1. 进程调度机制的架构
操作系统通过中断机制,来周期性地触发调度算法进行进程的切换:
- rq(per-CPU runqueue):可运行队列,每个CPU一个
- cfs_rq:cfs(完全公平调度系统)调度的运行队列信息
- sched_entity:调度实体,包含负载权重值,对应红黑树结点,虚拟运行时vruntime等
//数据结构关键部分struct load_weight load;struct rb_node run_node;u64 deadline;u64 min_vruntime;......struct cfs_rq *cfs_rq;/* rq "owned" by this entity/group: */struct cfs_rq *my_q;/* cached value of my_q->h_nr_running */unsigned long runnable_weight;- sched_class:调度算法抽象成的调度类,包含一组通用的调度操作接口,将接口和实现分离
struct sched_class {u8 state;u8 idx;struct ch_sched_params info;enum sched_bind_type bind_type;struct list_head entry_list;atomic_t refcnt; };
1.1 关键数据结构
1.1.1 struct rq(可运行队列)
以下是 Linux 内核 struct rq (运行队列) 数据结构的重要字段分类总结。运行队列是内核调度子系统最核心的数据结构之一,每个 CPU 都拥有自己的运行队列。
基本字段
| 字段 | 类型 | 描述 |
|---|---|---|
cpu | int | 当前运行队列所属的 CPU ID |
__lock | raw_spinlock_t | 运行队列的自旋锁,保护数据结构完整性 |
nr_running | unsigned int | 当前队列中可运行任务的数量 |
任务指针
| 字段 | 类型 | 描述 |
|---|---|---|
curr | struct task_struct __rcu * | 当前正在该CPU上运行的任务 |
idle | struct task_struct * | 空闲任务指针 (swapper 任务) |
stop | struct task_struct * | 停止任务指针 (用于 CPU hotplug) |
donor | struct task_struct __rcu * | Deadline 调度中带宽捐赠的任务指针 |
dl_server | struct sched_dl_entity * | Deadline 服务器调度实体 |
调度类队列
| 字段 | 类型 | 描述 |
|---|---|---|
cfs | struct cfs_rq | 完全公平调度器 (CFS) 的运行队列 |
rt | struct rt_rq | 实时调度器 (RT) 的运行队列 |
dl | struct dl_rq | Deadline 调度器的运行队列 |
scx | struct scx_rq | 扩展调度器 (SCHED_EXT) 的队列 (可选) |
fair_server | struct sched_dl_entity | 公平调度的服务器实体 |
时间管理
| 字段 | 类型 | 描述 |
|---|---|---|
clock | u64 | 单调递增的时钟,用于调度决策 |
clock_task | u64 | 任务运行时间专用时钟 |
clock_pelt | u64 | PELT (Per-Entity Load Tracking) 时钟 |
last_blocked_load_update_tick | unsigned long | 阻塞负载最后更新时间 |
idle_stamp | u64 | CPU 进入空闲状态的时间戳 |
avg_idle | u64 | CPU 平均空闲时间 |
负载跟踪
| 字段 | 类型 | 描述 |
|---|---|---|
cpu_capacity | unsigned long | CPU 的计算能力 |
misfit_task_load | unsigned long | 不适合当前CPU的任务负载 |
avg_rt | struct sched_avg | 实时任务的平均负载 |
avg_dl | struct sched_avg | Deadline 任务的平均负载 |
avg_irq | struct sched_avg | 中断处理时间的平均值 (可选) |
avg_hw | struct sched_avg | 硬件压力平均值 (可选) |
调度统计
| 字段 | 类型 | 描述 |
|---|---|---|
nr_switches | u64 | CPU 上发生的上下文切换次数 |
nr_uninterruptible | unsigned int | 不可中断睡眠状态任务数量 |
nr_iowait | atomic_t | 等待 I/O 的任务数量 |
yld_count | unsigned int | 通过 yield 放弃 CPU 的次数 |
sched_count | unsigned int | 调度发生的次数 |
ttwu_count | unsigned int | 任务被唤醒的次数 |
高级特性
核心调度 (Core Scheduling)
| 字段 | 类型 | 描述 |
|---|---|---|
core_enabled | unsigned int | 核心调度是否启用 |
core_tree | struct rb_root | 核心调度的红黑树根 |
core_cookie | unsigned long | 任务组的调度 cookie |
Uclamp (Utilization Clamping)
| 字段 | 类型 | 描述 |
|---|---|---|
uclamp | struct uclamp_rq | 利用率限制值数组 |
uclamp_flags | unsigned int | 利用率限制的标志位 |
NOHZ
| 字段 | 类型 | 描述 |
|---|---|---|
nohz_tick_stopped | unsigned int | 无滴答模式是否激活 |
nohz_flags | atomic_t | 无滴答模式的状态标志 |
负载均衡
| 字段 | 类型 | 描述 |
|---|---|---|
balance_callback | struct balance_callback * | 负载均衡的回调函数 |
active_balance | int | 活动负载均衡状态 |
push_cpu | int | 需要推送任务到的目标 CPU |
active_balance_work | struct cpu_stop_work | 活动负载均衡的工作结构 |
其他重要字段
| 字段 | 类型 | 描述 |
|---|---|---|
prev_mm | struct mm_struct * | 上一个任务的地址空间 |
next_balance | unsigned long | 下一次负载均衡的时间 |
sd | struct sched_domain * | 调度的域结构指针 |
rd | struct root_domain * | 根域指针 |
leaf_cfs_rq_list | struct list_head | CPU 的CFS叶子队列列表 |
hrtick_timer | struct hrtimer | 高精度调度定时器 |
1.1.2 struct cfs_rq(完全公平调度系统CFS的rq)
”80% of CFS’s design can be summed up in a single sentence: CFS basically models an “ideal, precise multi-tasking CPU” on real hardware. “
上述表明:CFS 80%的设计可以总结为:”CFS在真实硬件下建模了一个”理想的,精确的多任务CPU“ 。
”理想的多任务CPU“ 是一种具有100%物理算力的CPU,它能让每个任务精确地以 相同的速度 并行运行,速度为1/nr_running。举例来说,如果有两个任务正在执行。如果有两个任务正在运行,那么每个任务获得50%物理算力——即真正的并行。
在真实的硬件上,一次只能运行一个任务。由此,任务的 虚拟运行时间表明,它的下一个时间片将在上文描述的理想多任务CPU上开始执行。在实践中,任务的 虚拟运行时间由它的真实运行时间相较于正在运行的任务总数归一化计算得到。
(1)实现细节
在CFS中,其任务选择逻辑是基于p->se.vruntime的值:总是试图选择p->se.vruntime值 最小的任务运行(至今执行时间最少的任务)。CFS总是尽可能尝试按”理想多任务硬件“那样将CPU时间在可运行任务中均分。
(2)CFS的一些特征
CFS不像其他的调度器那样有”时间片“的概念,也没有任何启发式设计。CFS调度器处理nice级别和SCHED_BATCH的能力比之前的原始调度更强:两种类型的工作负载隔离了。
(3)调度策略
CFS实现了三种调度策略:
- SCHED_NORMAL: 用于普通任务
- SCHED_BATCH: 抢占不像普通任务那样频繁,因此允许任务运行更长时间。更好利用缓存,不过要以交互性为代价,它很适合批处理工作。
- SCHED_IDLE:不是真正的idle定时调度器,因为要避免给机器 带来死锁的优先级反转问题
(4)代码定义
/* CFS-related fields in a runqueue */
struct cfs_rq {struct load_weight load;unsigned int nr_queued;unsigned int h_nr_queued; /* SCHED_{NORMAL,BATCH,IDLE} */unsigned int h_nr_runnable; /* SCHED_{NORMAL,BATCH,IDLE} */unsigned int h_nr_idle; /* SCHED_IDLE */s64 avg_vruntime;u64 avg_load;u64 min_vruntime;
#ifdef CONFIG_SCHED_COREunsigned int forceidle_seq;u64 min_vruntime_fi;
#endifstruct rb_root_cached tasks_timeline;/** 'curr' points to currently running entity on this cfs_rq.* It is set to NULL otherwise (i.e when none are currently running).*/struct sched_entity *curr;struct sched_entity *next;#ifdef CONFIG_SMP/** CFS load tracking*/struct sched_avg avg;
#ifndef CONFIG_64BITu64 last_update_time_copy;
#endifstruct {raw_spinlock_t lock ____cacheline_aligned;int nr;unsigned long load_avg;unsigned long util_avg;unsigned long runnable_avg;} removed;#ifdef CONFIG_FAIR_GROUP_SCHEDu64 last_update_tg_load_avg;unsigned long tg_load_avg_contrib;long propagate;long prop_runnable_sum;/** h_load = weight * f(tg)** Where f(tg) is the recursive weight fraction assigned to* this group.*/unsigned long h_load;u64 last_h_load_update;struct sched_entity *h_load_next;
#endif /* CONFIG_FAIR_GROUP_SCHED */
#endif /* CONFIG_SMP */#ifdef CONFIG_FAIR_GROUP_SCHEDstruct rq *rq; /* CPU runqueue to which this cfs_rq is attached *//** leaf cfs_rqs are those that hold tasks (lowest schedulable entity in* a hierarchy). Non-leaf lrqs hold other higher schedulable entities* (like users, containers etc.)** leaf_cfs_rq_list ties together list of leaf cfs_rq's in a CPU.* This list is used during load balance.*/int on_list;struct list_head leaf_cfs_rq_list;struct task_group *tg; /* group that "owns" this runqueue *//* Locally cached copy of our task_group's idle value */int idle;#ifdef CONFIG_CFS_BANDWIDTHint runtime_enabled;s64 runtime_remaining;u64 throttled_pelt_idle;
#ifndef CONFIG_64BITu64 throttled_pelt_idle_copy;
#endifu64 throttled_clock;u64 throttled_clock_pelt;u64 throttled_clock_pelt_time;u64 throttled_clock_self;u64 throttled_clock_self_time;int throttled;int throttle_count;struct list_head throttled_list;struct list_head throttled_csd_list;
#endif /* CONFIG_CFS_BANDWIDTH */
#endif /* CONFIG_FAIR_GROUP_SCHED */
};1.2 schedule()函数流程
schedule()↓
__schedule_loop()↓
__schedule()├─ 关闭中断/加锁├─ 更新时钟├─ 检查并阻塞当前任务├─ 选取下一个可运行任务├─ 清理调度请求├─ 上下文切换 (context_switch)└─ 解锁/恢复中断__schdule()函数的流程:
- 关闭内核抢占,标识cpu状态,通知RCU更新状态,关闭本地中断,获取要保护的运行队列的自旋锁。为查找可运行进程作准备。
- 检查prev状态,决定是否将进程插入到运行队列,或者从运行队列中删除
- task_on_rq_queued(prev):将prev进程插入到运行队列的队尾
- pick_next_task():核心调度算法,决定下一个进程
- context_switch():执行实际的上下文切换,包含进程状态保存与恢复
- try_to_block():尝试将当前任务从运行队列中移除(阻塞)
- clear_tsk_need_resched(),clear_preempt_need_resched():清楚需要调度的标志
- 追踪调度事件
- 保证Read-Copy Update即RCU读写机制的安全
local_irq_disable();local_irq_disable();
rcu_note_context_switch(preempt);rq_lock(rq, &rf);preempt = sched_mode == SM_PREEMPT;
if (sched_mode == SM_IDLE) {/* SCX must consult the BPF scheduler to tell if rq is empty */if (!rq->nr_running && !scx_enabled()) {next = prev;goto picked;}} else if (!preempt && prev_state) {try_to_block_task(rq, prev, prev_state);switch_count = &prev->nvcsw;}......next = pick_next_task(rq, prev, &rf);......
if(likely(is_switch))
{......trace_sched_switch(preempt, prev, next, prev_state);/* Also unlocks the rq: */rq = context_switch(rq, prev, next, &rf);
}
else......trace_sched_exit_tp(is_switch, CALLER_ADDR0);2.调度算法:策略 + 优先级
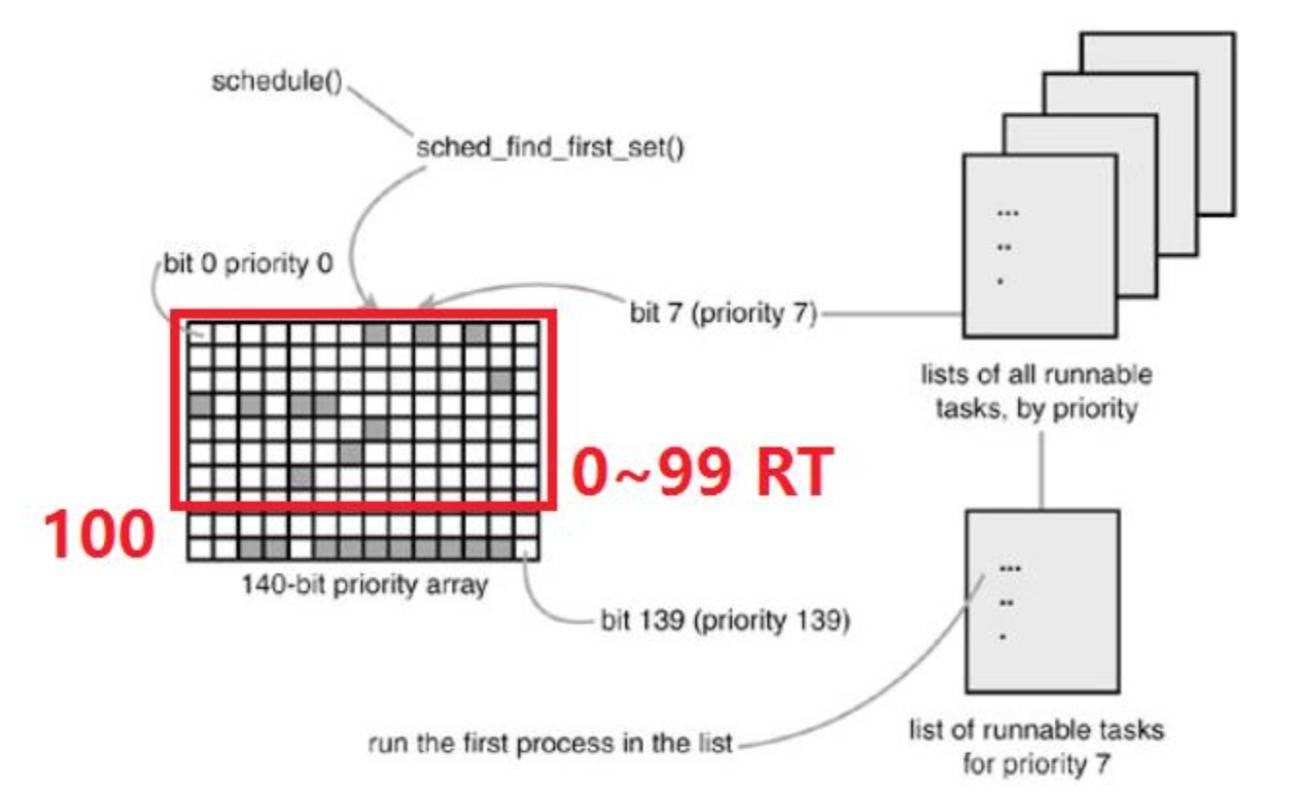
早期2.6调度器:优先级数组 和 Bitmaps
- 0~ 139: 在内核空间, 把整个Linux优先级划分为0~139,数字越小,优先级越高。用户空间设置时,是反过来的。
- 某个优先级有TASK_RUNNING进程,响应bit设置1。
- 调度第一个bitmap设置为1的进程
Linux内核三种主要调度策略:
- SCHED_OTHER 分时调度策略
- SCHED_FIFO 实时调度策略,先到先服务
- SCHED_RR 实时调度策略,时间片轮转
实时进程将得到优先调用,实时进程根据实时优先级决定调度权值。分时进程则通过 nice 和 counter值决定权值,nice值越小,counter值越大,被调度的概率越大,也就是曾经使用了cpu最少的进程将会得到优先调度。
SCHED_FIFO、SCHED_RR
实时(RT)进程调度策略: 0~99采用的RT,100~139是非RT的。
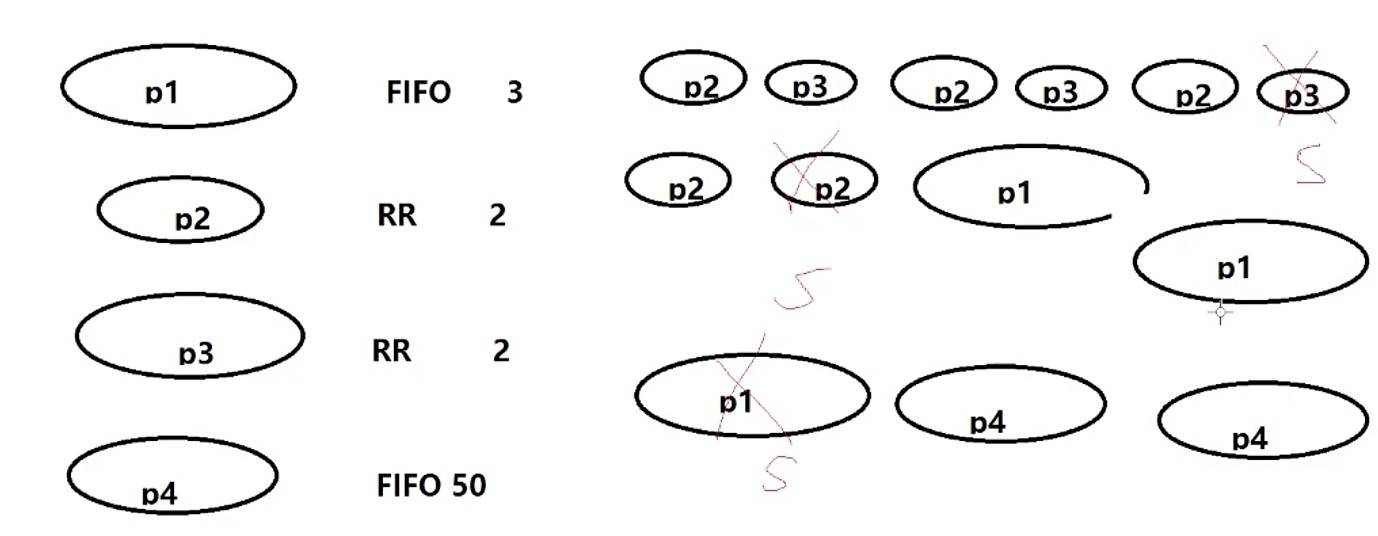
- SCHED_FIFO: 不同优先级按照优先级高的先跑到睡眠,优先级低的再跑;同等优先级先进先出。SCHED_FIFO一旦占用cpu则一直运行,直到有更高的优先级任务的到达或自己放弃。
- SCHED_RR:不同优先级按照优先级高的先跑到睡眠,优先级低的再跑;同等优先级轮转。
- 相同点:
- 都适用于实时调度任务
- 创建时优先级大于0(1-99)
- 按照可抢占优先级调度算法
- 就绪态的实时任务立即抢占非实时任务
当所有的SCHED_FIFO和SCHED_RR都运行至睡眠态,就开始运行 100~139之间的 普通task_struct。这些进程讲究 nice,
SCHED_NORMAL
- Linux 内核中最常用的进程调度策略,适用于绝大部分普通用户进程(非实时进程)。
- 它是一种分时(time-sharing)调度策略,用于保证多用户、多任务系统中各个普通进程“公平共享”CPU 资源。
非实时进程的调度和动态优先级:
早期内核2.6的调度器,100对应nice值为 -20,139对应nice值为19。对于普通进程,优先级高不会形成对优先级低的绝对优势,并不会阻塞优先级低的进程拿到时间片。
普通进程在不同优先级之间进行轮转,nice值越高,优先级越低。此时优先级的具体作用是:1、时间片。优先级高的进程可以得到更多时间片。
2、抢占。从睡眠状态到醒来,可以优先去抢占优先级低的进程。
Linux根据睡眠情况,动态奖励和惩罚。 越睡,优先级越高。想让CPU消耗型进程和IO消耗型进程竞争时,IO消耗型的进程可以竞争过CPU消耗型。
)

)



