我训练一个mobilenet, 结构如下:
def max_abs_normalize_layer():return Lambda(lambda x: x / (tf.reduce_max(tf.abs(x), axis=1, keepdims=True) + 1e-8))def depthwise_pointwise_1d(x, kernel_size=3, stride=1):x = tf.expand_dims(x, axis=2)# DepthwiseConv2D 相当于对每个通道单独卷积x = DepthwiseConv2D((kernel_size, 1), strides=(stride, 1), padding='same', activation='relu')(x)x = tf.squeeze(x, axis=2)return xdef mobilenetv2_block(x, filters1, stride):# Expandx = Conv1D(filters1, kernel_size=3, padding='same', activation='relu', kernel_initializer='he_normal')(x)# SeparableConv1D = DepthwiseConv1D + PointwiseConv1D# x = depthwise_pointwise_1d(x, kernel_size=3, stride=stride)x = SeparableConv1D(64, kernel_size=3, strides=stride, padding='same', activation='relu')(x)# x = Conv1D(filters2, kernel_size=1, padding='same', activation='relu')(x)x = max_abs_normalize_layer()(x)return xdef build_mobilenet1d(input_shape):inputs = Input(shape=input_shape)# x = Conv1D(32, kernel_size=3, strides=1, padding='same', activation='relu')(inputs)x = inputs# MobileNetV2-like blocksx = mobilenetv2_block(x, filters1=64, stride=1)x = mobilenetv2_block(x, filters1=64, stride=1)# x = mobilenetv2_block(x, filters1=6, filters2=64, stride=1)# x = mobilenetv2_block(x, filters1=6, filters2=128, stride=1)# x = GlobalAveragePooling1D()(x)# x = Dropout(0.1)(x)x = Flatten()(x)x = Dense(128, activation='relu', kernel_initializer='he_normal')(x)x = Dense(64, activation='relu', kernel_initializer='he_normal')(x)x = Dense(1, activation='sigmoid')(x)# x = Dense(1)(x)model = Model(inputs=inputs, outputs=x)return model训练时accuracy一直在0.5附近抖动,上不去。一开始我还以为模型结构有大问题,没法训练,直到某次意外发现准确率上去了,再次训练还是在0.5附近抖动,我才意识到这个是训练不稳定。应该是梯度消失,去掉一层mobilenet模块每次都能正常训练。
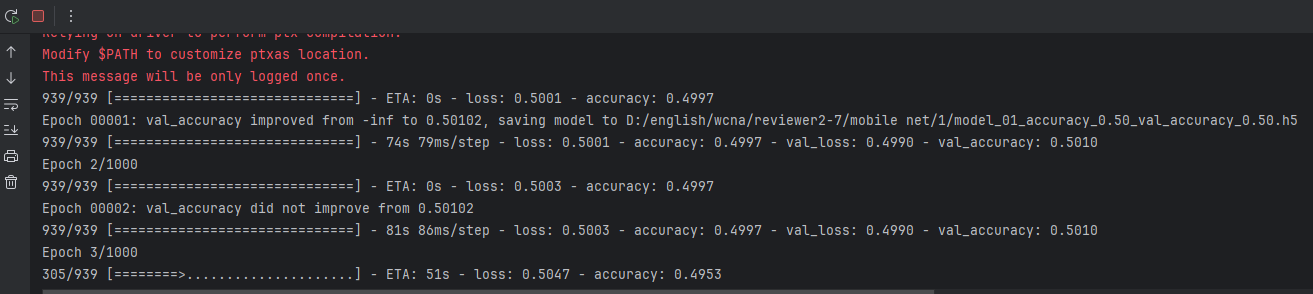
5次有4次异常:(后面无论多少轮都上不去)
我感觉是梯度消失后,只留下部分梯度还存在的参数既然顽强训练,但是无论怎么都不可能很好拟合了。
1次正常:

一开始我以为是训练过程数据数值分布远超(0,1),需要归一化:
def max_abs_normalize_layer():return Lambda(lambda x: x / (tf.reduce_max(tf.abs(x), axis=1, keepdims=True) + 1e-8))x = max_abs_normalize_layer()(x)(为啥不直接用BatchNormalization,而是自己定义一个...? 因为,我的数据二值化比较严重,同时二值的概率不均匀,用一般的BatchNormalization效果不好)
归一化后,训练还是不稳定。
问chatgpt,建议用 binary_crossentropy作为损失函数,不要用mean_squared_error:

按建议重新训练,发现效果好了很多,基本上每次都能正常训练。
没想到,前面模型结构调了半天,最后问题出在一个“binary_crossentropy”参数上。
当然,模型结构肯定是有影响的,好的模型结构无论是binary_crossentropy还是mean_squared_error都能有很好的训练效果。




