
简介:本书从深度神经网络和 AI 芯片研究现状出发,系统地论述了目前深度学习主流开发平台和深度神经网络基于 FPGA 平台实现加速的开发原理和应用实例。全书主要包括5部分:第1~2章介绍了深度神经网络的发展,并总结了深度学习主流开发平台和 AI 芯片的研究现状;第3~6章在对深度神经网络基础层算子、 FPGA 进行了介绍后,总结了 FPGA 神经网络开发基础及 RTL 级开发;第7章分析了基于 FPGA 实现神经网络加速的实例;第8章介绍了基于 OpenCL 的 FPGA 神经网络计算加速开发;第9章分析了前沿神经网络压缩与加速技术。本书可以为人工智能、计算机科学、信息科学、神经网络加速计算研究者或者从事深度学习、图像处理的相关研究人员提供参考,也可作为相关专业本科生及研究生的教学参考书。
0.为什么选择这本书
笔者评级:⭐
笔者评价:本书整体来讲“干货”不多,原因有二,一是大面积篇幅讲解了诸如神经网络发展历程,神经网络的常用框架,FPGA发展历程,FPGA选型等内容,而且只是表面的很浅的讲解。由于研究使用FPGA进行神经网络加速的同学一定不是完全零基础的入门选手,所以这部分的叙述显得乏善可陈。这并不是一本定位科普的图书,讲解这些内容与其“专业性”不符。第二,本书没有给出完整的代码参考工程,尽管在具体设计部分给出了一部分代码,但这对于学习的同学来说并不是非常友好。在后面关键的FPGA实现部分,没有详细描述每个模块的实现原理,只是铺了一些内容,不利于读者阅读和理解。去其糟粕,取其精华,选择这本书的原因主要也是被书名吸引,在这里仅以这本书中的部分内容作为入门的学习。
书籍内容来源于网络,如有侵权请联系删除!如果您对书籍感兴趣,敬请支持正版。
1.神经网络基本算子
1.1 卷积算子
我们定义卷积中的参数如下表:
| 参数名称 | 参数符号 |
|---|---|
| 输入特征图尺寸 | I |
| 卷积核尺寸(Kernel) | K |
| 滑动步长(Stride) | S |
| 边缘填充像素数(Padding) | P |
| 输出特征图尺寸 | O |
计算输出特征图尺寸是我们经常需要用到的公式,表示如下:
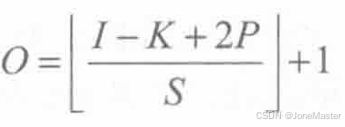
进行卷积之前先进行Padding,Padding=1代表在外围补一圈0。

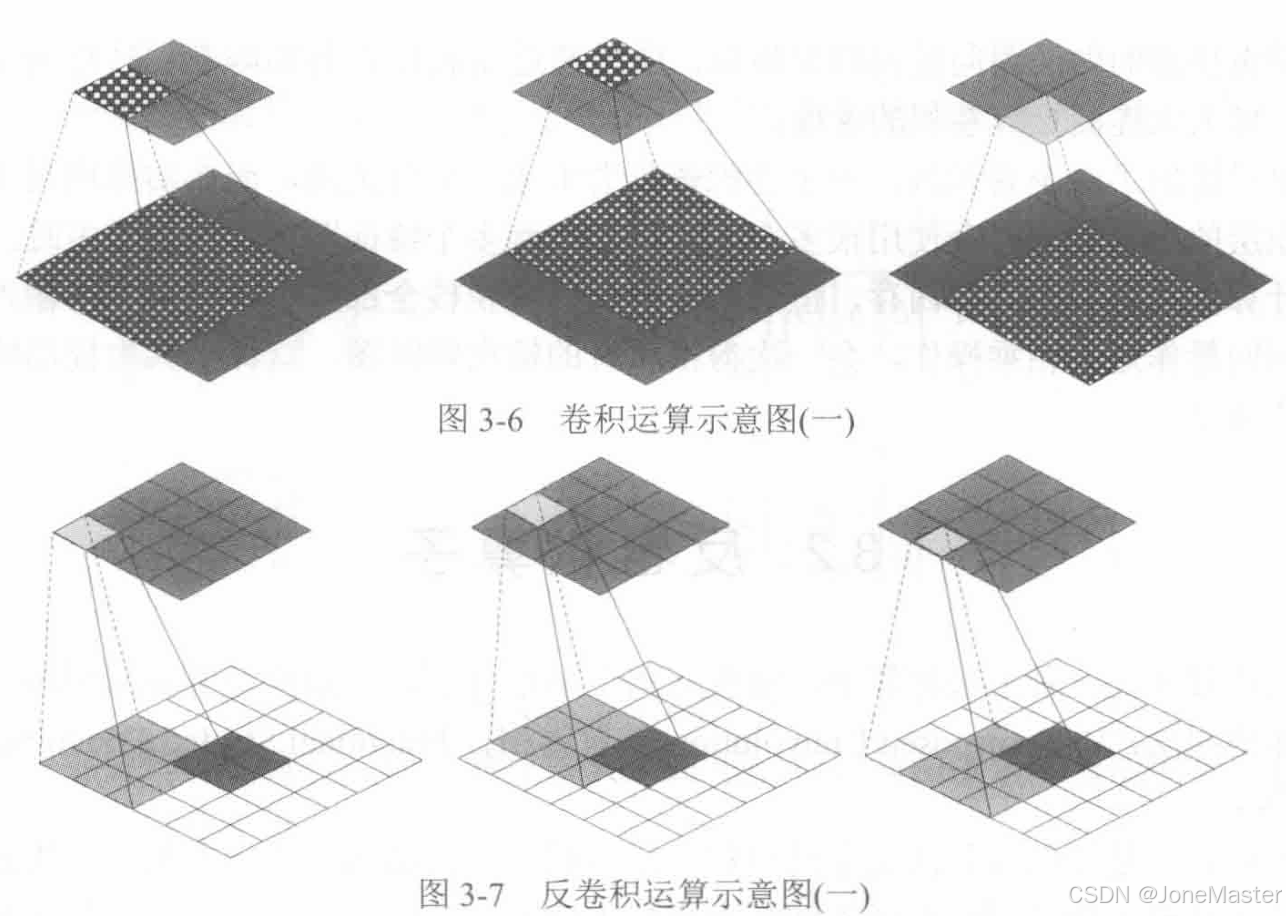
使用img2col的方式计算卷积,它的含义是将特征图展开为一个矩阵,比如现在使用3x3的卷积核,那么卷积核每一次在输入特征图上滑动将会从图中选出3x3的数据进行运算,我们将特征图上每一个可能被选中的3x3小块全部展开为一个列向量,组成一个矩阵,这个矩阵有K×K行,有O列。
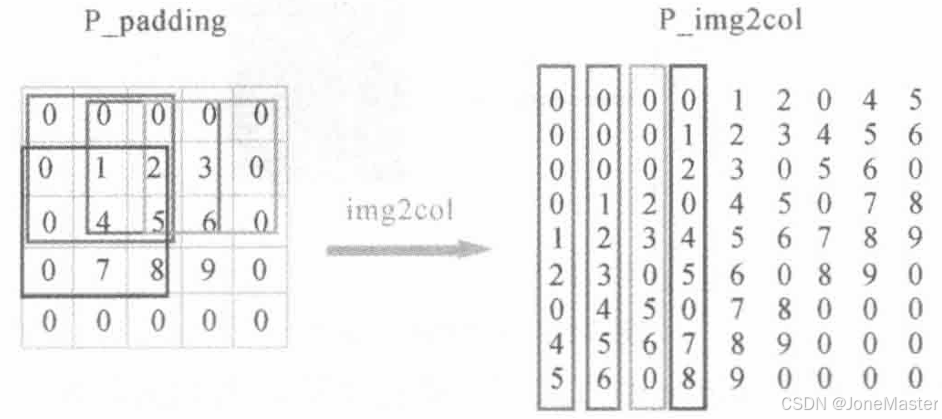
可见每一个列向量都是原图的一个块。之后将卷积核拉伸为行向量,这样卷积的过程变成了矩阵乘法。
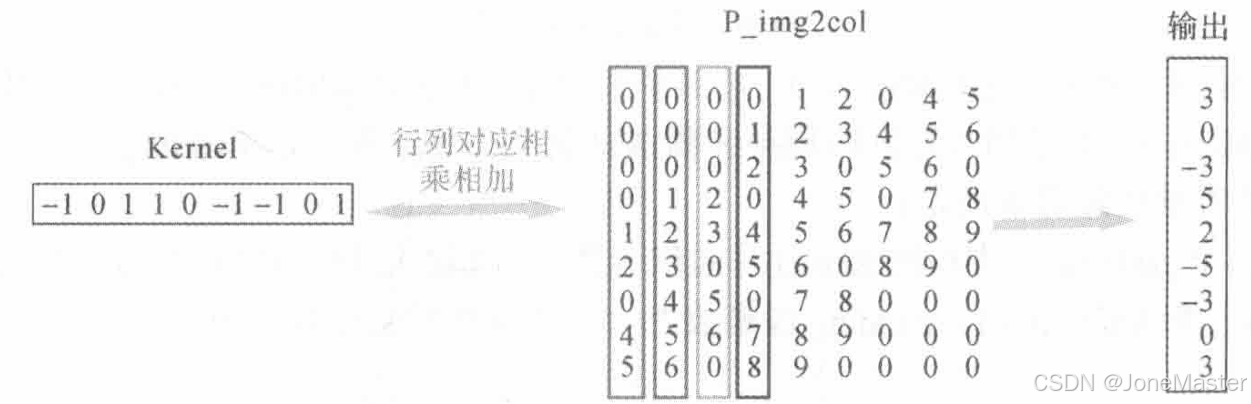
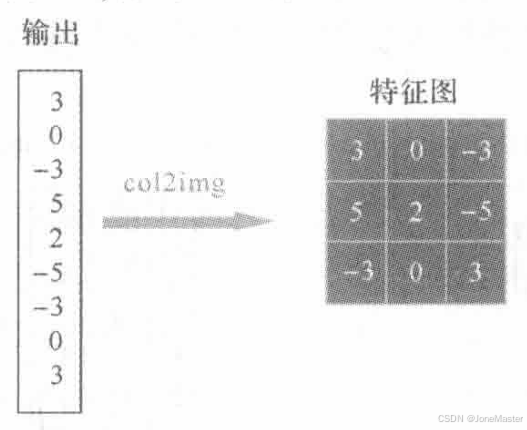
这个输出的向量恰好就是输出特征图,将其进行col2img操作就能还原输出矩阵:
1.2 反卷积算子(上采样算子)
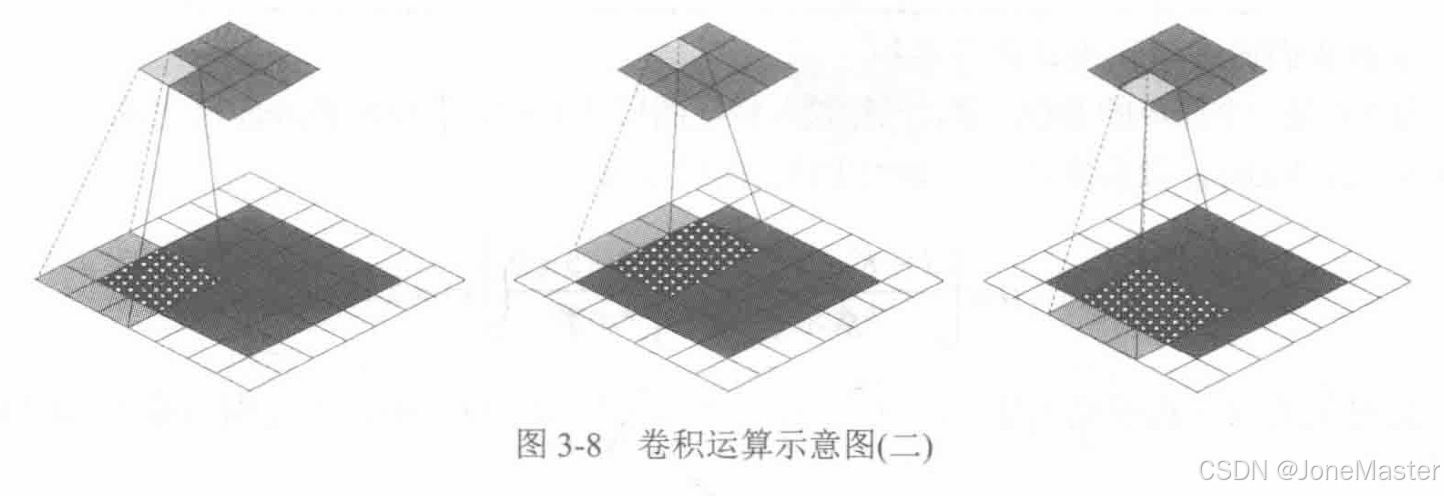
也被称为转置卷积、小步长卷积。反卷积不是正向卷积的完全逆过程,它是一种特殊的正向卷积,它先按照一定的比例通过对输入特征图进行像素间填充来扩大输入特征图尺寸,接着旋转卷积核,再进行正向卷积,它是从低分辨率映射到高分辨率的过程,用于扩大图像尺寸。定义反卷积操作参数如下表:
| 参数名称 | 参数符号 |
|---|---|
| 输入特征图尺寸 | I' |
| 卷积核尺寸(Kernel) | K' |
| 滑动步长(Stride) | S' |
| 边缘填充像素数(Padding) | P' |
| 输出特征图尺寸 | O' |
反卷积我们可以理解为,将正向卷积得到的输出图进行Padding,再进行正向卷积,得到一个与之前正向卷积输入大小相同的输出。反卷积的输出特征图比输入大。
反卷积填充0(Padding)的公式是
当正向卷积的步长S=S'=1时,Padding的0全部填充在外圈,当步长大于1时,在输入特征图像素点之间插入S-1个0,外围填充P‘-(S - 1)个0。
所以,反卷积输出特征图大小公式为:
1.3 池化算子
常用的池化算子有2种,一种是平均池化,一种是最大池化。顾名思义,平均池化的输出是每个patch求均值得出的,而最大池化输出是每个patch中的最大值。
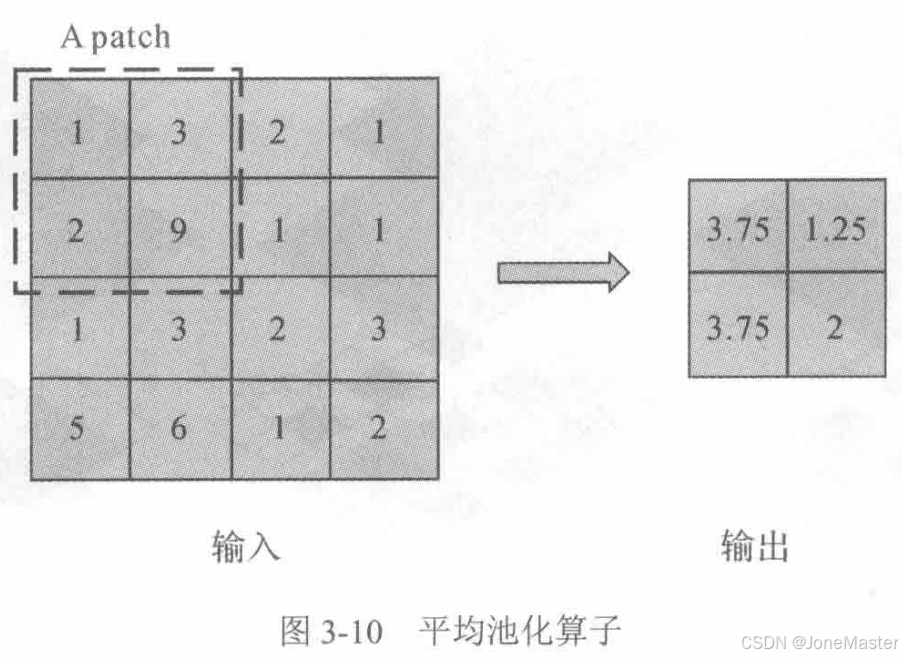
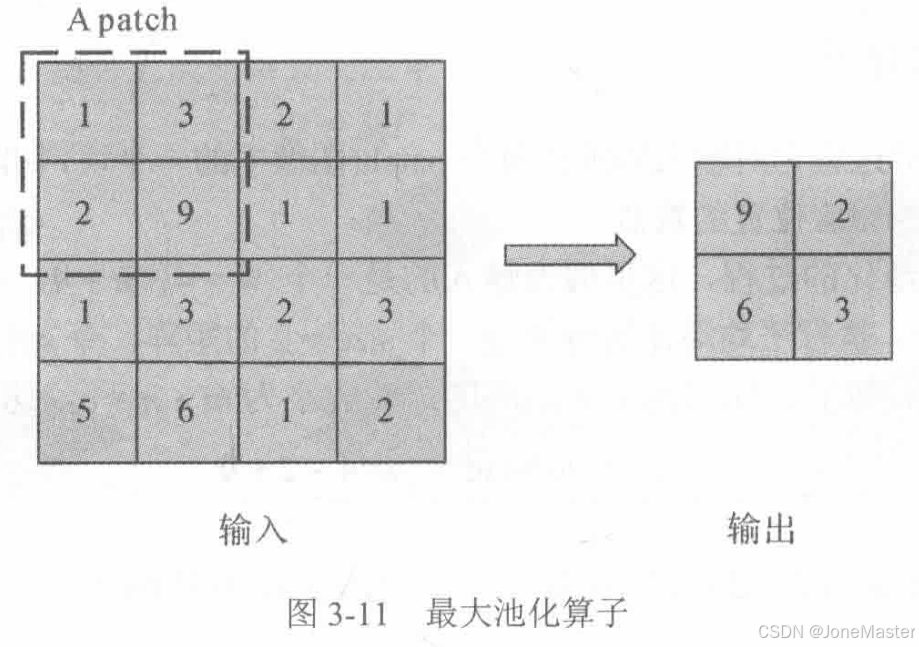
其输出特征的大小与卷积计算公式相似。
1.4 激活算子
激活算子的作用是在卷积层或全连接层后,为神经网络引入非线性运算,使其具有更好的拟合能力。
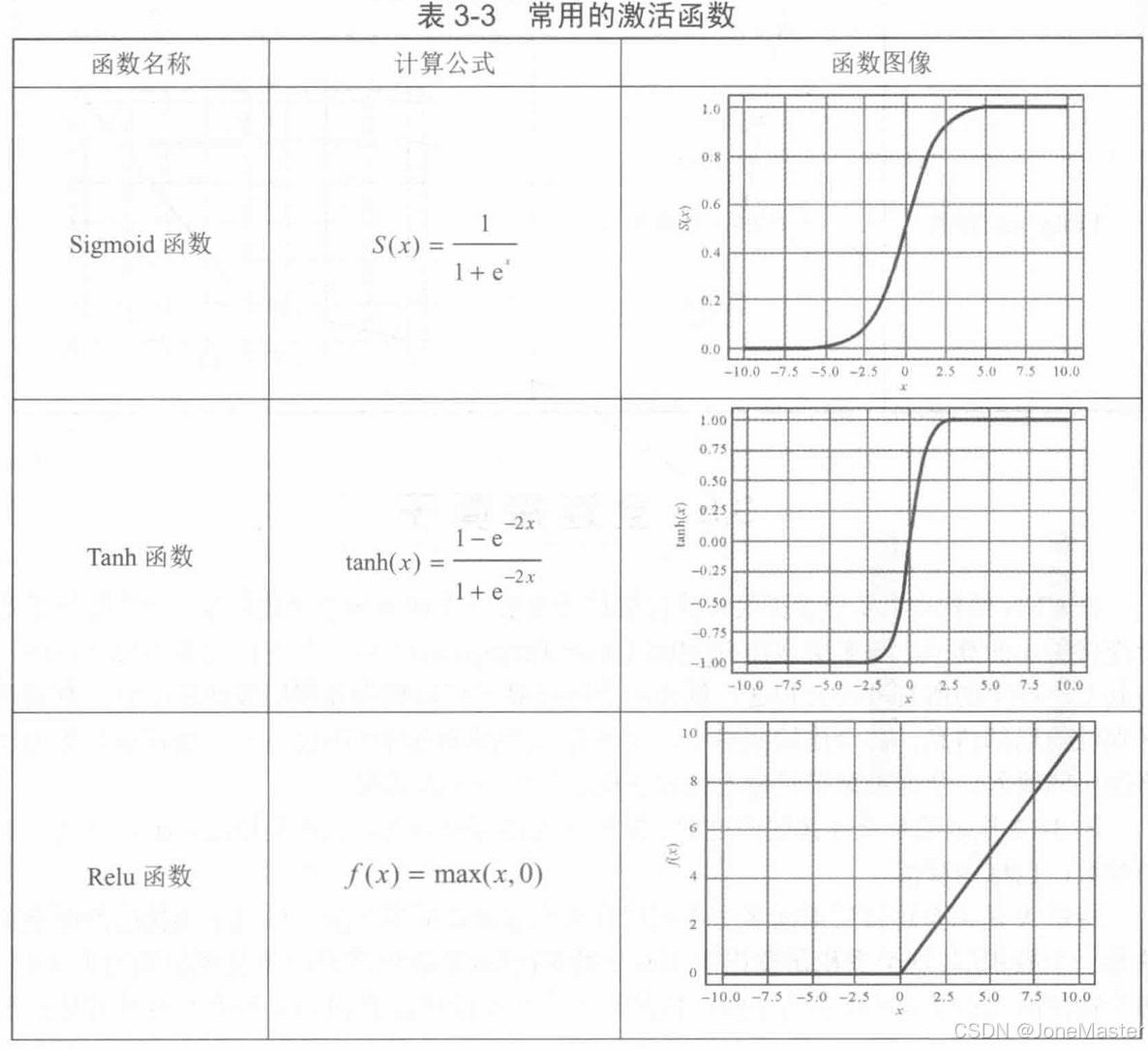
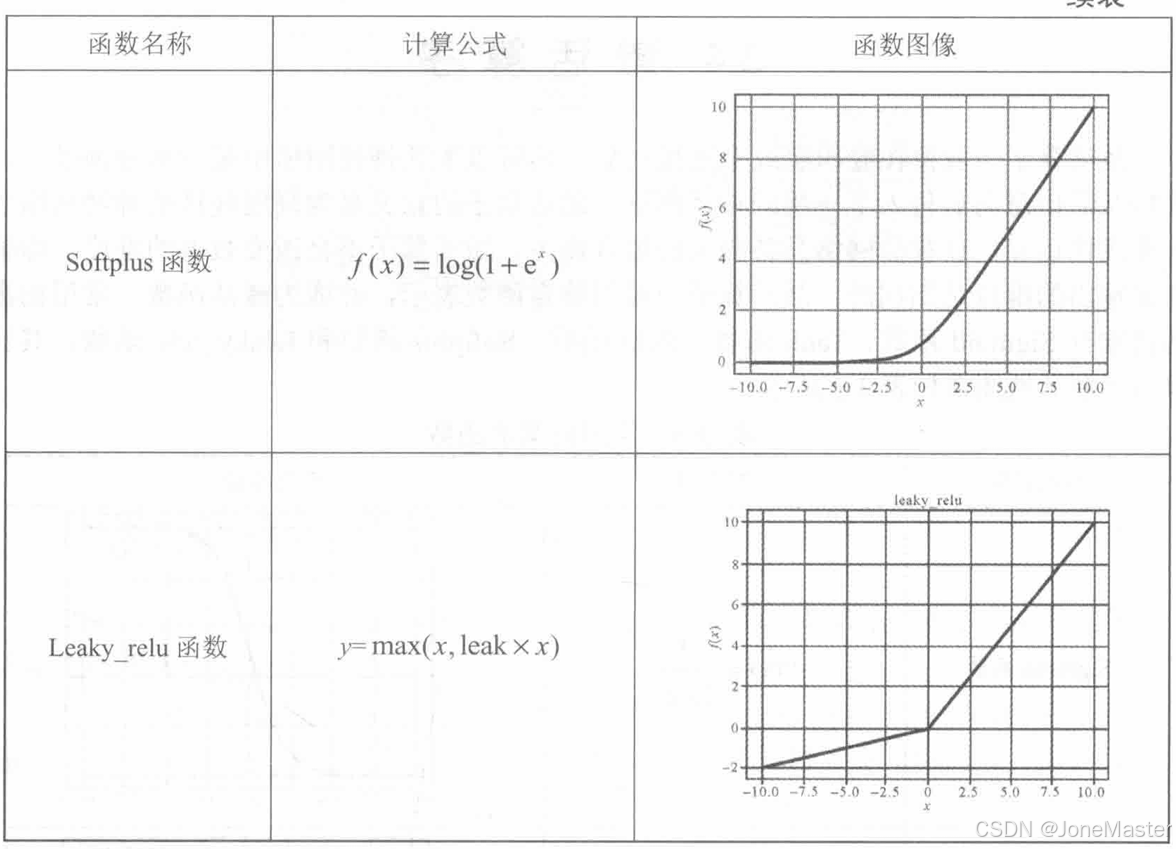
1.5 全连接算子
全连接层的每个神经元与上一层所有的神经元相连,全连接网络中将所有的二值图像的特征图拼接为一位特征名作为全连接层的输入,全连接算子对输入进行加权求和,送入输出层。

若全连接层前面的卷积层输出了100个通道的特征图,每个特征图大小是4×4,首先将其拉平为一个N=1600的一维向量,全连接层的参数是经过训练得到的最优参数,它是T行N列的矩阵,其中T是输出类别数,对应于分类问题最后要输出几分类。
1.6 Softmax算子
Softmax层主要作用于神经网络的最后一层,旨在输出输入样本属于各个类别的概率。
Softmax层的计算公式是:
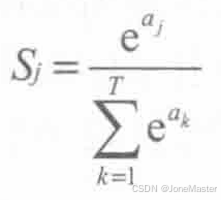
的主要作用是将输出归一化到(0,1)的区间,便于进行概率判断。
1.7 批标准化算子(BN算子)
批标准化层是一个深度神经网络训练的技巧,可以加快模型的收敛速度,缓解深层网络中梯度弥散的问题。由于激活函数的特性,对于较大的输入值并不敏感,可以对训练样本进行矫正,让输入值的分布永远处于激活函数的敏感部分。BN层的提出就是用来标准化某些层或所有层的输入,从而固定每层输入信号的均值和方差。它一般用于激活函数之前,对y=Wx+b进行规范化,使输出结果均值为0,方差为1。
它的具体运算分为以下四步:

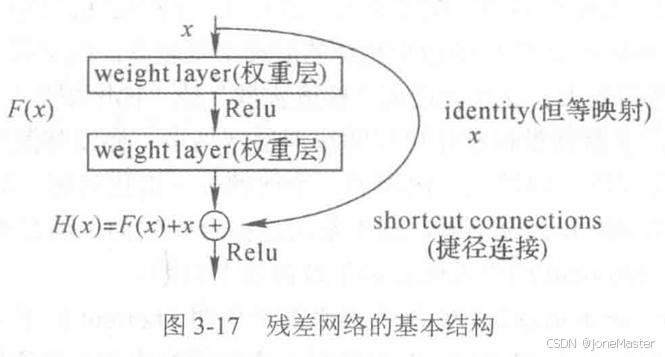
1.8 Shortcut算子
这个算子的提出主要是为了减少冗余层和解决退化问题。

由于C支路的存在,不管梯度怎么下降,梯度都不会消失;而如果有一层是冗余的,只需要学习到C支路为x,T支路为0即可,网络会自行决定哪些是冗余层。
ResNet的残差网络结构也是一种利用Shortcut算子的实例。
2.基于FPGA实现YOLO v2模型计算加速实例分析
在FPGA上实现神经网络加速可以分为以下三种,我们把优缺点列成表格的形式:
| 类型 | 特点 | 优点 | 缺点 |
|---|---|---|---|
| 专用神经网络加速 | 将整体的神经网络全部固化到FPGA内部进行加速 | 加速性能高,稳定性好 | 模型结构固定,更改模型后需要重新设计FPGA |
| 可配置神经网络加速 | 将FPGA内部加速计算单元做成可配置模式,可以配置成常见的神经网络层级 | 加速灵活性高,性能较高 | 设计难度较大 |
| 神经网络算子加速 | FPGA内制作神经网络算子加速,神经网络各层级间的调度由软件完成 | 灵活性最强 | 软件调度使加速效果较差 |
本书这部分的分析比较难于看懂,笔者在这里也没有记录笔记。关于这里的内容,我们后续会通过其他书籍和课程详细学习,这里先挖个坑。






