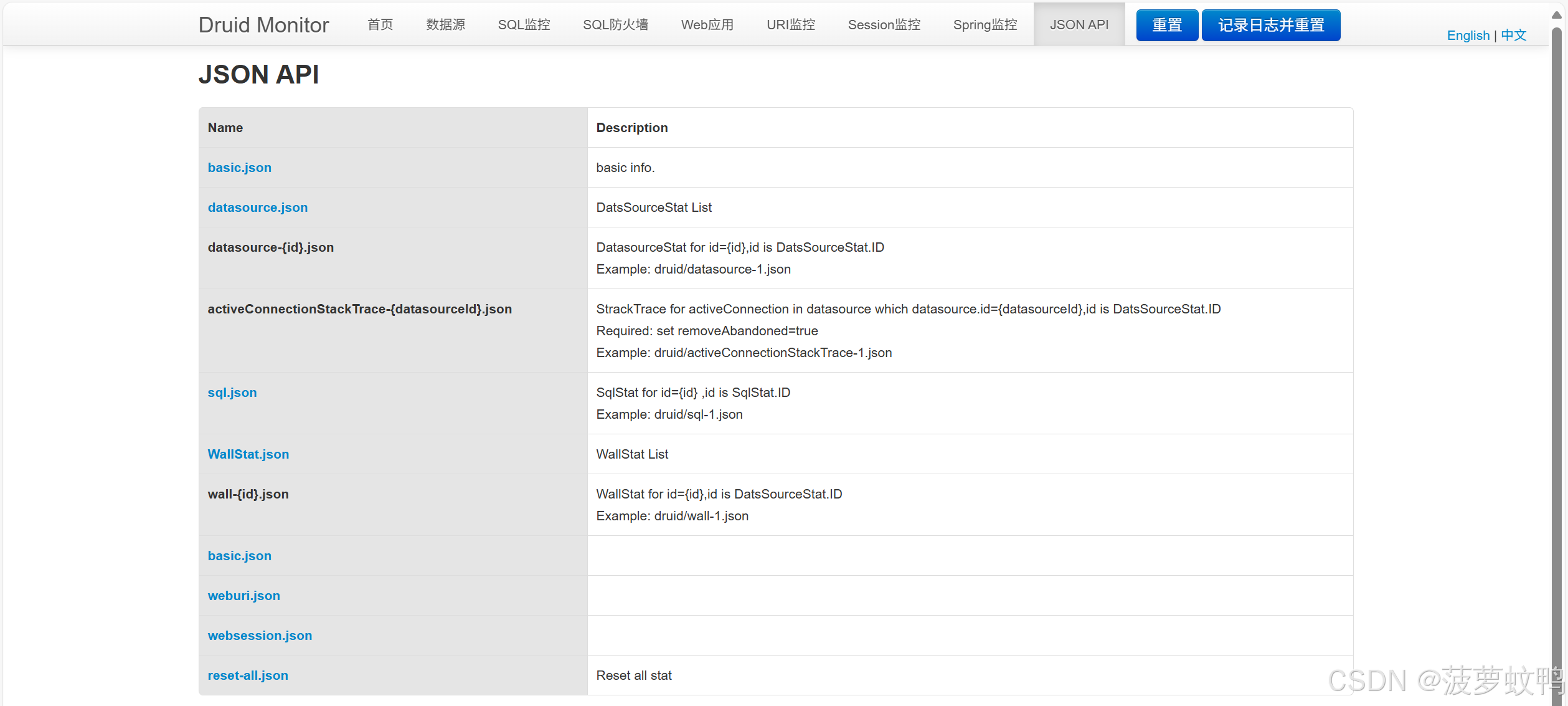
4.8、JSON API
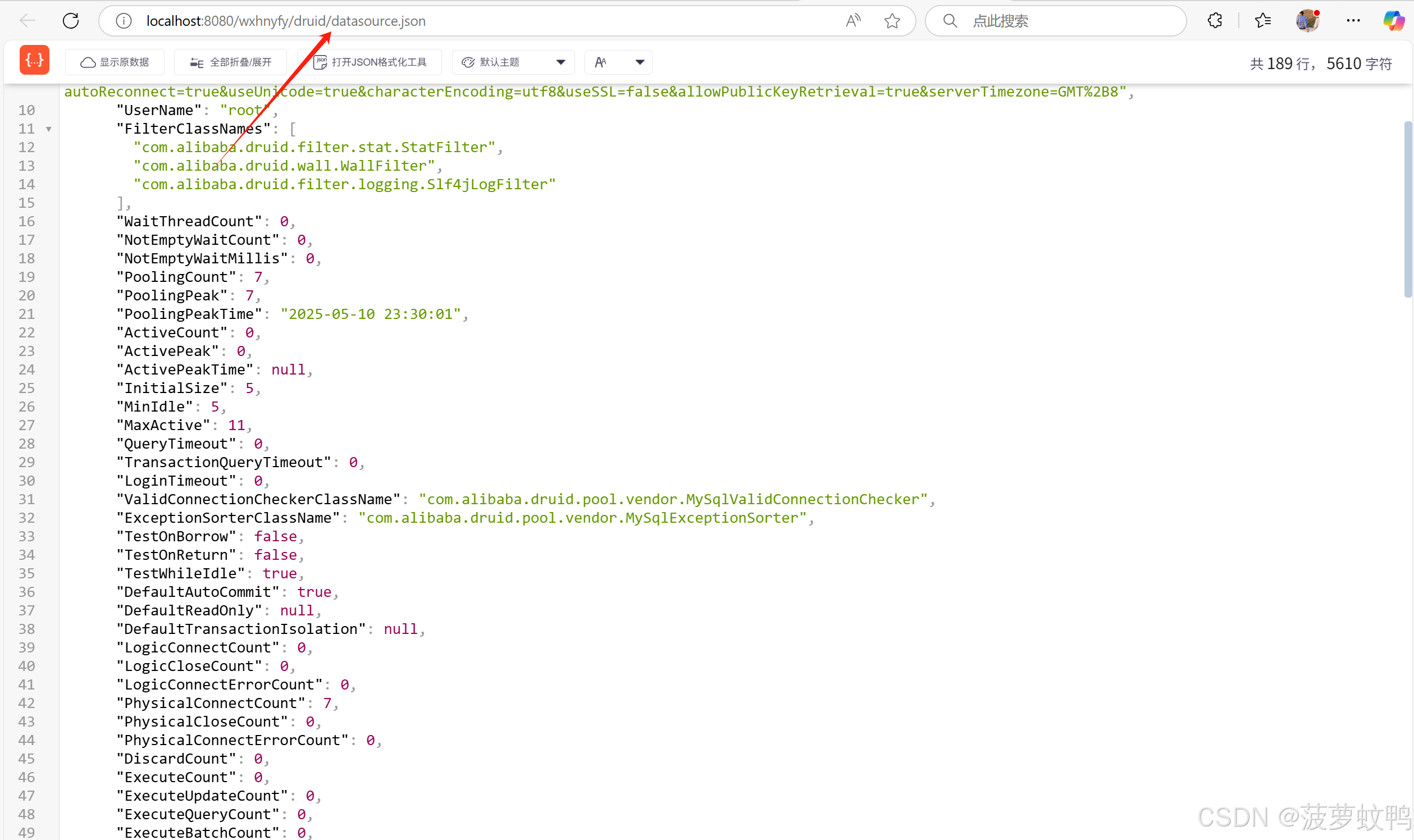
把各个页面的信息转为 JSON 数据
5、动态切换数据源
这里给出一个参考解决方案
5.1、数据源枚举
public enum DataSourceEnum {MASTER("master"),SLAVE("slave");private String value;DataSourceEnum(String value) {this.value = value;}public String getValue() {return value;}
}
5.2、Controller 层
在 Controller 的每个方法入参都加上数据源枚举
@ApiOperation(value = "执行自定义SQL")
@ApiImplicitParams({@ApiImplicitParam(name = "envCode", value = "数据源标识", required = true, paramType = "query", example = "MASTER", dataTypeClass = DataSourceEnum.class),@ApiImplicitParam(name = "query", value = "查询字符串", required = true, paramType = "query", example = "select * from chinapostoffice limit 100", dataTypeClass = String.class),
})
@GetMapping("/getChinaPostOffice ")
public Response<JSONArray> getChinaPostOffice(@RequestParam DataSourceEnum envCode,@RequestParam String query
) {logger.info(">>> query: {}", query);List<Map<String, Object>> list = customMapper.selectList(query);logger.info(">>> 总共 {} 条数据", list.size());logger.info(">>> 数据: {}", JSONArray.from(list, JSONWriter.Feature.WriteMapNullValue).toJSONString(JSONWriter.Feature.WriteMapNullValue));return new Response<JSONArray>().success(JSONArray.from(list, JSONWriter.Feature.WriteMapNullValue));
}
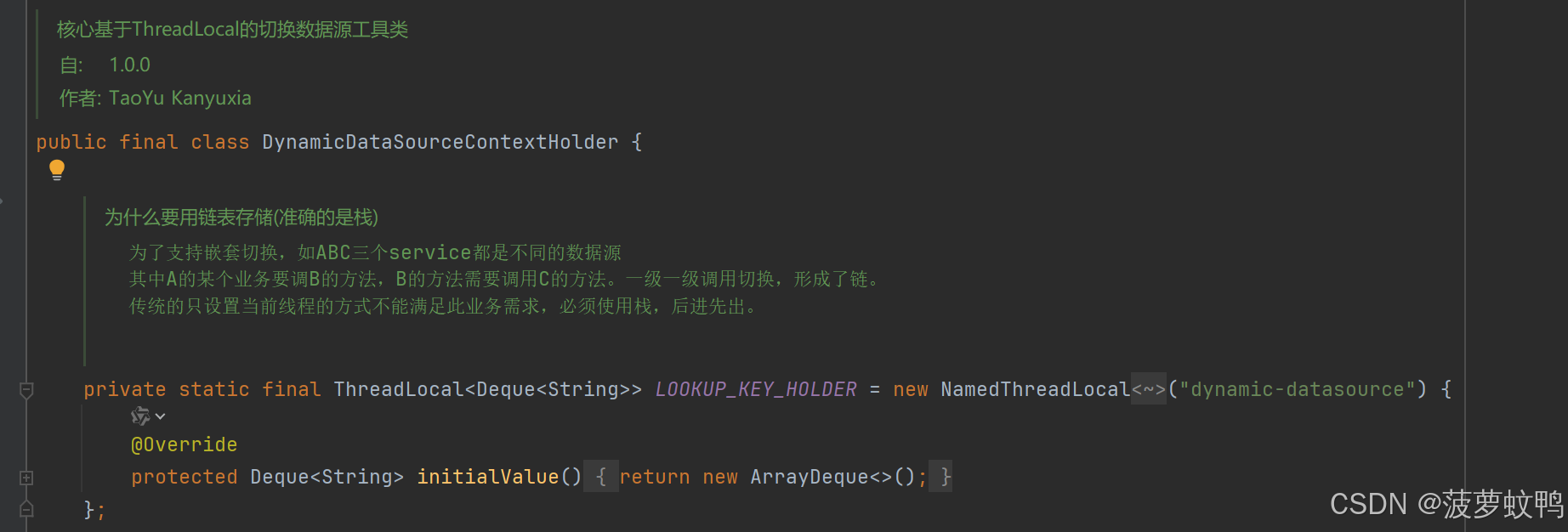
5.3、AOP 根据入参自动切换数据源
DynamicDataSourceContextHolder 实现原理,可参考源码,解析得很详细了
@Aspect
@Component
// 确保在事务切面之前执行
@Order(Ordered.HIGHEST_PRECEDENCE)
public class AutoSwitchDataSourceAop {private static final Logger logger = LoggerFactory.getLogger(AutoSwitchDataSourceAop.class);/*** 当前指定的默认数据源*/@Value("${spring.datasource.dynamic.primary}")private String dynamicPrimaryDataSource;/*** 定义匹配需要切换数据源的方法的切点* 匹配com.github.wxhnyfy.dynamicdatasource.controller包、com.github.wxhnyfy.dynamicdatasource.impl.service包下所有包含DataSourceEnum参数的方法* 支持DataSourceEnum参数在任意参数位置(不限于第一个参数)** @param joinPoint 切点* @return 目标执行方法* @throws Throwable 异常*/@Around("execution(* com.github.wxhnyfy.dynamicdatasource.controller.*.*(com.github.wxhnyfy.dynamicdatasource.enums.DataSourceEnum, ..)) " +"|| execution(* com.github.wxhnyfy.dynamicdatasource.impl.service.*.*(com.github.wxhnyfy.dynamicdatasource.enums.DataSourceEnum, ..))")public Object around(ProceedingJoinPoint joinPoint) throws Throwable {MethodSignature signature = (MethodSignature) joinPoint.getSignature();String methodName = signature.getMethod().getName();logger.info("进入 SwitchDataSourceAspect 的方法名: {}", methodName);logger.debug("当前指定的默认数据源:{}", dynamicPrimaryDataSource);DataSourceEnum envCode = null;try {// 获取方法参数中的EnvCode值envCode = extractEnvCode(joinPoint);// 切换数据源if (envCode != null) {logger.info("数据库环境标识:{}", envCode);String previousDs = DynamicDataSourceContextHolder.peek();logger.info("方法 [{}] 切换数据源: {} -> {}", methodName, previousDs, envCode.getValue());DynamicDataSourceContextHolder.push(envCode.getValue());}// 执行目标方法return joinPoint.proceed();} finally {// 清理数据源(恢复到默认数据源)if (envCode != null) {DynamicDataSourceContextHolder.clear();}}}/*** 通过反射获取方法参数* 自动识别DataSourceEnum类型的参数* 支持任意位置的DataSourceEnum参数** @param joinPoint 切点* @return DataSourceEnum参数*/private DataSourceEnum extractEnvCode(ProceedingJoinPoint joinPoint) {MethodSignature signature = (MethodSignature) joinPoint.getSignature();Parameter[] parameters = signature.getMethod().getParameters();// 遍历参数查找EnvCode类型的参数for (int i = 0; i < parameters.length; i++) {if (parameters[i].getType().isAssignableFrom(DataSourceEnum.class)) {Object arg = joinPoint.getArgs()[i];if (arg instanceof DataSourceEnum) {return (DataSourceEnum) arg;}}}return null;}
}
6、日志输出效果
Mybatis-Plus 我们使用 org.apache.ibatis.logging.slf4j.Slf4jImpl 日志实现,配置对应的日志级别
mybatis-plus:mapper-locations: classpath:mapper/*.xmlconfiguration:log-impl: org.apache.ibatis.logging.slf4j.Slf4jImpl
logging:level:root: info# 注意,logback不支持**匹配com.github.wxhnyfy.**.mapper: debugdruid.sql.Statement: debug
日志输出效果如下图







