深度学习中的 Dropout 技术在代码层面上的实现通常非常直接。其核心思想是在训练过程中,对于网络中的每个神经元(或者更精确地说,是每个神经元的输出),以一定的概率 p 随机将其输出置为 0。在反向传播时,这些被“drop out”的神经元也不会参与梯度更新。
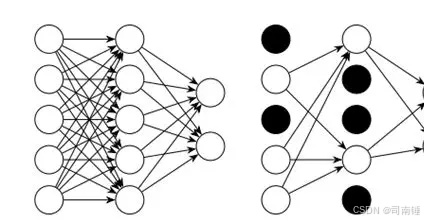
以下是 Dropout 在代码层面上的一个基本实现逻辑,以 Python 和 NumPy 为例进行说明,然后再展示在常见的深度学习框架(如 TensorFlow 和 PyTorch)中的实现方式。
1. NumPy 实现(概念演示)
假设我们有一个神经网络的某一层输出 activation,它是一个形状为 (batch_size, num_neurons) 的 NumPy 数组。我们可以通过以下步骤实现 Dropout:
Python
import numpy as npdef dropout_numpy(activation, keep_prob):"""使用 NumPy 实现 Dropout。Args:activation: 神经网络层的激活输出 (NumPy array).keep_prob: 保留神经元的概率 (float, 0 到 1 之间).Returns:经过 Dropout 处理的激活输出 (NumPy array).mask: 用于记录哪些神经元被 drop out 的掩码 (NumPy array)."""if keep_prob < 0. or keep_prob > 1.:raise ValueError("keep_prob must be between 0 and 1")# 生成一个和 activation 形状相同的随机掩码,元素值为 True 或 Falsemask = (np.random.rand(*activation.shape) < keep_prob)# 将掩码应用于激活输出,被 drop out 的神经元输出置为 0output = activation * mask# 在训练阶段,为了保证下一层的期望输入不变,需要对保留下来的神经元输出进行缩放output /= keep_probreturn output, mask# 示例
batch_size = 64
num_neurons = 128
activation = np.random.randn(batch_size, num_neurons)
keep_prob = 0.8dropout_output, dropout_mask = dropout_numpy(activation, keep_prob)print("原始激活输出的形状:", activation.shape)
print("Dropout 后的激活输出的形状:", dropout_output.shape)
print("Dropout 掩码的形状:", dropout_mask.shape)
print("被 drop out 的神经元比例:", np.sum(dropout_mask == False) / dropout_mask.size)
代码解释:
keep_prob: 这是保留神经元的概率。Dropout 的概率通常设置为1 - keep_prob。- 生成掩码 (
mask): 我们使用np.random.rand()生成一个和输入activation形状相同的随机数数组,其元素值在 0 到 1 之间。然后,我们将这个数组与keep_prob进行比较,得到一个布尔类型的掩码。True表示对应的神经元被保留,False表示被 drop out。 - 应用掩码 (
output = activation * mask): 我们将掩码和原始的激活输出进行逐元素相乘。由于布尔类型的True和False在数值运算中会被转换为 1 和 0,所以掩码中为False的位置对应的激活输出会被置为 0。 - 缩放 (
output /= keep_prob): 这是一个非常重要的步骤。在训练阶段,由于一部分神经元被随机置为 0,为了保证下一层神经元接收到的期望输入与没有 Dropout 时大致相同,我们需要对保留下来的神经元的输出进行放大。放大的倍数是1 / keep_prob。
需要注意的是,在模型的评估(或推理)阶段,通常不会使用 Dropout。这意味着 keep_prob 会被设置为 1,或者 Dropout 层会被禁用。这是因为 Dropout 是一种在训练时使用的正则化技术,用于减少过拟合。在评估时,我们希望模型的所有神经元都参与计算,以获得最准确的预测。
2. TensorFlow 实现
在 TensorFlow 中,Dropout 是一个内置的层:
Python
import tensorflow as tf# 在 Sequential 模型中添加 Dropout 层
model = tf.keras.models.Sequential([tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)),tf.keras.layers.Dropout(0.2), # Dropout 概率为 0.2 (即 keep_prob 为 0.8)tf.keras.layers.Dense(10, activation='softmax')
])# 或者在函数式 API 中使用
inputs = tf.keras.Input(shape=(784,))
x = tf.keras.layers.Dense(128, activation='relu')(inputs)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = tf.keras.layers.Dense(10, activation='softmax')(x)
model_functional = tf.keras.Model(inputs=inputs, outputs=outputs)# 训练模型
# model.compile(...)
# model.fit(...)
在 TensorFlow 的 tf.keras.layers.Dropout(rate) 层中,rate 参数指定的是神经元被 drop out 的概率。在训练时,这个层会随机将一部分神经元的输出置为 0,并对剩下的神经元进行缩放。在推理时,这个层不会有任何作用。TensorFlow 内部会自动处理训练和推理阶段的行为。
3. PyTorch 实现
在 PyTorch 中,Dropout 也是一个内置的模块:
代码段
import torch
import torch.nn as nnclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(784, 128)self.relu = nn.ReLU()self.dropout = nn.Dropout(p=0.2) # Dropout 概率为 0.2self.fc2 = nn.Linear(128, 10)self.softmax = nn.Softmax(dim=1)def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.dropout(x)x = self.fc2(x)x = self.softmax(x)return xmodel = Net()# 设置模型为训练模式 (启用 Dropout)
model.train()# 设置模型为评估模式 (禁用 Dropout)
model.eval()# 在前向传播中使用 Dropout
# output = model(input_tensor)
在 PyTorch 的 nn.Dropout(p) 模块中,p 参数指定的是神经元被 drop out 的概率。与 TensorFlow 类似,PyTorch 的 Dropout 在训练模式 (model.train()) 下会启用,随机将神经元置零并缩放输出。在评估模式 (model.eval()) 下,Dropout 层会失效,相当于一个恒等变换。
总结
在代码层面上,Dropout 的实现主要涉及以下几个步骤:
- 生成一个随机的二值掩码,其形状与神经元的输出相同,掩码中每个元素以一定的概率(Dropout 概率)为 0,以另一概率(保留概率)为 1。
- 将这个掩码与神经元的输出逐元素相乘,从而将一部分神经元的输出置为 0。
- 在训练阶段,对保留下来的神经元的输出进行缩放,通常除以保留概率。
- 在评估阶段,禁用 Dropout,即不进行掩码操作和缩放。
现代深度学习框架已经将 Dropout 的实现封装在专门的层或模块中,用户只需要指定 Dropout 的概率即可,框架会自动处理训练和评估阶段的不同行为。这大大简化了在模型中应用 Dropout 的过程。

)




