一:位图
位图是一种高效的数据结构,它通过比特来表示某个值的存在与否,通常以连续的二进制位数组存储。每个比特位对应一个特定的状态,这种表示方式在内存效率和操作速度上具有显著优势,尤其适用于海量数据、整数以及数据不重复的场景。位图一般用于快速判断某个数据是否存在。
小技巧:10 亿个字节大概是 0.9 G,可看做是 1 G,10 亿个比特位大概是 119 兆,看做 128 兆
1.1 位图的实现
public class MyBitSet {private byte[] elem; // 存储位的数组,每个元素是一个字节public int usedSize; // 已使用的比特位数量// 默认构造函数,初始化大小为1的字节数组public MyBitSet() {elem = new byte[1];}// 根据指定的比特位数量 n 初始化字节数组public MyBitSet(int n) {elem = new byte[n / 8 + 1]; // 确保有足够的字节来存储 n 个比特位}// 将指定值 val 对应的比特位设置为 1public void set(int val) {if (val < 0) {throw new IndexOutOfBoundsException(); // 检查 val 是否为负}int arrayIndex = val / 8; // 计算对应的字节索引int bitIndex = val % 8; // 计算比特位在字节中的位置this.elem[arrayIndex] |= (1 << bitIndex); // 将对应的比特位设置为 1usedSize++; // 增加已使用的比特计数}// 检查指定值 val 对应的比特位是否为 1public boolean get(int val) {if (val < 0) {throw new IndexOutOfBoundsException(); // 检查 val 是否为负}int arrayIndex = val / 8; // 计算对应的字节索引int bitIndex = val % 8; // 计算比特位在字节中的位置return (this.elem[arrayIndex] & (1 << bitIndex)) != 0; // 返回该比特位的状态}// 将指定值 val 对应的比特位设置为 0public void reSet(int val) {if (val < 0) {throw new IndexOutOfBoundsException(); // 检查 val 是否为负}int arrayIndex = val / 8; // 计算对应的字节索引int bitIndex = val % 8; // 计算比特位在字节中的位置this.elem[arrayIndex] &= ~(1 << bitIndex); // 将对应的比特位设置为 0usedSize--; // 减少已使用的比特计数}// 返回当前已使用比特位的数量public int getUsedSize() {return this.usedSize; // 返回已使用的比特位数量}
}
1.2 位图的应用
- 快速判断某个数据是否在集合中。
- 对集合进行排序和去重。
- 计算两个集合的交集和并集。
- 在操作系统中进行磁盘块的标记管理。
二:布隆过滤器
2.1 布隆过滤器的概念
布隆过滤器是由布隆(Burton Howard Bloom)于1970年提出的一种紧凑且高效的概率型数据结构。其特点在于快速的插入和查询操作,能够判断某个元素“一定不存在”或“可能存在”。它通过多个哈希函数将数据映射到位图中。这种方式不仅提高了查询效率,还显著节省了内存空间。
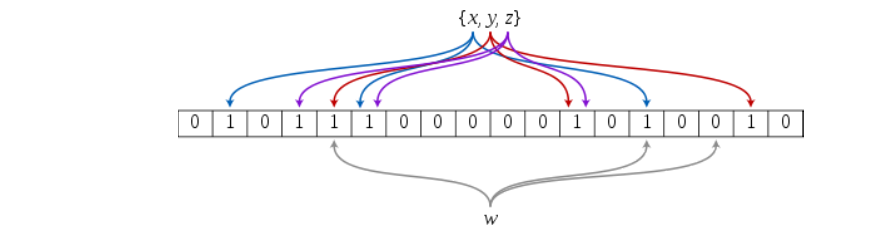
2.2 布隆过滤器的插入
现在向布隆过滤器中插入 baidu:
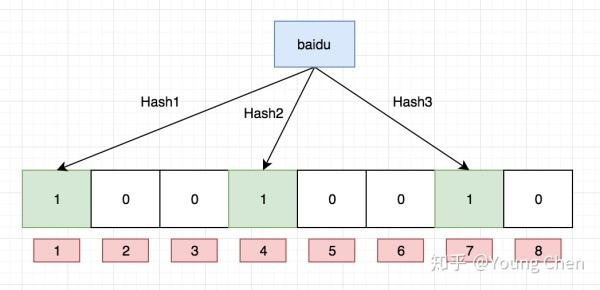
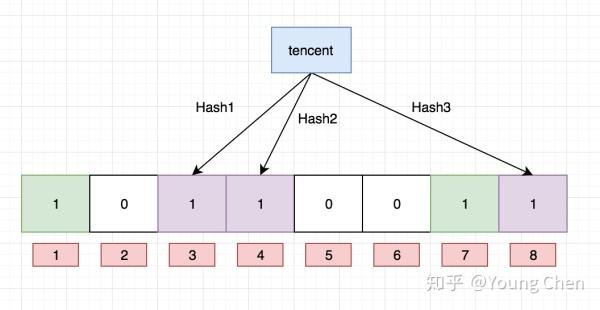
通过定义的三个哈希函数,接着对字符串 baidu 进行哈希运算。这些哈希函数会生成三个索引值,接着把对应位置标记为 1,所以当你当需要判断某个元素是否在布隆过滤器中时,首先同样通过哈希函数计算出对应的索引,接着判断这些索引是不是都是 1,如果是的话说明这个东西可能存在,如果有一个不是 1,那么就说明这个东西一定不存在。
注意:布隆过滤器可以准确地判断某个元素“绝对不存在”,但如果判断某个元素“可能存在”,则可能出现误判。这是因为哈希函数可能导致冲突,从而使得某些不存在的元素被误认为可能存在。
2.3 布隆过滤器模拟实现
import java.util.BitSet;// 构建哈希函数类
class SimpleHash {private int cap; // 位图的容量private int seed; // 随机种子// 构造函数,初始化容量和随机种子public SimpleHash(int cap, int seed) {this.cap = cap;this.seed = seed;}// 将字符串转变为一个哈希值public int hash(String value) {int result = 0;int len = value.length();// 遍历字符串的每个字符for (int i = 0; i < len; i++) {result = seed * result + value.charAt(i); // 基于种子的哈希计算}return (cap - 1) & result; // 返回哈希值,确保结果在位图范围内}
}// 布隆过滤器类
public class BloomFilter {private static final int DEFAULT_SIZE = 1 << 24; // 默认位图大小private static final int[] seeds = new int[]{5, 7, 11, 13, 31, 37, 61}; // 多个哈希函数的种子private BitSet bits; // 位图用于存储元素private SimpleHash[] func; // 哈希函数数组private int size = 0; // 已存储元素数量// 构造函数,初始化位图和哈希函数public BloomFilter() {bits = new BitSet(DEFAULT_SIZE); // 初始化位图func = new SimpleHash[seeds.length]; // 初始化哈希函数数组// 为每个种子创建一个哈希函数for (int i = 0; i < seeds.length; i++) {func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);}}// 向布隆过滤器中添加元素public void set(String value) {if (value == null) return; // 检查值是否为null// 对每个哈希函数计算对应的位图位置并设置为1for (SimpleHash f : func) {bits.set(f.hash(value));}size++; // 增加已存储元素的计数}// 判断某个元素是否存在于布隆过滤器中public boolean contains(String value) {if (value == null) return false; // 检查值是否为null// 检查所有哈希函数对应的位图位置for (SimpleHash f : func) {if (!bits.get(f.hash(value))) { // 若有任何位置为0,则确定不存在return false;}}return true; // 若所有位置均为1,返回可能存在(存在误判的可能性)}
}
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
三:并查集
在某些应用场景中,需要将 n 个不同元素划分为若干个不相交的集合。最初,每个元素自成一个单元素集合,之后根据一定的规则合并属于同一组的元素。在这个过程中,需要反复查询某个元素所属的集合。这种适用于描述此类问题的抽象数据类型称为并查集。
-
这是最初的状态:
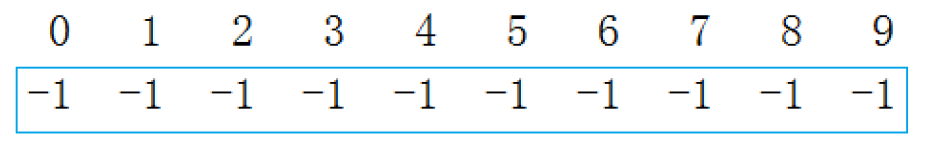
-
这里划分成了 3 个集合
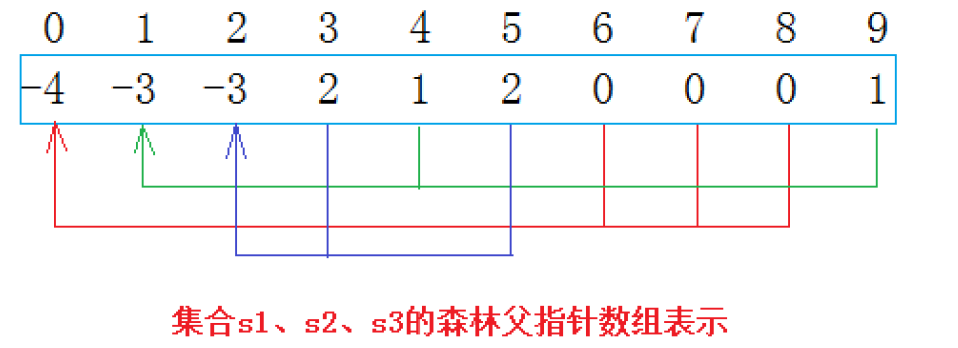
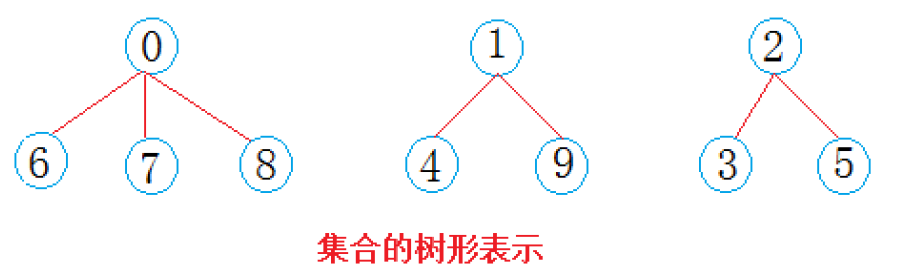
-
这里又合并了两个集合
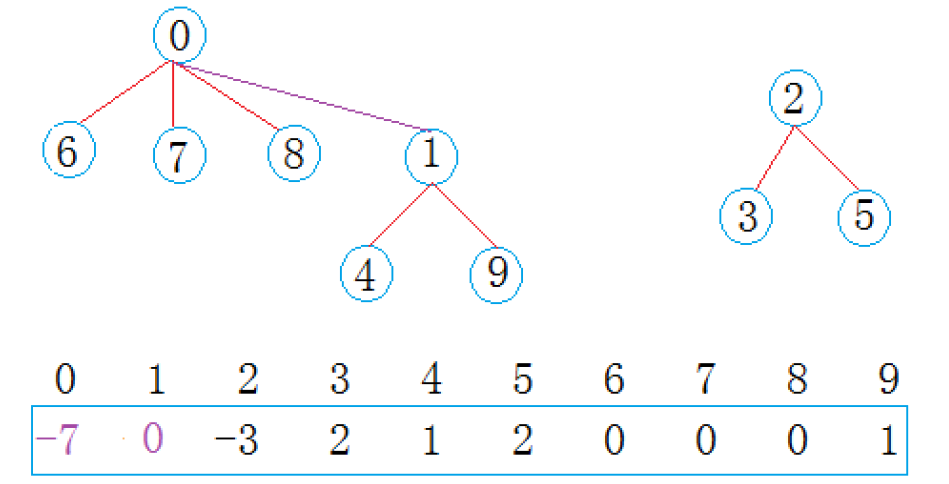
在 0 集合有 7 个人,2 集合有 3 个人,总共两个集合。通过以上例子可知,并查集一般可以解决一下问题:
-
查找元素所属集合:沿着数组表示的树形结构,递归向上查找,直到找到根节点,即数组中值为负数的位置。
-
判断两个元素是否在同一集合:沿着树形结构向上查找两个元素的根节点。如果根节点相同,则说明这两个元素属于同一个集合;否则,它们不在同一集合中。
-
合并两个集合:将两个集合的元素合并为一个集合,并将一个集合的名称替换为另一个集合的名称。
-
计算集合个数:遍历数组,统计其中特殊元素(值为负数)的数量,这个数量便是当前集合的个数。
3.1 并查集实现
package unionfindset;import java.util.Arrays;public class UnionFindSet {private int[] elem; // 用于存储集合信息的数组// 构造函数,初始化并查集public UnionFindSet(int n) {this.elem = new int[n]; // 创建一个大小为 n 的数组Arrays.fill(elem, -1); // 初始化所有元素为 -1,表示每个元素自成一个集合}// 查找元素 x 的根节点public int findRoot(int x) {// 检查参数是否合法if (x < 0 || x >= elem.length) {throw new IndexOutOfBoundsException("数据不合法");}// 通过不断向上查找直到找到根节点while (elem[x] >= 0) {x = elem[x];}return x; // 返回根节点}// 合并两个集合,x1 和 x2 必须是它们各自的根节点public void union(int x1, int x2) {int index1 = findRoot(x1); // 查找 x1 的根节点int index2 = findRoot(x2); // 查找 x2 的根节点if (index1 == index2) return; // 如果两个元素已经在同一个集合中,则不需要合并// 合并两个集合,更新元素统计elem[index1] = elem[index1] + elem[index2]; // 更新根节点的大小elem[index2] = index1; // 将 x2 的根指向 x1 的根}// 判断两个元素是否在同一个集合中public boolean isSameSet(int x1, int x2) {int index1 = findRoot(x1); // 查找 x1 的根节点int index2 = findRoot(x2); // 查找 x2 的根节点return index1 == index2; // 返回根节点是否相同}// 获取当前集合的个数public int getCount() {int count = 0; // 初始化集合计数// 遍历 elem 数组,统计根节点的数量for (int x : elem) {if (x < 0) {count++; // 每当找到一个根节点,计数器加一}}return count; // 返回集合总数}// 打印当前集合的信息public void printArr() {for (int i = 0; i < elem.length; i++) {System.out.print(elem[i] + " "); // 打印每个元素的值}System.out.println(); // 打印新行}
}
四:LRUCache
LRU(Least Recently Used,最近最少使用)是一种缓存替换算法。由于缓存 Cache 的容量有限,当缓存满时,需要根据一定原则选择并舍弃部分原有内容,以腾出空间用于存储新内容。LRU缓存的替换原则是替换最近最少使用的内容,因此也可以理解为“最久未使用”,因为该算法每次替换的都是在一段时间内最久没有被使用过的数据。
实现LRU缓存的方法和思路有很多,但要达到高效的 O(1) 时间复杂度的 put 和 get 操作,结合双向链表和哈希表是最经典和高效的方案。双向链表允许在任意位置以 O(1) 的时间复杂度进行插入和删除操作,而哈希表则支持 O(1) 的增删查改。这两种数据结构的结合使得LRU缓存既能够快速访问,也能高效管理缓存中元素的使用顺序。
4.1 模拟实现 LRUCache
import java.util.HashMap;
import java.util.Map;public class LRUCache {// 定义双向链表节点类class DLinkedNode {int key; // 节点的 keyint value; // 节点的 valueDLinkedNode prev; // 前驱节点DLinkedNode next; // 后继节点// 默认构造函数public DLinkedNode() {}// 带参数的构造函数public DLinkedNode(int _key, int _value) {key = _key;value = _value;}}// 哈希表,用于存储 key 和对应的 DLinkedNode 节点private Map<Integer, DLinkedNode> cache = new HashMap<>();private int size; // 当前缓存的大小private int capacity; // 缓存的最大容量private DLinkedNode head, tail; // 伪头部和伪尾部节点// 构造函数,初始化缓存容量public LRUCache(int capacity) {this.size = 0; // 初始化大小为 0this.capacity = capacity; // 设置缓存的最大容量head = new DLinkedNode(); // 创建伪头部节点tail = new DLinkedNode(); // 创建伪尾部节点head.next = tail; // 头节点的 next 指向尾节点tail.prev = head; // 尾节点的 prev 指向头节点}// 获取缓存中指定 key 的值public int get(int key) {DLinkedNode node = cache.get(key); // 在哈希表中查找 keyif (node == null) { // 如果没有找到,返回 -1return -1;}moveTail(node); // 将找到的节点移动到链表的尾部return node.value; // 返回节点的值}// 将指定节点移动到链表的尾部private void moveTail(DLinkedNode node) {removeNode(node); // 先移除该节点addToTail(node); // 然后将其添加到尾部}// 移除指定节点private void removeNode(DLinkedNode node) {node.prev.next = node.next; // 让前驱节点指向后继节点node.next.prev = node.prev; // 让后继节点指向前驱节点}// 将指定节点添加到链表的尾部private void addToTail(DLinkedNode node) {tail.prev.next = node; // 让当前尾部节点的前驱指向新节点node.next = tail; // 新节点的 next 指向 tail(伪尾部)node.prev = tail.prev; // 新节点的 prev 指向原来的尾部节点tail.prev = node; // 更新尾部节点的 prev 指向新节点}// 添加新元素到缓存public void put(int key, int value) {DLinkedNode node = cache.get(key); // 查找 key 对应的节点if (node == null) { // 如果节点不存在DLinkedNode newNode = new DLinkedNode(key, value); // 创建新节点cache.put(key, newNode); // 将新节点添加到哈希表addToTail(newNode); // 将新节点添加到链表的尾部++size; // 更新当前缓存的大小if (size > capacity) { // 如果超出了容量限制DLinkedNode headNode = removeHead(); // 移除链表的头部节点cache.remove(headNode.key); // 从哈希表中删除对应的 key--size; // 更新当前缓存的大小}} else { // 如果节点已存在node.value = value; // 更新节点的值moveTail(node); // 将该节点移到链表的尾部}}// 删除链表的头部节点(最少使用的节点)private DLinkedNode removeHead() {DLinkedNode ret = head.next; // 获取头部节点head.next = ret.next; // 让伪头部指向下一个节点ret.next.prev = head; // 更新下一个节点的 prev 指向伪头部return ret; // 返回删除的节点}
}






