🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
Fine-tune Re-ranking Models : 初学者指南
我们之前探索了为特定领域微调嵌入模型,这是改进检索系统的关键一步。今天,我们要更进一步,深入研究微调重排序模型(reranking models)。嵌入模型帮助我们检索出相关文档,而重排序器则进一步优化这些结果,确保最准确、最符合上下文的匹配。
在本篇博客中,我会带你一步步了解我的方法,重点关注数据准备和微调自定义重排序器。
让我们开始吧!
交叉编码器(Cross Encoders)
交叉编码器是一种主要用于自然语言处理(NLP)的神经网络架构,用于需要理解两段文本之间关系的任务,例如句子对。它们在语义相似性、问答和自然语言推理等任务中特别有效。
交叉编码器的工作原理:
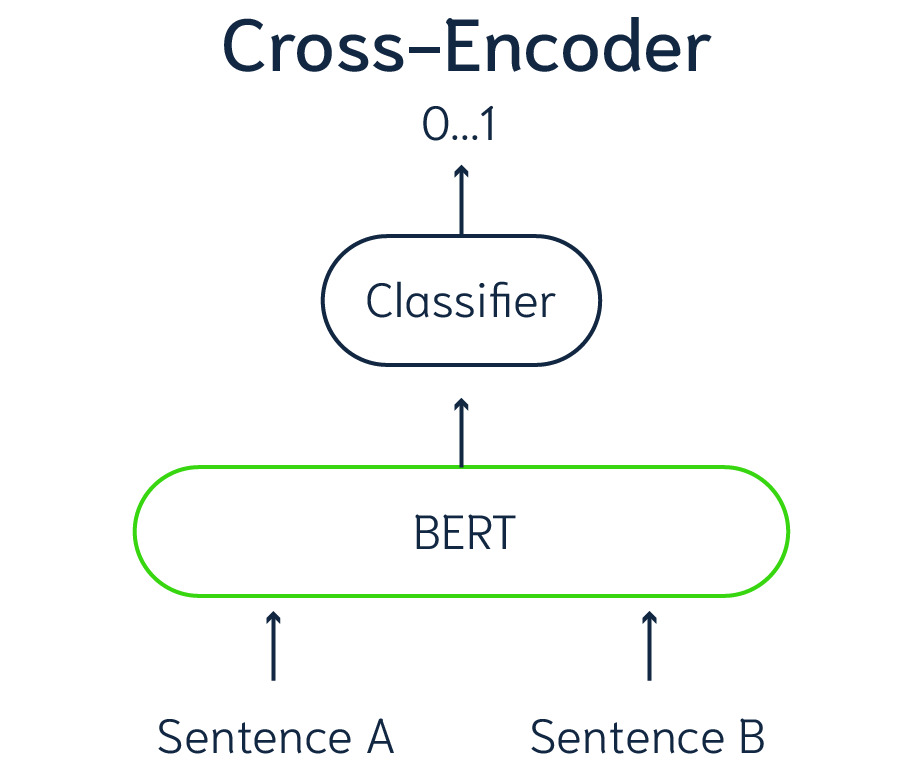
它是如何工作的
输入对处理:
- 两段文本会被拼接在一起,通常用一个特殊标记(如
[SEP])分隔。例如,在 BERT 风格的模型中,格式通常是:
[CLS] Text1 [SEP] Text2 [SEP] - 这种格式允许模型同时处理两个输入。
联合编码:
- 与独立编码文本的 双编码器(bi-encoders) 不同,交叉编码器会一起处理拼接后的序列,从而能够捕捉两段文本之间的逐词交互。
- 这使得交叉编码器在需要理解深层关系的任务中更加准确,但计算成本也比双编码器更高。
输出:
- 输出通常是从
[CLS]令牌的最终隐藏状态中得出的,它作为整个序列的表示。 - 对于二分类任务(如语义相似性),一个分数或概率可以表示两段文本之间的关系。对于其他任务,额外的层可能会产生更复杂的输出。
应用场景:
- 语义文本相似性(Semantic Textual Similarity, STS):判断两个句子的相似程度。
- 自然语言推理(Natural Language Inference, NLI):判断假设是否由前提推导而来,是否矛盾,或者是否中立。
- 问答系统:根据与问题的相关性对候选答案进行排序。
- 信息检索:在初步检索步骤之后对候选文档或段落进行重排序。
重排序(Re-ranking)
在 检索增强型生成(Retrieval-Augmented Generation, RAG) 中,重排序是一个关键步骤,用于在生成最终答案之前优化检索到的文档或段落的质量。RAG 结合了基于检索的方法(从大型语料库中获取相关文档)和生成模型(根据检索到的内容生成答案)。重排序确保最相关和高质量的文档被优先用于生成步骤。
为什么在 RAG 中重排序很重要
重排序的需求源于初步检索阶段的局限性。检索器(如稀疏检索器 BM25 或密集检索器如双编码器)可能会返回大量候选文档,但这些文档并不是完全按照与查询的相关性排序的。重排序通过使用更复杂的模型(如交叉编码器)来重新评估每个文档与查询的相关性,从而优化文档的顺序。将最相关的文档传递给生成模型后,最终输出(无论是答案还是总结)会更加准确且符合上下文。
重排序在 RAG 中的工作原理
在实践中,重排序是多步骤流程的一部分。
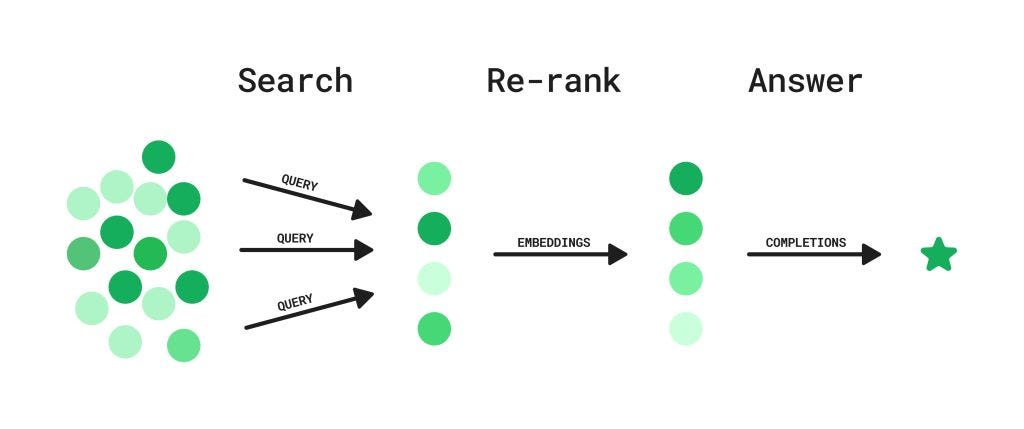
初步检索:
- 检索器(例如 BM25、DPR 或密集嵌入模型)根据输入查询从大型语料库中获取一组候选文档或段落。
重排序:
- 重排序器(例如交叉编码器)评估每个检索到的文档与查询的相关性。
- 交叉编码器同时处理查询和每个文档,捕捉细微的交互,并生成相关性分数。
- 文档根据这些分数重新排序。
生成:
- 排名最高的前 k 个文档被传递给生成模型(例如 GPTs、LLAMAs 或 Qwen)。
- 生成模型根据最相关的文档生成最终输出(例如答案)。
微调重排序模型
微调重排序模型对于针对特定任务或领域的优化至关重要。虽然像 BERT 或 RoBERTa 这样的预训练模型对语言有一般性的理解,但它们可能无法针对像按查询相关性对文档进行排序这样的任务进行定制。
微调使模型能够适应任务,提高准确性和相关性评分。它帮助模型学习特定任务的关系、特定领域的知识以及隐含的上下文联系,这对于准确的重排序至关重要。微调还可以使模型与目标数据分布对齐,增强模型对输入数据中的噪声和变化(例如拼写错误或改述的查询)的鲁棒性。
在特定领域(例如医疗或法律)以及有标注数据的情况下,微调尤为重要。通过微调,重排序模型能够更好地优化检索到的文档,确保为下游任务(如 RAG 中的问答系统)提供更高质量的输入。
数据集格式
在微调重排序模型时,通常使用两种数据集格式:连续分数格式和离散类别格式。
连续分数格式涉及句子对或文本对以及一个连续的相关性分数(例如介于 0 和 1 之间)。例如,使用 sentence-transformers 库中的 InputExample 类,你可以定义像 ["sentence1", "sentence2"] 这样的对,并用标签 0.3 或 0.8 表示两段文本之间的相关性或相似性程度。这种格式适用于相关性分级的任务,如语义文本相似性或文档排序。
示例:
train_samples = [InputExample(texts=["sentence1", "sentence2"], label=0.3),InputExample(texts=["Another", "pair"], label=0.8),
]
离散类别格式则使用预定义的类别来表示句子对之间的关系。例如,在自然语言推理(NLI)任务中,对被标记为“矛盾”、“蕴含”或“中立”,这些类别分别映射到整数值(例如 0、1、2)。这种格式适用于需要分类的任务,例如判断句子之间的逻辑关系。这两种格式在微调重排序模型中都被广泛使用,具体选择取决于特定任务和数据的性质。
示例:
label2int = {"contradiction": 0, "entailment": 1, "neutral": 2}
train_samples = [InputExample(texts=["sentence1", "sentence2"], label=label2int["neutral"]),InputExample(texts=["Another", "pair"], label=label2int["entailment"]),
]
生成用于微调的合成数据
在微调重排序模型时,拥有高质量的训练数据至关重要。如果你能获取到实际部署解决方案中的真实数据,那自然是最好的选择。真实数据反映了你的系统实际处理的查询和文档,能够确保微调后的模型与你的具体用例对齐。你可以从像 Langfuse、LangSmith 或 LlamaTrace 这样的可观察性工具中收集数据,这些工具跟踪 LLM 应用中的交互,并提供查询 - 文档对及其相关性的洞察。
然而,如果真实数据不可用,你可以生成合成数据来微调模型。我使用的方法虽然有些非传统,但非常有效。以下是思路:
我利用一个检索器(例如向量存储)为一组查询检索候选文档,然后使用 Cohere 的 rerank-v3.5,这是一个最先进的重排序模型,来优化检索到的文档并分配相关性分数。通过从这些优化后的结果中采样,我创建了一个模拟高质量重排序器行为的数据集。这种方法允许我的微调模型从更优秀模型的重排序模式中学习,有效地提取其知识。
此外,我在采样过程中引入随机性,让模型接触到各种各样的查询 - 文档对,确保它能够很好地泛化到各种场景。虽然合成数据可能无法完美复制真实世界的分布,但这种方法在真实数据稀缺时提供了一种实用的微调启动方式。
Bge-reranker-base(我们的基础模型)
BAAI/bge-reranker-base 是一个高性能的交叉编码器模型,专为文本重排序任务设计,由 北京人工智能研究院(BAAI) 开发。它是 BAAI General Embedding (BGE) 系列的一部分,专注于改进像 RAG(Retrieval-Augmented Generation)这样的检索增强型系统,我们将使用这个模型进行微调,并用它来对 llama-index 检索到的文档进行重排序。
开始编码
安装必要的库
要开始,你需要安装所需的库。运行以下命令来安装所有依赖项:
pip install sentence-transformers llama-index llama-index-llms-gemini llama-index-embeddings-gemini llama-index-postprocessor-cohere-rerank
设置环境变量
在深入代码之前,请确保你拥有 Google 和 Cohere 的 API 密钥。这些密钥用于认证并使用它们各自的服务。将它们存储为环境变量,以便在脚本中安全且方便地访问:
当然 你也可以利用国内的云商进行微调 比如某度云
import os
GOOGLE_API_KEY = "xxxxxxxxx"
os.environ["GOOGLE_API_KEY"] = GOOGLE_API_KEY
COHERE_API_KEY = "xxxxxxxxxxxxxxx"
os.environ["COHERE_API_KEY"] = COHERE_API_KEY
导入必要的库
接下来,导入脚本中将要使用的库和模块。这些包括用于文档加载、文本分割、嵌入生成、重排序和微调的工具。以下是导入列表:
from llama_index.core.evaluation import generate_question_context_pairs
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.postprocessor.cohere_rerank import CohereRerank
from sentence_transformers import CrossEncoder, InputExample
from llama_index.embeddings.gemini import GeminiEmbedding
from llama_index.core.node_parser import SentenceSplitter
from sentence_transformers import InputExample
from llama_index.llms.gemini import Gemini
from torch.utils.data import DataLoader
from llama_index.core import Settings
import pandas as pd
import random
定义模型和 Cohere 重排序器
现在,定义你将要使用的语言模型(LLM)和嵌入模型。在本例中,我们使用 Gemini 用于文本生成和嵌入。
# 定义模型llm = Gemini(model="models/gemini-1.5-flash",
)
embed_model = GeminiEmbedding(model_name="models/embedding-001", api_key=GOOGLE_API_KEY
)
Settings.embed_model = embed_model
Settings.llm = llm
设置 Cohere 重排序器,它将用于优化检索到的文档。top_n 参数指定要重排序的文档数量,model 参数指定 Cohere 重排序器的版本(例如 rerank-v3.5)。
# 定义 Cohere 重排序器cohere_rerank = CohereRerank(api_key=COHERE_API_KEY, top_n=5 , model="rerank-v3.5") # top_n 是要重排序的文档数量
准备数据
创建问答数据集
为了生成用于微调的合成数据集,我们首先需要从一组文档中创建一个问答数据集。create_qa_dataset 函数负责这个过程。它接收一个包含文档的目录,将文档分割成较小的片段(例如 256 个标记),并使用语言模型(LLM)为每个片段生成问题。每个片段生成的问题数量是可自定义的,这让你可以控制数据集的密度。
def create_qa_dataset(input_dir , llm , num_questions_per_chunk):"""从文档目录创建问答数据集参数:input_dir: str包含文档的目录llm: llama_index.llms.gemini.Gemini用于生成问题的语言模型num_questions_per_chunk: int每个片段生成的问题数量返回:list: 问题列表"""documents = SimpleDirectoryReader(input_dir=input_dir).load_data()node_parser = SentenceSplitter(chunk_size=256)nodes = node_parser.get_nodes_from_documents(documents)qa_dataset = generate_question_context_pairs(nodes,llm=llm,num_questions_per_chunk=num_questions_per_chunk)queries = qa_dataset.queries.values()return list(queries) , documents
这个函数输出一个问题列表和对应的文档,为下一步奠定了基础。
创建评分查询上下文数据集
一旦我们有了问题,就需要将它们与相关上下文配对,并分配相关性分数。create_score_query_context_dataset 函数通过利用检索器和 Cohere 重排序器来完成这个任务。
def create_score_query_context_dataset(queries , documents , split) :"""创建包含查询、上下文和分数的数据集参数:queries: list查询列表documents: list文档列表split: str数据集的划分返回:pd.DataFrame: 包含查询、上下文和分数的 DataFrame"""contexts = []scores = []# 创建索引index = VectorStoreIndex.from_documents(documents)# 创建检索器retriever = index.as_retriever(verbose=True, similarity_top_k=10)for query in queries: # 检索 top-10 文档nodes = retriever.retrieve(query) # 使用 Cohere 重排序并获取 top-5 文档response = cohere_rerank.postprocess_nodes(nodes=nodes, query_str=query)random_number = random.randint(0, len(response)-1)contexts.append(response[random_number].text)scores.append(response[random_number].score)assert len(queries) == len(contexts) == len(scores)df = pd.DataFrame({"query": queries, "context": contexts, "score": scores})df.to_csv(f"{split}-data.csv", index=False)return df
以下是工作原理:
- 索引文档:使用向量存储对文档进行索引,以便高效检索相关片段。
- 检索和重排序:对于每个查询,检索器检索 top-k 文档(例如 top-10)。这些文档随后通过 Cohere 重排序器进行优化。
- 随机采样:为了引入多样性,从重排序后的结果中随机选择一个文档。这确保模型能够接触到各种各样的查询 - 上下文对。
- 数据集创建:将查询、上下文及其对应的相关性分数编译成一个 DataFrame,并保存为 CSV 文件以供后续使用。
创建训练数据集
为了准备训练数据集,我们首先使用 create_qa_dataset 函数生成问答数据集。该函数处理指定目录(/content/train_data)中的文档,将它们分割成片段,并使用 Gemini 语言模型为每个片段生成问题。每个片段生成的问题数量设置为 1,确保数据集既专注又易于管理。
# 创建训练数据集queries , documents = create_qa_dataset("/content/train_data", llm , 1 )
train_data = create_score_query_context_dataset(queries , documents , "train")
train_samples = [InputExample(texts=[row['query'], row['context']], label=row['score'])for _, row in train_data.iterrows()
]
train_dataloader = DataLoader(train_samples, shuffle=True, batch_size=8)
一旦准备好查询和文档,我们使用 create_score_query_context_dataset 函数创建评分查询上下文数据集。该函数检索并重排序每个查询的文档,分配相关性分数,并将数据编译成结构化格式。得到的数据集随后被转换为 InputExample 对象列表,用于创建训练用的 DataLoader。DataLoader 会打乱数据,并以 8 个一批 的方式处理数据,从而优化训练过程。
创建验证数据集
验证数据集的创建过程类似。
# 创建验证数据集queries , documents = create_qa_dataset("/content/val_data", llm , 1)
val_data = create_score_query_context_dataset(queries , documents , "validation")
val_samples = [InputExample(texts=[row['query'], row['context']], label=row['score'])for _, row in val_data.iterrows()
]
val_dataloader = DataLoader(val_samples, shuffle=True, batch_size=3)
初始化模型
开始微调之前,我们初始化一个预训练的 交叉编码器 模型。在本例中,我们使用 BAAI/bge-reranker-base 模型作为基础模型。我们之前已经介绍过它啦。
# 初始化预训练的交叉编码器模型model = CrossEncoder('BAAI/bge-reranker-base')
创建自定义评估器
为了在训练过程中监控模型的性能,我们定义了一个名为 MSEEval 的自定义评估器。这个评估器计算模型预测的相关性分数与真实分数之间的均方误差(MSE)。它会记录结果,并将它们保存到 CSV 文件中,方便跟踪。
评估器使用验证数据集(val_dataloader)定期评估模型的性能。
from sentence_transformers.evaluation import SentenceEvaluator
import torch
from torch.utils.data import DataLoader
import logging
from sentence_transformers.util import batch_to_device
import os
import csv
from sentence_transformers import CrossEncoder
from tqdm.autonotebook import tqdmlogger = logging.getLogger(__name__)class MSEEval(SentenceEvaluator):"""基于标记数据集评估模型的准确性这需要一个具有 Softmax 损失函数的模型结果将写入 CSV 文件。如果 CSV 文件已存在,则追加值。"""def __init__(self,dataloader: DataLoader,name: str = "",show_progress_bar: bool = True,write_csv: bool = True):"""构造给定数据集的评估器:param dataloader:评估数据"""self.dataloader = dataloaderself.name = nameself.show_progress_bar = show_progress_barif name:name = "_"+nameself.write_csv = write_csvself.csv_file = "accuracy_evaluation"+name+"_results.csv"self.csv_headers = ["epoch", "steps", "accuracy"]def __call__(self, model: CrossEncoder, output_path: str = None, epoch: int = -1, steps: int = -1) -> float:model.model.eval()total = 0loss_total = 0if epoch != -1:if steps == -1:out_txt = " after epoch {}:".format(epoch)else:out_txt = " in epoch {} after {} steps:".format(epoch, steps)else:out_txt = ":"loss_fnc = torch.nn.MSELoss()activation_fnc = torch.nn.Sigmoid()logger.info("在 "+self.name+" 数据集上进行评估"+out_txt)self.dataloader.collate_fn = model.smart_batching_collatefor features, labels in tqdm(self.dataloader, desc="评估", smoothing=0.05, disable=not self.show_progress_bar):with torch.no_grad():model_predictions = model.model(**features, return_dict=True)logits = activation_fnc(model_predictions.logits)if model.config.num_labels == 1:logits = logits.view(-1)loss_value = loss_fnc(logits, labels)total += 1 # 批次数量loss_total += loss_value.cpu().item()mse = loss_total/totallogger.info("MSE: {:.4f} ({}/{})\n".format(mse, loss_total, total))if output_path is not None and self.write_csv:csv_path = os.path.join(output_path, self.csv_file)if not os.path.isfile(csv_path):with open(csv_path, newline='', mode="w", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow(self.csv_headers)writer.writerow([epoch, steps, mse])else:with open(csv_path, newline='', mode="a", encoding="utf-8") as f:writer = csv.writer(f)writer.writerow([epoch, steps, mse])return mse
定义好评估器后,我们使用验证数据加载器初始化它:
# 创建评估器evaluator = MSEEval(val_dataloader,show_progress_bar=True , write_csv=True )
训练模型
准备好模型和评估器后,我们使用训练数据集对模型进行微调。fit 方法用于训练模型,以下是关键参数:
train_dataloader:训练数据,按批次处理。evaluator:用于在训练过程中监控性能的自定义评估器。epochs:训练轮数(本例中设置为 1)。warmup_steps:用于稳定训练的热身步数。evaluation_steps:在训练过程中评估的频率。output_path:保存微调后模型的目录。save_best_model:是否根据评估结果保存表现最佳的模型。use_amp:是否使用自动混合精度(AMP)以加快训练速度。scheduler:学习率调度器(例如 warmupcosine)。show_progress_bar:是否在训练过程中显示进度条。
# 训练模型model.fit(train_dataloader=train_dataloader,evaluator=evaluator,epochs=1,warmup_steps=100,evaluation_steps=3,output_path="my_model",save_best_model=True,use_amp=True,scheduler= 'warmupcosine',show_progress_bar=True,
)
登录并推送模型到模型中心
微调完成后,你可以将模型保存并分享到 Hugging Face 模型中心。这让你可以对模型进行版本控制、与他人协作,甚至将其部署到生产环境中。
为此,你需要使用 notebook_login 函数登录到你的 Hugging Face 账户。这将提示你输入 Hugging Face 的凭据。
from huggingface_hub import notebook_login
notebook_login()
登录后,你可以使用 push_to_hub 方法将微调后的模型推送到模型中心。将 user/bge-reranker-base-finetuned 替换为你想要的仓库名称。这将把模型权重、配置和其他必要文件上传到模型中心。
model.push_to_hub("user/bge-reranker-base-finetuned")
在 LlamaIndex 中使用微调后的模型
将模型上传到模型中心后,你可以轻松地将其集成到 LlamaIndex 流水线中进行重排序。[SentenceTransformerRerank](https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/SentenceTransformerRerank) 类允许你加载微调后的模型,并用它来对检索到的文档进行重排序。top_n 参数指定重排序后返回的文档数量。
from llama_index.core.postprocessor import SentenceTransformerRerankrerank = SentenceTransformerRerank(model="user/bge-reranker-base-finetuned", top_n=3
)
微调重排序模型是继嵌入模型之后的自然下一步,它是提高系统理解和优先级排序能力的强大方式。从生成合成数据到训练和评估模型,每一步都有其挑战和回报。无论你是使用真实数据还是创建自己的数据集,关键是要不断实验、迭代和完善。希望这份指南能激发你在自己的项目中探索微调的潜力。
祝调优愉快!


)


