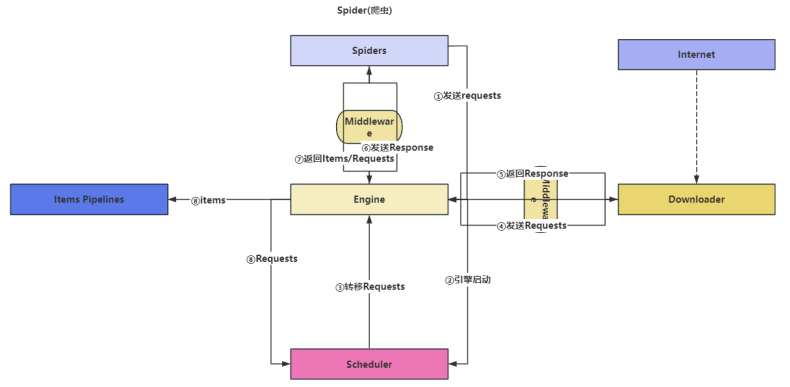
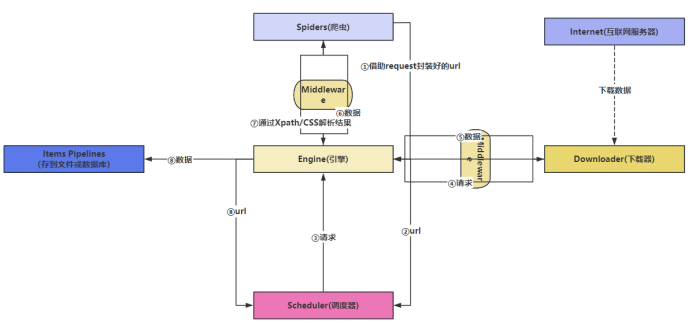
Scrapy数据流图:
Engine:为引擎,其为框架的核心,其他所有组件在其控制下协同工作
Scheduler:为调度器,负责对Spider提交的下载请求进行调度
Downloader:为下载器,负责下载页面(发送HTTP请求/接收HTTP响应)
Spider:为爬虫,负责提取页面中的数据,并产生对新页面的下载请求
Middleware:为中间件,负责对Request对象和Response对象进行处理
Item Pipleline:为数据管道,负责对爬取的数据进行处理
使用Selector提取数据
BeautifulSoup是非常流行的HTTP解析库,API简洁易用,但解析速度较慢。
Lxml底层是由C语言编写的,使得其解析的速度更快,API相对复杂。
而Scrapy综合以上两个的优点实现了Selector类,
在Selector中有以下方法可以对选中的内容进行提取extract()/re()/extract_first()/re_first(),该extract_first()/re_first()方法返回的是第一个SelectorList对象调用extract方法的结果,其中包含该Xpath中的各文本,可以通过索引进行对应的提取。
由于自己对Xpath较为陌生,所以使用下面对XPath的知识进行补充学习:
以下是学习XPath文档:https://www.w3.org/TR/xpath/
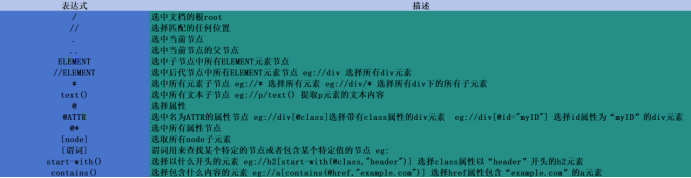
CSS语法比XPath简单,但是其功能不如Xpath强大,在使用CSS时,其Python内部会将CSS选择器表达式转化为Xpath表达式,然后调用XPATH方法对其进行处理。
以下是学习CSS文档:https://www.w3.org/TR/css3-selectors