Spark是一种基于内存的快速、通用、可拓展的大数据分析计算引擎。Hadoop是一个分布式系统基础架构。
(1)官网地址:http://spark.apache.org/
(2)文档查看地址:https://spark.apache.org/docs/3.3.1/
(3)下载地址:https://spark.apache.org/downloads.html
处理速度对比:
Hadoop:Hadoop MapReduce 基于磁盘进行数据处理,数据在 Map 和 Reduce 阶段会频繁地写入磁盘和读取磁盘,这使得数据处理速度相对较慢,尤其是在处理迭代式算法和交互式查询时,性能会受到较大影响。
Spark:Spark 基于内存进行计算,能将数据缓存在内存中,避免了频繁的磁盘 I/O。这使得 Spark 在处理大规模数据的迭代计算、交互式查询等场景时,速度比 Hadoop 快很多倍。例如,在机器学习和图计算等需要多次迭代的算法中,Spark 可以显著减少计算时间。
Spark的内置模块
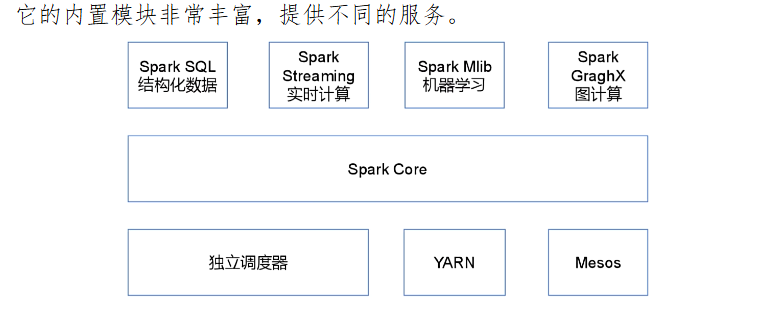 Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简RDD)的API定义。
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简RDD)的API定义。
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。
集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。
Spark的运行模式
 如果资源(cpu,内存)是当前单节点提供的,那么称之为单机模式。如果资源(cpu,内存)是当前多节点提供的,那么称之为分布式模式。
如果资源(cpu,内存)是当前单节点提供的,那么称之为单机模式。如果资源(cpu,内存)是当前多节点提供的,那么称之为分布式模式。
大多数分布式框架都支持单机模式:就是运行在一台计算机上的模式,方便开发者调试框架的运行环境。但是在生产环境中,并不会使用单机模式。因此,后续直接按照集群模式部署Spark集群。
Spark详细的部署模式:
(1)Local模式:单机模式,在本地部署单个Spark服务
(2)Standalone模式:集群模式,Spark自带的任务调度模式。
(3)YARN模式:集群模式,Spark使用Hadoop的YARN组件进行资源与任务调度。
(4)Mesos模式:集群模式,Spark使用Mesos平台进行资源与任务的调度。


》逐章精华笔记第五章)
)


