《RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning》
25年2月来自华中科大和地平线的论文
现有的端到端自动驾驶(AD)算法通常遵循模仿学习(IL)范式,这面临着因果混淆和开环差距等挑战。在这项工作中,我们建立了一个基于3DGS的闭环强化学习(RL)训练范式。通过利用3DGS技术,我们构建了真实物理世界的逼真数字复制品,使AD策略能够广泛探索状态空间,并通过大规模的试错来学习处理超出分布的场景。为了提高安全性,我们设计了专门的奖励,指导政策有效应对安全关键事件,并了解现实世界的因果关系。为了更好地与人类驾驶行为保持一致,IL作为正则化术语被纳入RL训练中。我们引入了一个闭环评估基准,由各种以前从未见过的3DGS环境组成。与基于IL的方法相比,RAD在大多数闭环度量中实现了更强的性能,特别是碰撞率降低了3倍。
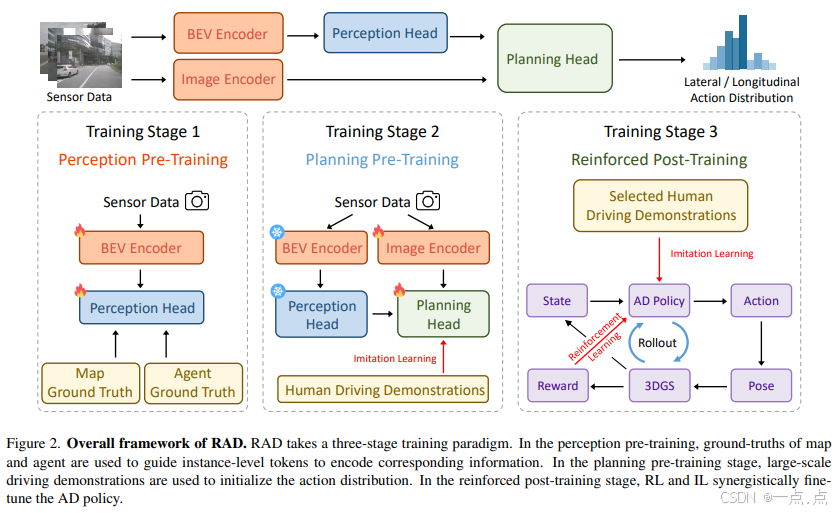
核心问题与动机
-
现有方法的局限
-
模仿学习(IL)主导:当前端到端自动驾驶(AD)主要依赖IL,但存在两大缺陷:
-
因果混淆(Causal Confusion):IL仅学习状态-动作的相关性,难以捕捉真实因果逻辑(如误将历史轨迹作为决策依据)。
-
开环-闭环鸿沟(Open-Loop Gap):开环训练无法模拟闭环部署中的误差累积,导致分布外(OOD)场景鲁棒性差。
-
-
仿真瓶颈:传统仿真器(如CARLA)渲染效率低且真实性不足,难以支持大规模RL训练。
-
-
RAD的解决方案
提出首个基于3D高斯泼溅(3DGS) 的闭环强化学习框架,通过构建逼真的数字孪生环境,实现安全、高效的端到端AD策略训练。
关键技术创新
1. 3DGS驱动的闭环RL训练范式
-
环境构建:从真实驾驶片段重建4305个高风险的3DGS场景(3968训练/337测试),支持实时交互与逼真渲染。
-
优势:
-
允许策略通过大规模试错探索状态空间,学习处理OOD场景。
-
规避实车训练的安全风险与成本问题。
-
2. RL与IL协同优化
-
混合训练机制:
-
RL目标:通过奖励函数增强对安全关键事件(碰撞、偏离)的敏感性。
-
IL正则化:引入IL损失作为正则项,确保驾驶行为与人类对齐,避免RL探索导致的动作不连续。
-
-
三阶段训练流程:
阶段 目标 更新模块 感知预训练 学习地图/交通参与者表征 BEV编码器、地图/Agent Head 规划预训练 IL初始化动作分布 图像编码器、规划Head 强化后训练 RL+IL协同微调策略 图像编码器、规划Head(其余冻结)
3. 高效动作空间设计
-
解耦离散动作:
-
横向动作 axax(转向):61档位(-0.75m至0.75m)。
-
纵向动作 ayay(速度):61档位(0m至15m)。
-
-
简化动力学模型:假设0.5秒内匀速运动,降低动作维度,加速RL收敛。
4. 奖励函数设计
-
四元奖励机制:
\mathcal{R} = \{r_{\text{dc}}, r_{\text{sc}}, r_{\text{pd}}, r_{\text{hd}}\}-
动态碰撞(rdcrdc):与移动障碍物重叠。
-
静态碰撞(rscrsc):与静态障碍物(3DGS高斯模型)重叠。
-
位置偏离(rpdrpd):偏离专家轨迹>2.0m。
-
航向偏离(rhdrhd):航向角偏差>40°。
-
-
提前终止:任一事件触发回合终止,避免噪声干扰。
5. 稀疏奖励优化:辅助目标函数
-
核心思路:将稀疏奖励分解为密集的纵向/横向辅助损失,约束全动作分布。
-
动态碰撞辅助:根据碰撞方向调整加速度(前撞减速,后撞加速)。
-
静态碰撞/轨迹偏离辅助:根据障碍物位置或轨迹偏差调整转向。
-
最终损失:
\mathcal{L}(\theta) = \mathcal{L}^{\text{PPO}}(\theta) + \lambda_1 \mathcal{L}_{\text{dc}} + \lambda_2 \mathcal{L}_{\text{sc}} + \lambda_3 \mathcal{L}_{\text{pd}} + \lambda_4 \mathcal{L}_{\text{hd}}
实验验证
1. 评估基准
-
数据集:2000小时真实驾驶数据,自动标注地图/交通参与者。
-
指标:
-
安全性:碰撞率(CR)、动态碰撞率(DCR)、静态碰撞率(SCR)。
-
轨迹一致性:偏离率(DR)、平均偏离距离(ADD)。
-
平滑性:纵向/横向加加速度(Jerk)。
-
2. 关键结果
-
RL-IL比例消融(表1):
-
纯IL:CR=0.229(安全性差),ADD=0.238(轨迹一致性好)。
-
纯RL:CR=0.143(安全性提升),ADD=0.345(轨迹一致性下降)。
-
最优混合(4:1):CR=0.089(↓61%),ADD=0.257(平衡安全性与一致性)。
-
-
奖励函数消融(表2):
-
移除动态碰撞奖励 → CR升至0.238,验证其对安全性的关键作用。
-
-
SOTA对比(表4):
方法 CR DCR ADD VAD [17] 0.335 0.273 0.304 GenAD [49] 0.341 0.299 0.265 RAD 0.089 0.080 0.257 -
结论:RAD在CR上超越IL方法3倍以上,且保持低ADD。
-
3. 定性分析
-
场景对比(图5 & 附录图A1):
-
IL策略:在行人避让、无保护左转等动态场景中频繁碰撞。
-
RAD:成功处理高风险场景(如拥堵绕行、U型转弯),轨迹更平滑安全。
-
贡献与局限性
核心贡献
-
首创3DGS-RL框架:实现逼真、高效的闭环AD策略训练。
-
RL-IL协同机制:RL解决因果性与开环鸿沟,IL保证人类行为对齐。
-
工程优化:解耦动作空间、密集奖励设计、辅助目标函数加速收敛。
局限性
-
非反应式环境:其他交通参与者按日志回放,未与ego车辆实时交互。
-
3DGS渲染限制:对非刚性物体(行人)、遮挡与低光场景还原不足。
-
计算成本:训练数千独立3DGS场景的资源消耗未量化。
未来方向
-
引入动态交通参与者交互机制。
-
提升3DGS在复杂场景的渲染质量。
-
扩展RL训练规模至更广泛场景。
-
探索轻量化3DGS部署方案。
总结:RAD通过3DGS+RL的闭环训练范式,显著提升AD策略的安全性(碰撞率↓3×)与泛化能力,为端到端自动驾驶提供了可扩展的新路径。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!



格式的选项,但你可以使用一些工具或手动转换来实现)


