在了解了线程的基本概念和线程互斥与同步之后,我们可以以此设计一个简单的线程池。【Linux】线程-CSDN博客
【Linux】线程同步与互斥-CSDN博客
线程池也是一种池化技术。提前申请一些线程,等待有任务时就直接让线程去执行,不用再收到任务之后再创建线程。
一.日志设计
以往,我们多线程在向显示器打印信息时,会出现信息混杂的现象。这是因为多线程向显示器打印信息时,显示器是一种临界资源。访问临界资源应该对其进行保护,否则就会出现数据不一致。为了解决该现象,我们可以设计处一个日志类,打印信息时都使用该类,所以,我们得保证该类打印信息是原子的。
1.策略模式
策略模式(Strategy Pattern)是一种行为设计模式,它使你能在运行时改变对象的行为。其主要思想是将算法或行为封装到独立的类中,这些类称为策略类。上下文类(Context)使用策略类来执行特定的算法或行为,而客户端可以根据需要选择不同的策略。
我们可以根据策略模式设计出不同的刷新策略,比如向显示器刷新,或者向指定路径的指定文件刷新。
而策略模式的具体实现方式就是先实现一个策略类,里面包含了一个虚函数,该虚函数是未来要执行的行为或者算法。
然后我们再通过继承的方式具体的实现某一个种策略。
namespace MyLog
{using namespace MutexModule;#define gap "\r\n"// 策略模式——刷新策略// 虚基类class logstrategy{public:~logstrategy() = default;virtual void synclog(const std::string &message) = 0;};// 刷新策略1--->向显示器刷新class consolelogstrategy : public logstrategy{public:~consolelogstrategy() {}void synclog(const std::string &message) override{// 向显示器刷新需要加锁mutexguard lock(_mutex);std::cout << message << gap;}private:Mutex _mutex;};// 刷新策略2--->向指定文件里刷新const std::string defaultPath = "./log";const std::string defaultName = "log.log";class filelogstrategy : public logstrategy{public:filelogstrategy(const std::string &path = defaultPath, const std::string &name = defaultName): _path(path),_file(name){// 指定路径存在,直接返回;不存在,创建路径if (std::filesystem::exists(_path)){return;}try{std::filesystem::create_directories(_path);}catch (const std::filesystem::filesystem_error &e){std::cerr << e.what() << '\n';}}~filelogstrategy() {}void synclog(const std::string &message) override{// 向指定文件里打印, 向指定文件里面打印也得是原子的,得加锁mutexguard lock(_mutex);// 拼接路径+文件名std::string filename = _path + (_path.back() == '/' ? "" : "/") + _file;// 向指定文件里面以追加方式写入std::ofstream out(filename, std::ios::app);out << message << gap;out.close();}private:std::string _path;std::string _file;Mutex _mutex;};
}说明:我们实现了两种刷新策略,向显示器刷新、向指定路径的指定文件刷新。但不论哪种刷新方式,我们都得保证是原子的,即任意时刻只能有一个线程刷新,这样就不会产生数据混杂的情况。所以,这里我们实现原子性的方法是借助互斥锁。
2.日志类
有了刷新策略之后,下一步便是处理日志的具体内容了。这里我们期望打印出来的日志包含以下信息:
[时间][日志等级][进程pid][文件名][行号] - 日志正文
[2025-5-4 10:05:48][INFO][828670][thread.hpp][38]- create newthread-1 success
[2025-5-4 10:05:48][INFO][828670][thread.hpp][38]- create newthread-2 success
[2025-5-4 10:05:48][INFO][828670][thread.hpp][38]- create newthread-3 success
[2025-5-4 10:05:48][INFO][828670][thread.hpp][38]- create newthread-4 success
[2025-5-4 10:05:48][INFO][828670][thread.hpp][38]- create newthread-5 success
对于日志类来说,他首先得有自己的刷新策略,所以日志类包含一个成员那就是刷新策略,并且我们得指定默认的刷新策略:
class logger{public:logger(){// 默认使用显示器刷新策略UseConsoleStrategy();}~logger() {}void UseConsoleStrategy() { _fflush_strategy = std::make_unique<consolelogstrategy>(); }void UseFileLogStrategy() { _fflush_strategy = std::make_unique<filelogstrategy>(); }private:std::unique_ptr<logstrategy> _fflush_strategy;}有了刷新方式之后,我们下一步便是处理日志内容了。这里我们采取内部类的方式,实现日志内容的设计:
// 获取时间std::string GetTime(){// 1.获取当前的时间戳time_t cur_time = time(nullptr);// 2.将时间戳转化为年月日-时分秒struct tm format_time;localtime_r(&cur_time, &format_time);char time_buffer[128] = {0};snprintf(time_buffer, sizeof(time_buffer), "%d-%d-%d %d:%02d:%02d",format_time.tm_year + 1900,format_time.tm_mon + 1,format_time.tm_mday,format_time.tm_hour,format_time.tm_min,format_time.tm_sec);return time_buffer;}// 日志等级enum class loglevel{DEBUG,INFO,WARINING,ERROR,FATAL};// 获取日志等级std::string loglevelToString(loglevel level){switch (level){case loglevel::DEBUG:return "DEBUG";case loglevel::INFO:return "INFO";case loglevel::WARINING:return "WARNING";case loglevel::ERROR:return "ERROR";case loglevel::FATAL:return "FATAL";default:return "UNKNOEN";}} // 内部类// 用来描述日志具体内容class logmessage{public:logmessage(loglevel &level, const std::string &name, int number, logger &logger): _cur_time(GetTime()),_log_level(level),_file(name),_line_number(number),_pid(getpid()),_logger(logger){// 将格式化信息写入ss字符串流中std::stringstream ss;ss << "[" << _cur_time << "]"<< "[" << loglevelToString(_log_level) << "]"<< "[" << _pid << "]"<< "[" << _file << "]"<< "[" << _line_number << "]"<< "- ";// 从字符串中获取字符串_format_info = ss.str();}~logmessage(){// 如果有刷新策略,在对象析构的时候进行刷新if (_logger._fflush_strategy){_logger._fflush_strategy->synclog(_format_info);}}// 日志的主要内容template <typename T>logmessage &operator<<(const T &message){std::stringstream ss;ss << message;_format_info += ss.str();return *this;}private:std::string _cur_time;loglevel _log_level;pid_t _pid;std::string _file;int _line_number;std::string _format_info;logger &_logger;}; // end of logmessage 内部类,用来处理日志的格式化内容以及主要内容有了以上内容,我们的日志类已经基本上实现了,但是我们还得再日志类中实现一个仿函数,该仿函数的返回值是内部类类型,有了内部类类型,我们就可以根据内部重载的<<运算符制作日志消息,最后在该内部类对象析构的时候进行刷新即可。所以我们在返回内部类对象时返回临时对象,并且不要接收,采取匿名的方式,这样它的声明周期就只有1行,该行结束就会自动刷新了。
// logger类内成员public:logmessage operator()(loglevel level, const std::string &file, int line){return logmessage(level, file, line, *this);}为了方便使用,我们直接在命名空间中,定义一个全局的logger对象,使用日志类的时候,直接使用该全局对象。全局对象访问仿函数来实现日志的构成和打印。所以我们的调用方式就变为:
Glogger(loglevel, filename, linenumber) << "xxx" << "xxx" << ...;但是这样还是不太优雅,我们还得手动设置文件名和行号。我们可以使用宏来简化使用。
#define LOG(level) Glogger(level, __FILE__, __LINE__)
#define USE_CONSOLE_STARATEGY Glogger.UseConsoleStrategy()
#define USE_FILE_LOG_STARATRGY Glogger.UseFileLogStrategy()二.线程池
线程池作为一种池化技术,可以提前申请好资源,当数据或者任务到来时,直接去处理,不用在创建线程了。
设计方案:
- 线程池要在创建的时候创建出多个线程,我们用数组将所有的线程管理起来。
- 除了线程外,还得有任务,所以我们还得有一个任务队列。
- 在处理任务时,和添加任务时都得是原子的,所以还得有互斥锁。
- 当任务队列为空时,但线程池还没有结束,所以我们得让所有的线程等待,所以还得有条件变量。
在创建线程池的时候,直接在构造函数创建n个线程即可,因为创建线程需要指定执行的方法,所以我们实现一个handler方法,用来让创建出的线程去执行。
ThreadPool(const int threads = defaultThreadSize):_num(threads), _isRunning(true), _sleepernumber(0){// 创建_num个线程for(int i=0; i<_num; i++){_threads.emplace_back([this](){Handler();});}}而对于handler方法来说,所有的线程都用从任务队列中获取任务,但任务队列作为临界资源,同一时刻只能有一个线程访问,所以我们必须得加锁。
但是还有一个问题,当线程池结束的时候,如果此时还有线程在等待,我们就应该叫醒它们,否则就会导致内存泄漏问题。所以,在判断线程需要等待时,需满足两个条件,线程池没有结束,并且没有任务,才需要等待,否则直接执行后面的代码。
在执行后面的代码时,我们需要判断线程池是否结束,如果结束了,并且没有任务,则直接让线程退出,否则执行完任务,在退出。
当线程拿到任务之后,就可以释放锁了,因为此时该任务已经属于该线程私有的了,如果再持有锁,就得等任务执行完才能获取下一个任务,导致效率底下。
void Handler(){// 获取线程名字char name[128] = { 0 };pthread_getname_np(pthread_self(), name, sizeof(name));// 从任务队列中获取任务while(true){T t;{// 加锁访问任务队列,任意时刻只能有一个线程访问任务队列mutexguard lock(_mutex);// 当线程池终止了,但有可能还有线程再等待,此时已经没有任务,其他的线程都已经被回收了,这些线程会导致内存泄露// 但是如果直接叫醒所有线程,它们不会退出循环,而是继续等待// 所以在进行等待的时候,要判断线程池是否还在运行,如果已经结束,并且任务队列为空,则不需要等待// 一个不满足,就必须等待while(_isRunning && _taskManager.empty()){// 任务队列为空,线程进行等待_sleepernumber++;_cond.Wait(_mutex);_sleepernumber--;}// 当线程池已经终止了&&任务队列为空,就让线程结束if(!_isRunning && _taskManager.empty()){LOG(loglevel::INFO) << name << "退出";break;}// 获取任务t = _taskManager.front();_taskManager.pop();}// 执行任务// 当一个线程加锁拿出任务后,这个任务已经从任务队列中消失了,只属于该线程私有,所以先解锁,再执行,提高效率。t();}}添加任务也会访问临界资源任务队列,所以也得加锁,当然也得保证线程池还在运行,否则就不添加。并且,添加之后,就有任务了,我们判断此时是否有线程再等待,如果有,则唤醒,让其获取任务。
// 向任务队列中新增任务bool emplace(const T& task){// 任意时刻,都只允许只有一个线程插入任务mutexguard lock(_mutex);if(!_isRunning) return false;_taskManager.emplace(task); if(_sleepernumber){WakeUpOne();}return true;}void WakeUpOne(){LOG(loglevel::INFO) << "唤醒一个线程";_cond.signal();}我们还得有接口,让线程池停止。停止运行之后,如果还有任务就继续执行,没有任务了,就让线程退出。但因为有可能还有线程再等待,它们收不到任务了,如果还等待的化,就会导致内存泄露问题,所以,再停止线程池之后,我们需要唤醒所有的线程。
void WakeUpAll(){if(_sleepernumber){LOG(loglevel::INFO) << "唤醒所有线程";_cond.broadcast();}}// 让线程池终止void Stop(){if(!_isRunning) return;_isRunning = false;LOG(loglevel::INFO) << "线程池已经被终止";// 线程池结束就让所有等待的线程苏醒,否则它们不会退出WakeUpAll();}// 回收线程void Join(){if(_isRunning) return;for(auto& thread : _threads){thread.Join();}}有了以上接口,我们的线程池就可以运行起来了。但是,如果在内存中同时存在多个线程池的话,就会导致资源提前被申请,导致后面来的任务申请不到线程了。也有可能线程池很多,但处理的热任务很少,就会导致资源浪费问题。
所以,我们期望,线程池只能被实例化出一份,即内存中只允许有一个线程池。借此,我们来引出,单例模式线程池。
1.单例模式线程池
所谓单例模式,其实就是一个类只能实例化出一个对象。
而实现单例模式有两中方案:饿汉模式和懒汉模式。
- 饿汉模式:在将代码加载到内存中时,就已经初始化了该对象
- 懒汉模式:在代码加载到内存中时,只初始化一个该类对象的指针,并不具体实例化。当真正使用的时候,在进行实例化
在一个类比较大的时候,在加载的时候直接创建对象比较耗时
懒汉模式采用延时创建技术,就可以加快启动进程的时候
在内核中,我们使用malloc申请内存空间,其实就使用了懒汉模式,先给你虚拟地址空间,当你使用该虚拟地址空间的时候,再给你从内存中开辟,并构建映射关系
我们这里采取懒汉模式实现单例:
首先,单例模式只能实例化一个对象,所以我们不应该将构造、拷贝构造,赋值函数等暴露出来。我们在类内定义一个静态的该类对象的指针。因为静态对象是全局的,所以在代码加载到内存中时,他就已经被创建了,但因为我们创建的是指针,所以还没有真正意义上创建对象。
static ThreadPool<T>* _inc; // 未来实例化出的对象
static Mutex _sm; // 用来实现单例模式我们提供一个静态函数,用来初始化静态对象,初始化该静态对象一定得是原子的,要不然如果该函数被多线程同时访问,就有可能创建多个对象。
static ThreadPool<T>* Getinstance(int threadsize = defaultThreadSize){LOG(loglevel::DEBUG) << "获取线程池单例...";if(!_inc){mutexguard lock(_sm); if(!_inc){LOG(loglevel::INFO) << "线程池单例创建....";_inc = new ThreadPool<T>(threadsize);}}return _inc;}我们这里采取双if判断,来提高获取单例的运行效率。如果没有外层的if,每一个线程都得先申请锁,然后再判断,申请锁的时候什么都做不了。就算我们单例创建好了,下一次还得申请锁,在判断。
所以我们额外添加一个if判断,单例还没有创建的时候确实没有变化,但对有已经有了单例来说,就可以让其他线程提前退出,获取到单例。
#ifndef __ThreadPool__HPP__
#define __ThreadPool__HPP__#include <iostream>
#include <queue>
#include "thread.hpp"
#include "log.hpp"
#include "mutex.hpp"
#include "cond.hpp"namespace ThreadPoolModule
{using namespace MyThread;using namespace MutexModule;using namespace MyCond;using namespace MyLog;// 默认使用5个线程的线程池const int defaultThreadSize = 5;template <typename T>class ThreadPool{private:void WakeUpAll(){if(_sleepernumber){LOG(loglevel::INFO) << "唤醒所有线程";_cond.broadcast();}}void WakeUpOne(){LOG(loglevel::INFO) << "唤醒一个线程";_cond.signal();}// 同一时刻,内存中不需要存在多个线程池// 利用单例模式来控制该进程池只能实例化出一个对象:单例模型即一个类只能实例化一个对象// 单例模式有两种实现方式:饿汉模型和懒汉模式// 饿汉模式:在将代码加载到内存中时,就已经初始化了该对象// 懒汉模式:在代码加载到内存中时,只初始化一个该类对象的指针,并不具体实例化。当真正使用的时候,在进行实例化// 在一个类比较大的时候,在加载的时候直接创建对象比较耗时// 懒汉模式采用延时创建技术,就可以加快启动进程的时候// 在内核中,我们使用malloc申请内存空间,其实就使用了懒汉模式,先给你虚拟地址空间,当你使用该虚拟地址空间的时候,再给你从内存中开辟,并构建映射关系// 因为单例模式只能创建一个对象,所以不应该将类的构造,拷贝构造,赋值重载函数公开ThreadPool(const int threads = defaultThreadSize):_num(threads), _isRunning(true), _sleepernumber(0){// 创建_num个线程for(int i=0; i<_num; i++){_threads.emplace_back([this](){Handler();});}}ThreadPool(const ThreadPool& tp) = delete;ThreadPool operator=(const ThreadPool& tp) = delete;public:// 有可能有多个执行流进入该函数,但是只能创建一个对象static ThreadPool<T>* Getinstance(int threadsize = defaultThreadSize){LOG(loglevel::DEBUG) << "获取线程池单例...";if(!_inc){mutexguard lock(_sm); if(!_inc){LOG(loglevel::INFO) << "线程池单例创建....";_inc = new ThreadPool<T>(threadsize);}}return _inc;}~ThreadPool(){}void Handler(){// 获取线程名字char name[128] = { 0 };pthread_getname_np(pthread_self(), name, sizeof(name));// 从任务队列中获取任务while(true){T t;{// 加锁访问任务队列,任意时刻只能有一个线程访问任务队列mutexguard lock(_mutex);// 当线程池终止了,但有可能还有线程再等待,此时已经没有任务,其他的线程都已经被回收了,这些线程会导致内存泄露// 但是如果直接叫醒所有线程,它们不会退出循环,而是继续等待// 所以在进行等待的时候,要判断线程池是否还在运行,如果已经结束,并且任务队列为空,则不需要等待// 一个不满足,就必须等待while(_isRunning && _taskManager.empty()){// 任务队列为空,线程进行等待_sleepernumber++;_cond.Wait(_mutex);_sleepernumber--;}// 当线程池已经终止了&&任务队列为空,就让线程结束if(!_isRunning && _taskManager.empty()){LOG(loglevel::INFO) << name << "退出";break;}// 获取任务t = _taskManager.front();_taskManager.pop();}// 执行任务// 当一个线程加锁拿出任务后,这个任务已经从任务队列中消失了,只属于该线程私有,所以先解锁,再执行,提高效率。t();}}// 让线程池终止void Stop(){if(!_isRunning) return;_isRunning = false;LOG(loglevel::INFO) << "线程池已经被终止";// 线程池结束就让所有等待的线程苏醒,否则它们不会退出WakeUpAll();}// 回收线程void Join(){if(_isRunning) return;for(auto& thread : _threads){thread.Join();}}// 向任务队列中新增任务bool emplace(const T& task){// 任意时刻,都只允许只有一个线程插入任务mutexguard lock(_mutex);if(!_isRunning) return false;_taskManager.emplace(task); if(_sleepernumber){WakeUpOne();}return true;}private:std::vector<Thread> _threads; // 线程池int _num; // 线程个数std::queue<T> _taskManager; // 任务队列Mutex _mutex; // 互斥锁cond _cond; // 信号量bool _isRunning; // 线程池是否运行int _sleepernumber; // 当前等待的线程个数static ThreadPool<T>* _inc; // 未来实例化出的对象static Mutex _sm; // 用来实现单例模式};// 初始化静态成员template <typename T>ThreadPool<T>* ThreadPool<T>::_inc = nullptr;template <typename T>Mutex ThreadPool<T>::_sm;
}#endif三.重入和线程安全
如果函数是可重入的,那么它就是线程安全的。
线程安全不一定是可重入的,而可重入的一定是线程安全的。
四.死锁
死锁是指一组线程中,都占有自己的资源,同时又向使用对方的资源,这样导致线程互相申请无法推进线程运行的现象就叫做死锁。
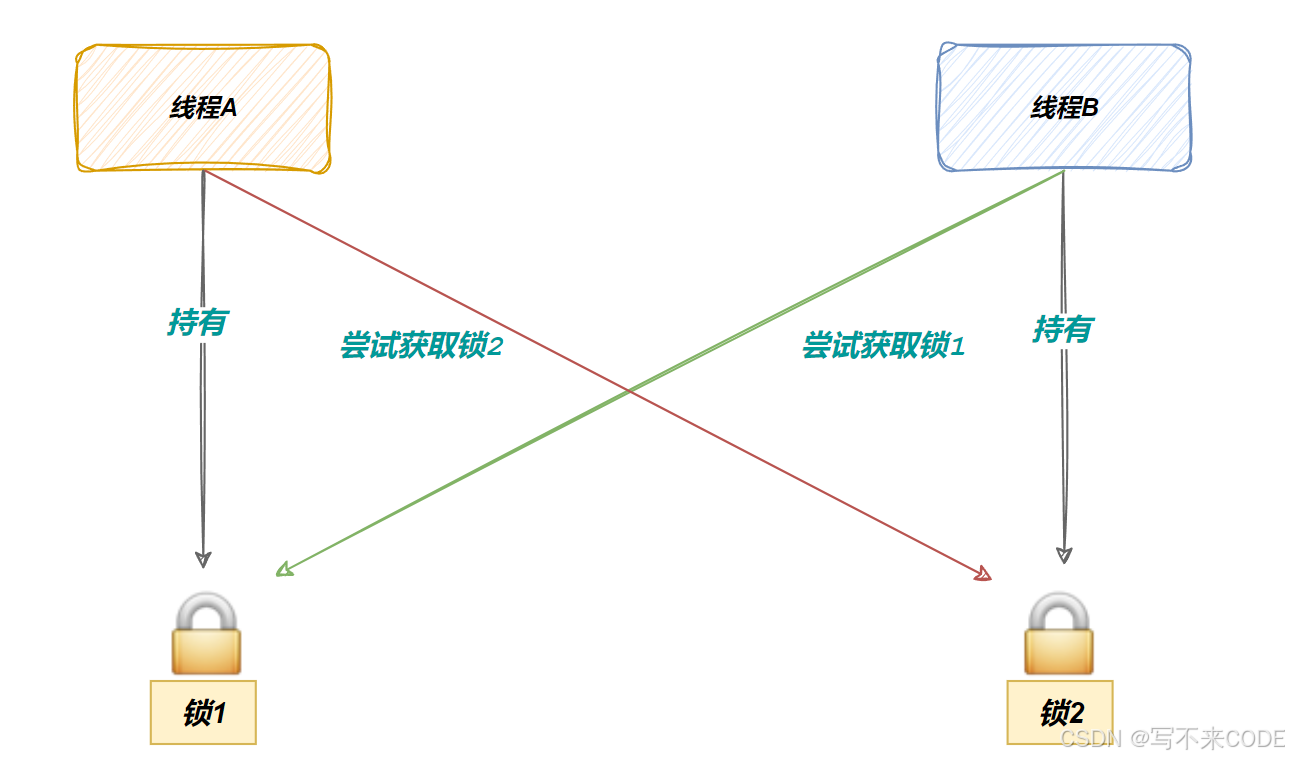
简单来说,线程A想要访问的资源必须同时持有锁1和锁2,线程B也一样。但此时线程A持有锁1,线程B持有锁2.而它们又同时访问对方的锁,这样就导致谁都申请不到锁,导致阻塞挂起。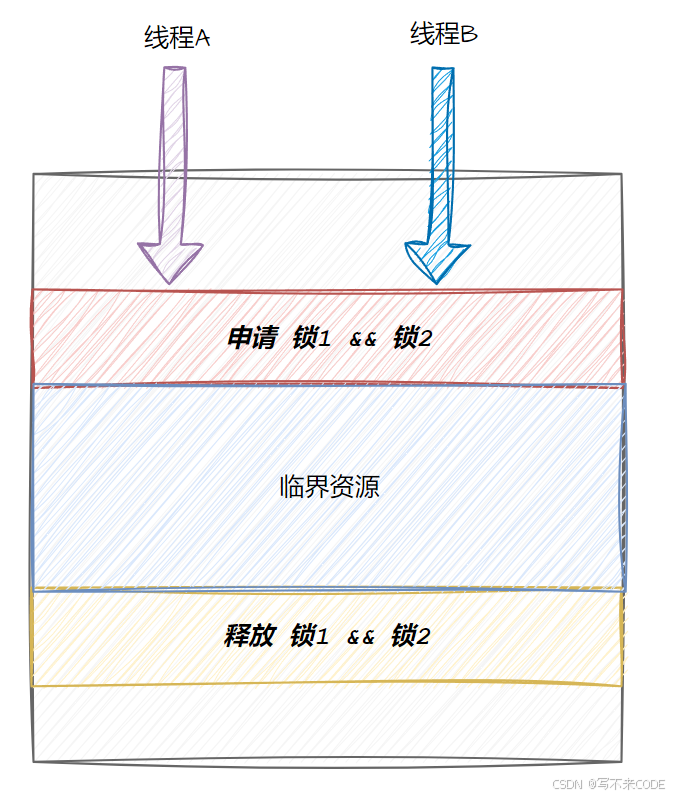

1.死锁的四个必要条件
- 0x1.互斥条件:一个临界资源只能被一个执行流访问
- 0x2.请求与保持条件:一个执行流因为请求而导致阻塞时,对已有的资源不释放
- 0x3.不剥夺条件:一个执行流已获得的资源,在未使用完前,不可被抢夺
- 0x4.循环等待条件:若干个执行流,采取循环的申请对方的资源,导致了头尾衔接的等待资源关系。
2.避免死锁
死锁产生上面四种条件必须同时具有,所以我们只需要破坏其中的条件即可,死锁就不会成立!!!!
解决方案1:我们可以使用trylock来申请锁,在申请另一个锁时,发现申请失败,就可以释放掉当前的锁,来让其他人获取。
当然还有其他方法来避免死锁,可以自行了解。
以上,便是单例线程池的所有内容!




