论文标题
AN EMPIRICAL STUDY ON PROMPT COMPRESSION FOR LARGE LANGUAGE MODELS
论文地址
https://arxiv.org/pdf/2505.00019
开源地址
https://github.com/3DAgentWorld/Toolkit-for-Prompt-Compression
作者背景
香港科技大学广州校区,华南理工大学,中科大
动机
大模型的上下文提示词越长,计算开销或API调用成本越高,加重了业务成本。因此,在保证模型输出质量的前提下减小提示词长度,成为一个紧迫而有价值的问题
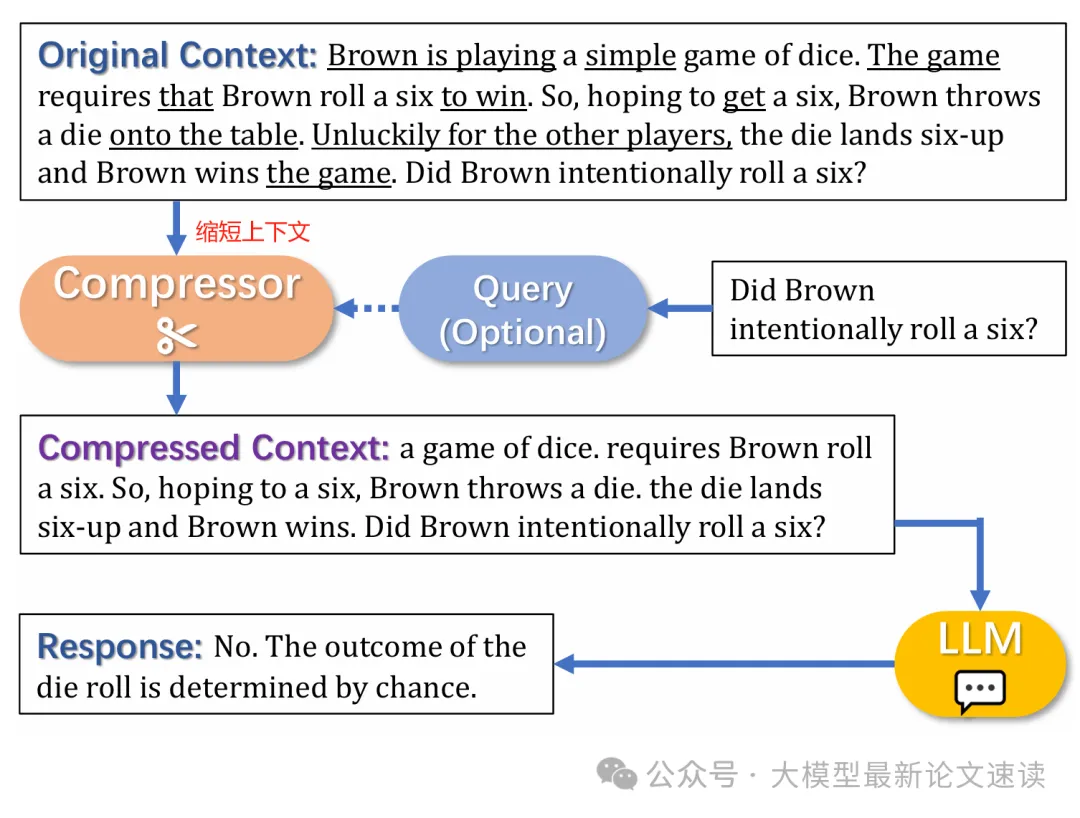
过往的研究主要关注压缩前后的下游任务指标(如摘要质量、问答正确率等),单没有对模型输出稳定性、幻觉倾向、跨领域泛化等基础能力做深入探索,此外压缩技术应用到多模态大模型上的影响也尚未可知,于是作者对此展开了系统全面的研究,并将各种压缩算法集成到一个开源工具包中
面临挑战
- 信息保留难题:不充分的压缩达不到减负效果,而过度的压缩又可能遗漏关键信息,导致性能下降和幻觉率提升,因此需要探究如何在压缩比和信息完整性之间取得平衡
- 模型差异:不同LLM对压缩的耐受程度和输出变化各异,例如GPT-3.5-Turbo和GPT-4o-mini面对提示压缩时,输出长度会增加,而Claude-3-Haiku则会变得更短;此外不同尺寸的LLM面对压缩时的表现也存在较大差异
- 任务差异:很多压缩算法只适用于特定场景。例如新闻摘要算法很可能在数学问答场景下失效
- 多模态场景:当提示不只是纯文本,例如视觉问答中包含图像相关描述时,文本压缩如何影响结果尚不明确,删除一些信息量看似很低的功能词(如a、the)可能会导致性能明显下降
本文方法
本文主要关注不改变大模型内部结构的方法(仅修改提示词),系统分析了3类代表性的提示压缩算法
一、强化学习方法
将提示压缩视为一个序列决策问题,通过强化学习来优化压缩结果的质量,具体由KiS和SCRL两种代表性方法
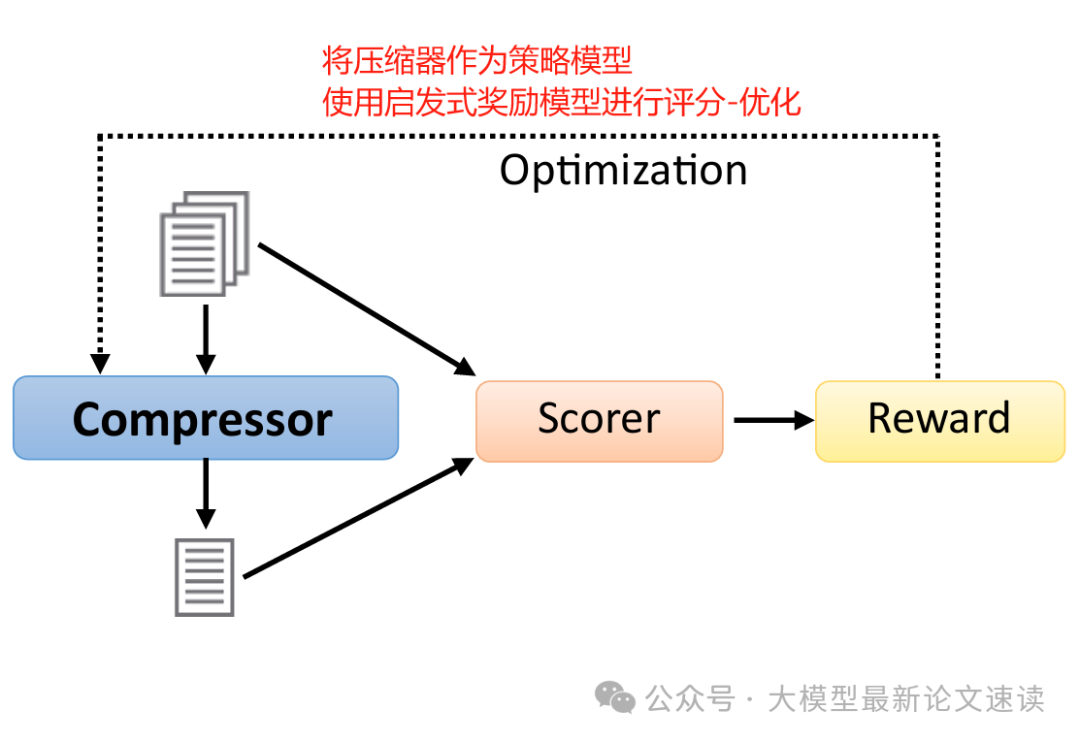
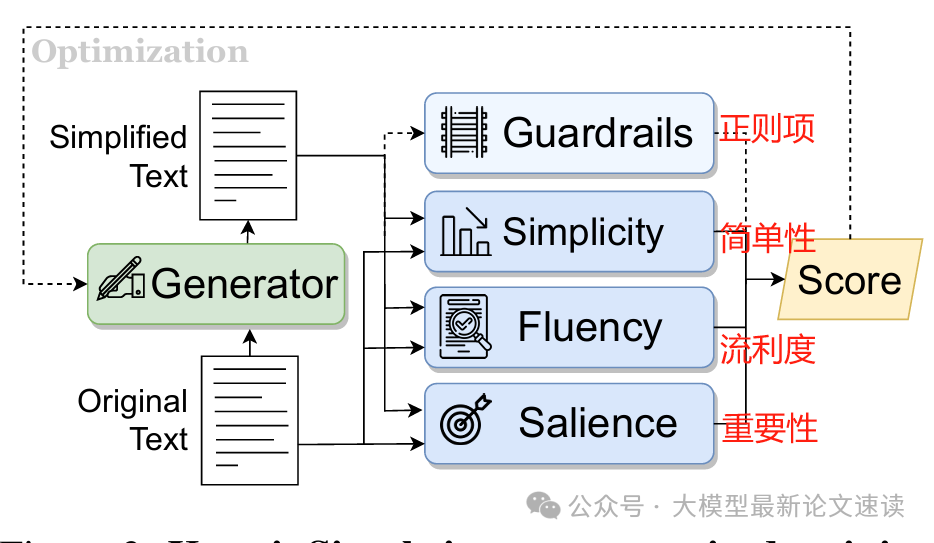
KiS(Keep it Short)是一种无监督压缩算法,使用自我批评训练(k-SCST)来优化Compressor:针对每个输入生成多个压缩候选,通过奖励函数评估每个候选的流畅性、显著性和简单性,然后促进优于平均奖励的候选。此方法的特色是不直接删词,而是重新生成一个更短的表述,因此能进行较大幅度的语句重构,但这也意味着开销较大;
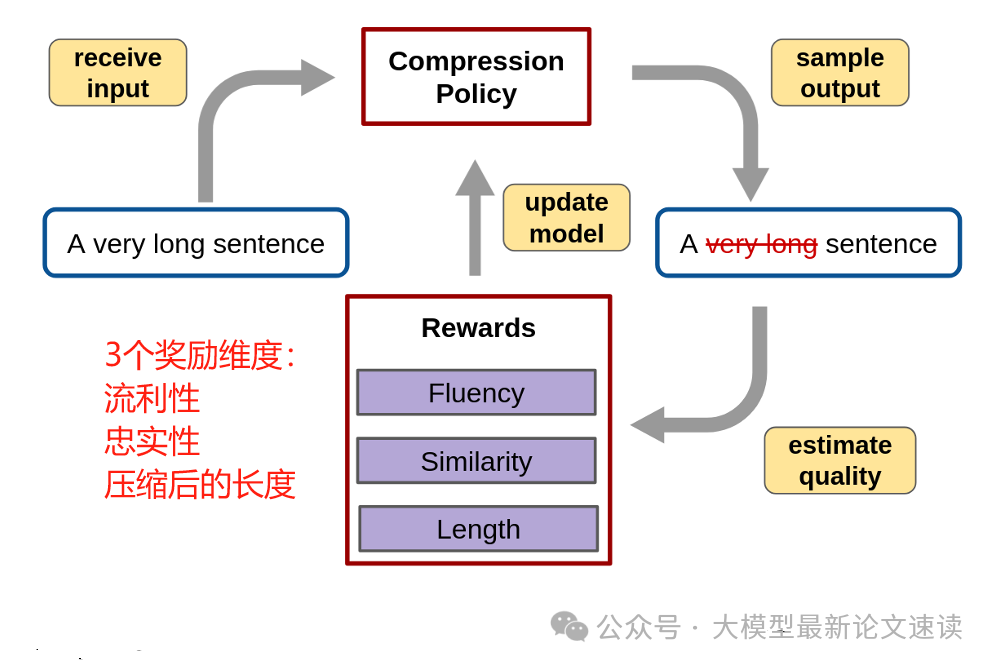
SCRL(Structured Compression with RL),将上下文压缩任务视作序列标注,训练一个Transformer模型来确认每个token是保留还是删除。SCRL的奖励函数鼓励在保持句子通顺和忠实原意的前提下,最大化压缩率。这种方法推理速度快,且易于控制压缩比例
二、LLM评分方法
利用现有语言模型对文本片段的重要性进行评估,然后根据评分结果裁剪提示词
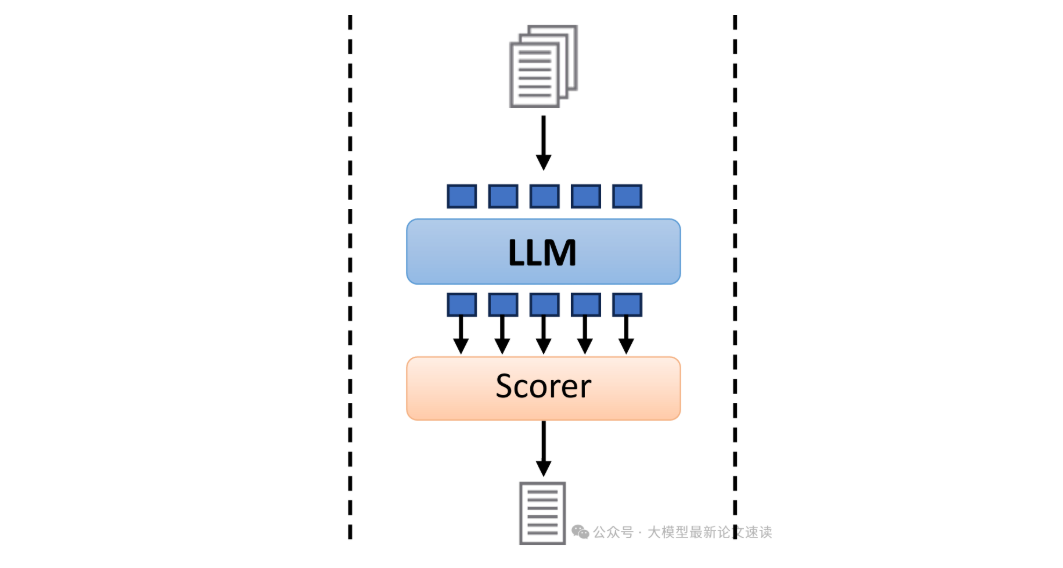
Selective Context方法通过计算原提示中各个片段的自信息来衡量其信息量(使用一个因果语言模型逐词计算负对数概率),信息量高意味着该词对上下文贡献大,信息量低则可能是冗余或可预测的。此方法本质上是一种启发式:让语言模型自己来评估哪些内容是可有可无的,优点是无需额外训练,计算简单;缺点是只考虑了单词的独立贡献,可能无法处理复杂的上下文依赖

三、LLM标注方法
利用一个强模型对大量数据进行自动标注或生成伪数据,然后训练一个较小的模型来专门执行压缩任务。代表方法有LLMLingua及其改进
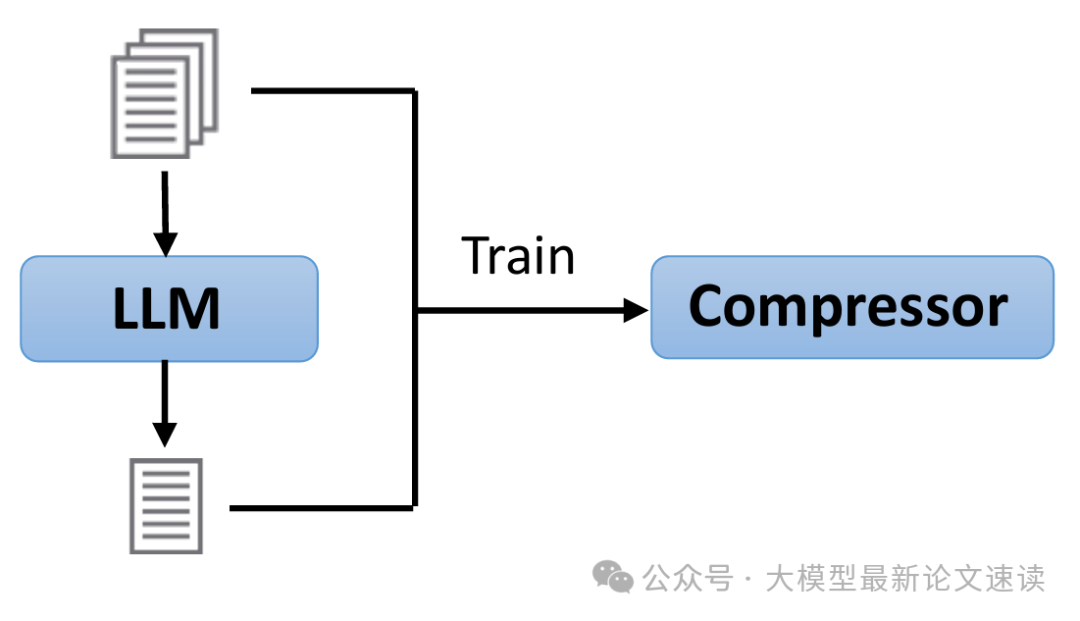
LLMLingua采用由粗到细的多阶段压缩流程来处理超长提示。首先,它设定一个压缩预算(如目标长度);接着,使用逐词迭代的压缩算法:反复检查当前文本中哪些片段可以删除或替换。在这个过程中,小模型会参考大模型提供的指引(例如删除某部分后的意义偏差)来微调决策
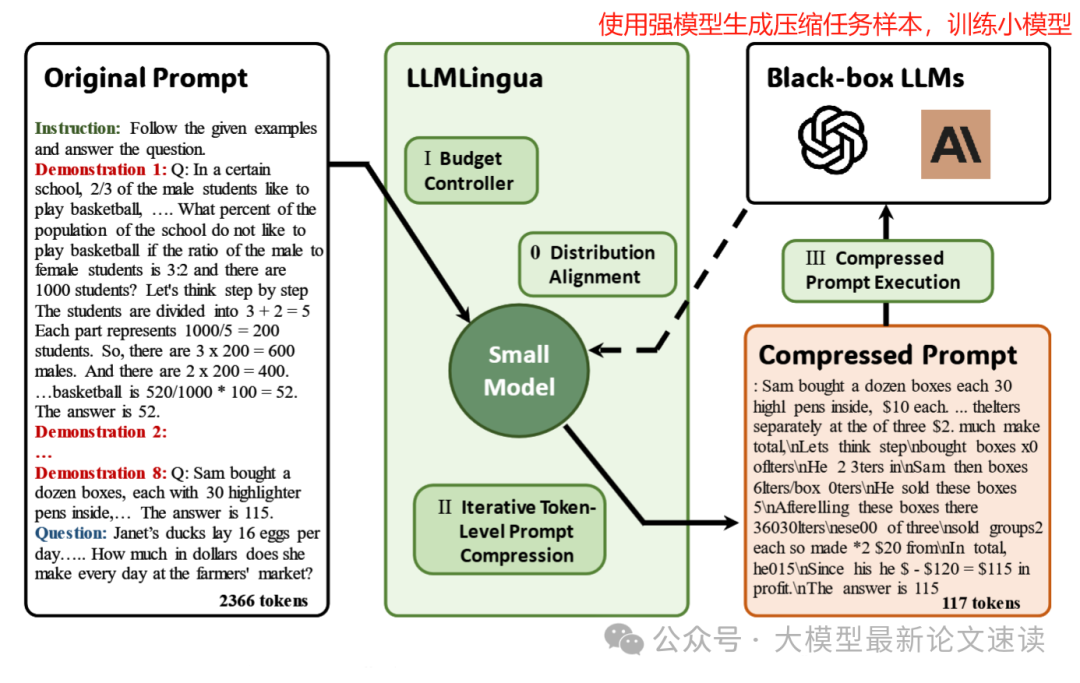
LongLLMLingua是针对长上下文场景的变体,包含以下改进:
- 重点针对问题相关的信息进行压缩
- 在压缩过程中会重排文档以减轻因位置靠后而被忽略的重要内容
- 根据上下文内容自动调整压缩比例
- 在压缩完成后做一次后处理校正,以确保输出的完整性
LLMLingua-2是LLMLingua的最新进展,着重提升方法的通用性和效率。它尝试做到任务无关的压缩:不像以往模型需要针对每种任务(摘要、QA等)单独训练,LLMLingua-2希望“一种模型压缩所有提示”。为此,作者采用了数据蒸馏的策略:利用GPT-4这类强大的教师模型,针对各种领域和任务自动生成大规模的压缩示例对(原文–压缩版),构建一个通用的压缩数据集。然后训练一个基于Transformer编码器的模型,将压缩视为序列标注问题:判断每个token是否应保留。LLMLingua-2在架构上去除了对单向生成的依赖,使压缩决策更精准
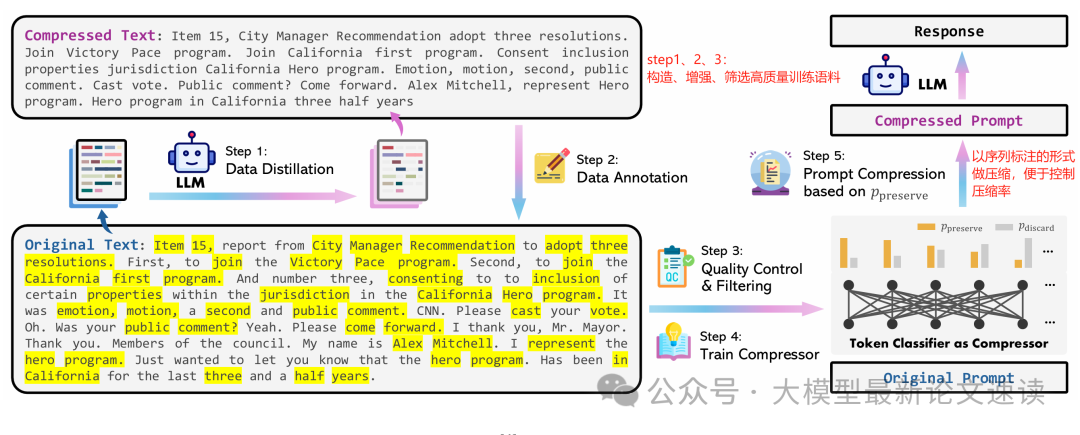
此外,作者还使用随机词选择作为基线方法,即从原提示中随机抽取一定比例的单词拼成压缩提示。于是这些方法便覆盖了从完全无监督(随机、RL)、基于预训练模型的启发式方法(Selective)、到有监督训练(LLMLingua)的不同范式,为全面评估提示压缩提供了多元手段
实验结果
作者在13个数据集上对上述方法进行了广泛实验,包括新闻摘要、科学文献、常识问答、数学问答、长文阅读理解问答,以及视觉问答(VQA)等,评估指标涵盖生成质量、回答准确性、相似度分数,以及幻觉率等。每项实验都是基于GPT3.5-turbo,GPT-4o-mini和Claude-3-Haiku三种模型实现,然后计算平均分数
一、不同方法在各类任务上的表现
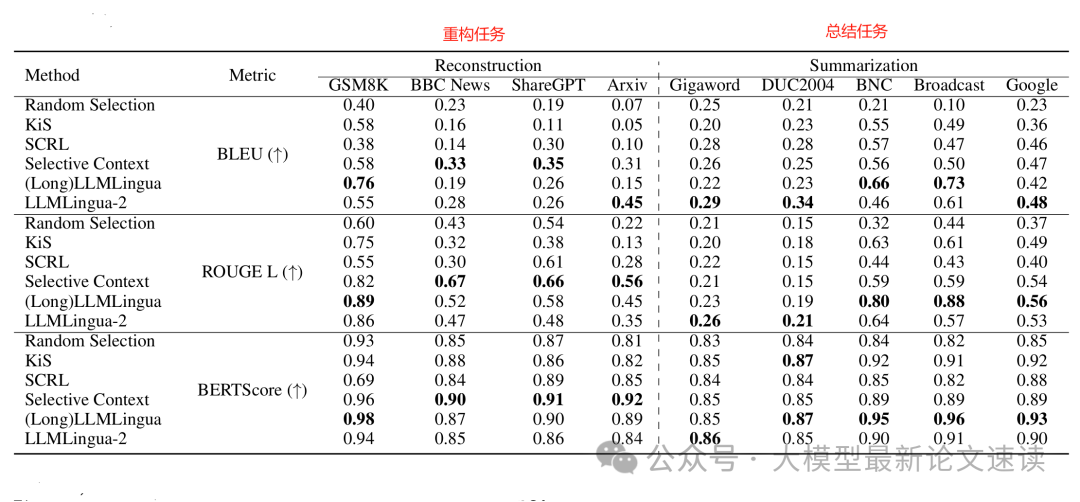
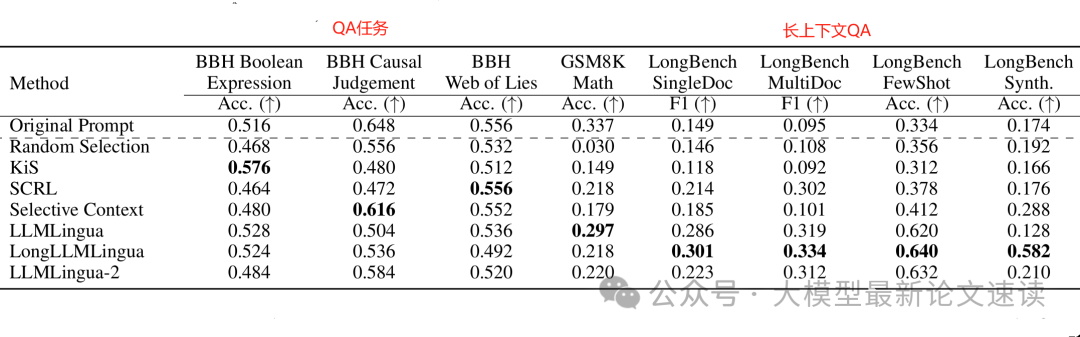
在摘要和重构任务中,LLMLingua系列方法表现最为突出,在高压缩比例下依然保持了领先的生成质量,证明了深度压缩模型在保持语义方面的效果。在一些细分类别上,不同方法各有优势:例如Selective Context在重构原文任务上表现最佳,说明其均匀删除冗余信息的策略有利于完整信息的恢复;而LongLLMLingua在长篇问答任务中效果突出,展示了其应对长上下文的强大能力。相比之下,两种RL方法在长文场景中略显不足
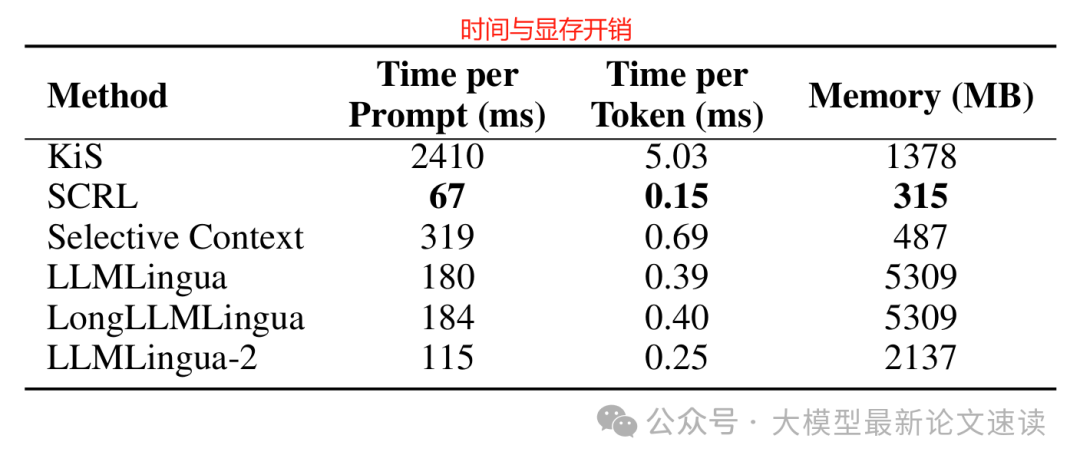
SCRL每个Prompt仅耗时0.15毫秒/token,远低于其他方法,且内存开销也最小。由此可见,如果在资源有限或要求实时的场景,SCRL这类轻量级方法是实际的优选
二、压缩率对性能的影响
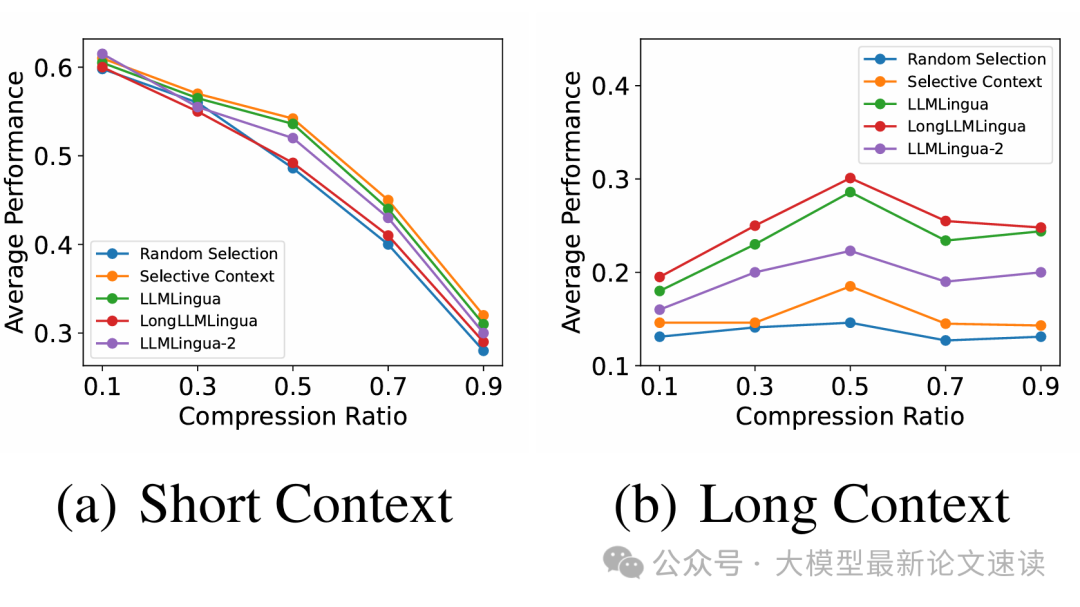
如上图所示,在相对简短的上下文任务中(如常识问答、短篇阅读理解),所有压缩方法随着压缩率提高,性能近乎线性下降——因为提示越短,能提供的信息越少,模型越难完成原任务。这种情况下不存在“适度压缩有益”的现象,说明对于信息量不大的提示,压缩只会损失有效信息而几乎无益;
而在长上下文任务(如LongBench长文阅读问答)中,作者发现一个拐点:适度的压缩反而能提升模型表现,这意味着适度删减冗余细节,有助于LLM提炼出文章主旨,避免信息过载。在实践中,这提示我们可以调节压缩力度来优化性能:短文本尽量不压,长文本适当压缩冗余背景
注:KiS 和SCRL无法调整压缩率,此实验未考虑
三、压缩是否引入副作用
所有压缩方法都会不同程度地增加幻觉,尤其是在需要精确信息的重构和问答任务中。一旦压缩导致模型缺少必要细节,模型往往通过猜测来填补,从而引入错误信息
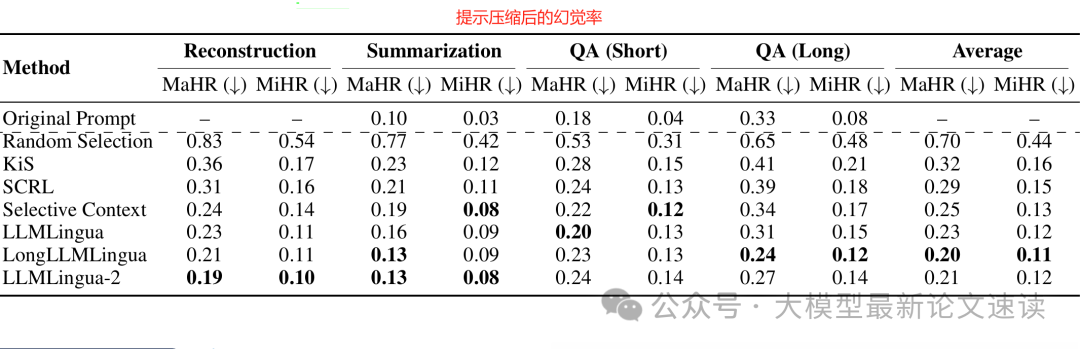
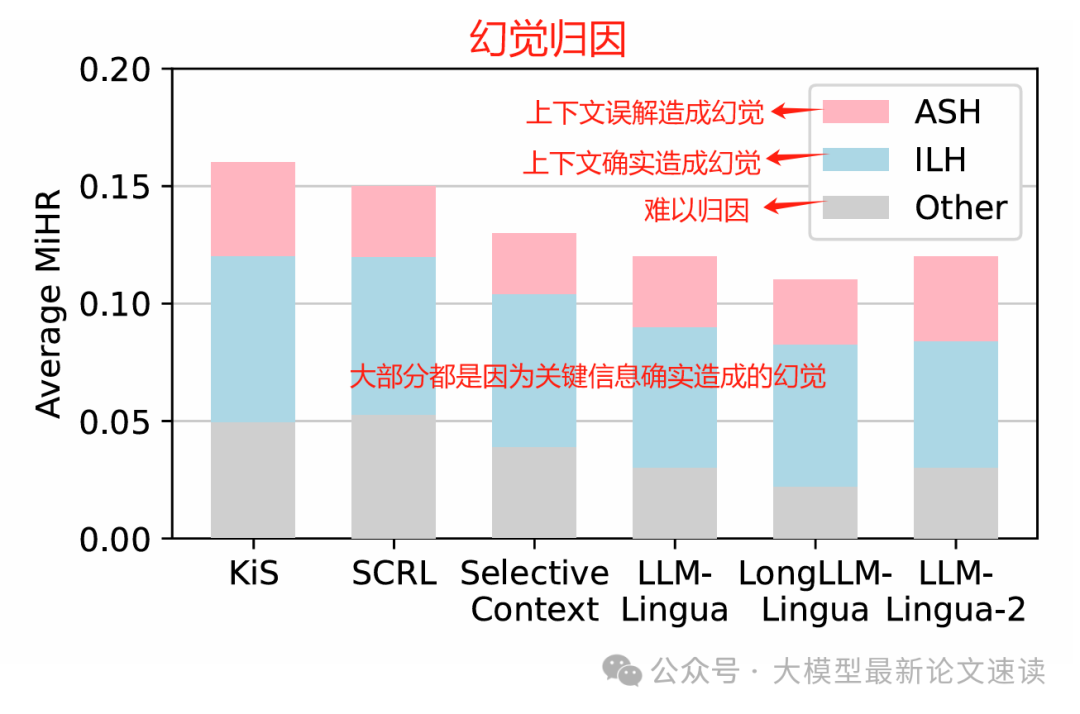
不过不同方法诱发幻觉的程度存在差异,LLMLingua-2在摘要和重构场景下幻觉率最低,LongLLMLingua在长文问答中幻觉率最低。这表明,通过更智能的压缩(如任务无关训练、考虑长文偏差),可以一定程度缓解幻觉问题,但无法完全杜绝。所以我们在实际应用时,如果采用提示压缩,需要辅以事实校验或限定模型不要编造成分
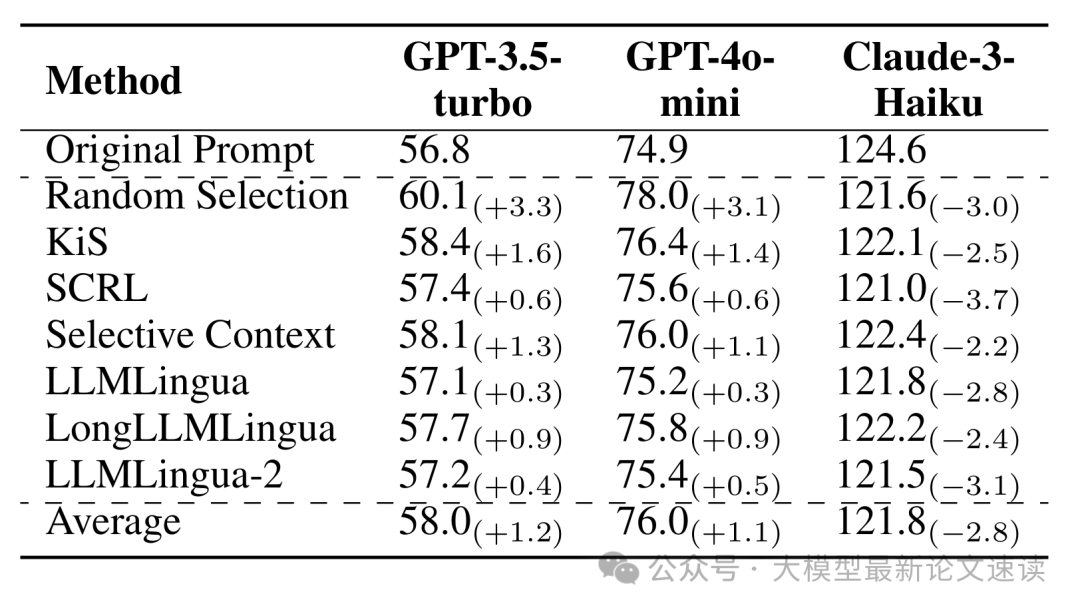
此外,提示压缩会影响LLM生成回答的长度,而且这种影响随模型而异。对于OpenAI系模型(GPT-3.5、GPT-4模拟版本),压缩后的提示往往让它们给出更长更详细的回答,推测原因是模型试图弥补压缩导致的信息损失,主动添加额外解释或背景;相反,Claude模型压缩后的回答更加简洁,可能Claude原本倾向啰嗦,当提示精简后它也相应缩短了回答。所以我们在使用提示压缩时,可以将对响应长度的要求添加到提示中
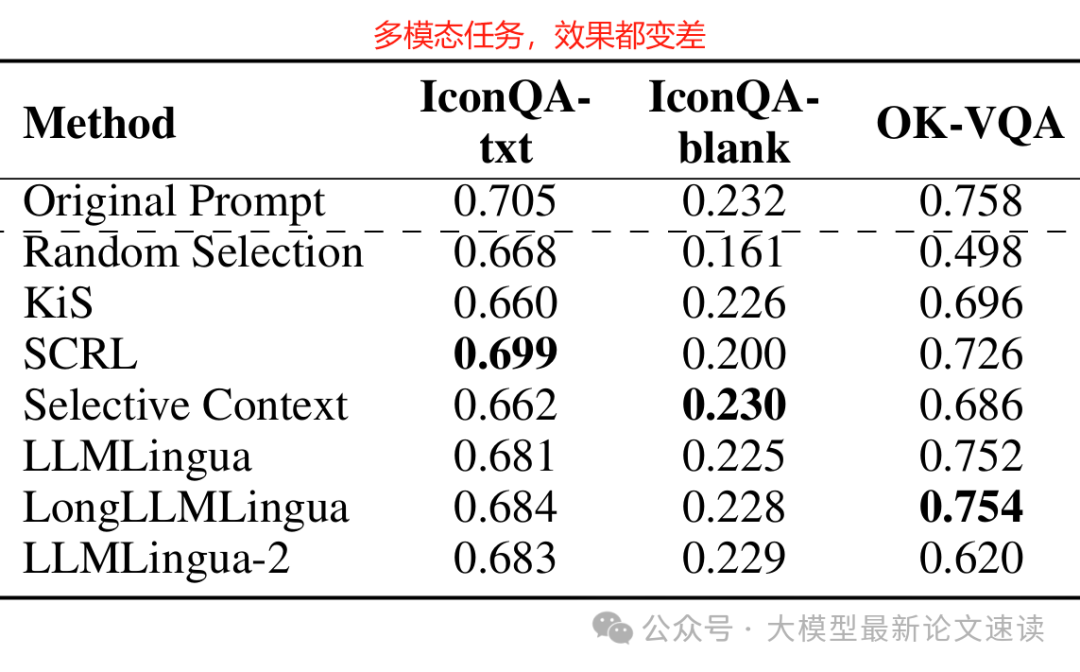
四、多模态任务效果
测试任务是看图回答问题(IconQA和OK-VQA数据集),结果显示,提示压缩在多模态任务上的效果不尽理想。例如在OK-VQA上,几乎所有方法的准确率都显著下降,这说明多模态任务的信息密度较高,目前的压缩策略难以判断哪些文字说明是可有可无的,未来需要针对多模态场景定制压缩办法,或者结合视觉特征来辅助决定文本哪些部分该保留
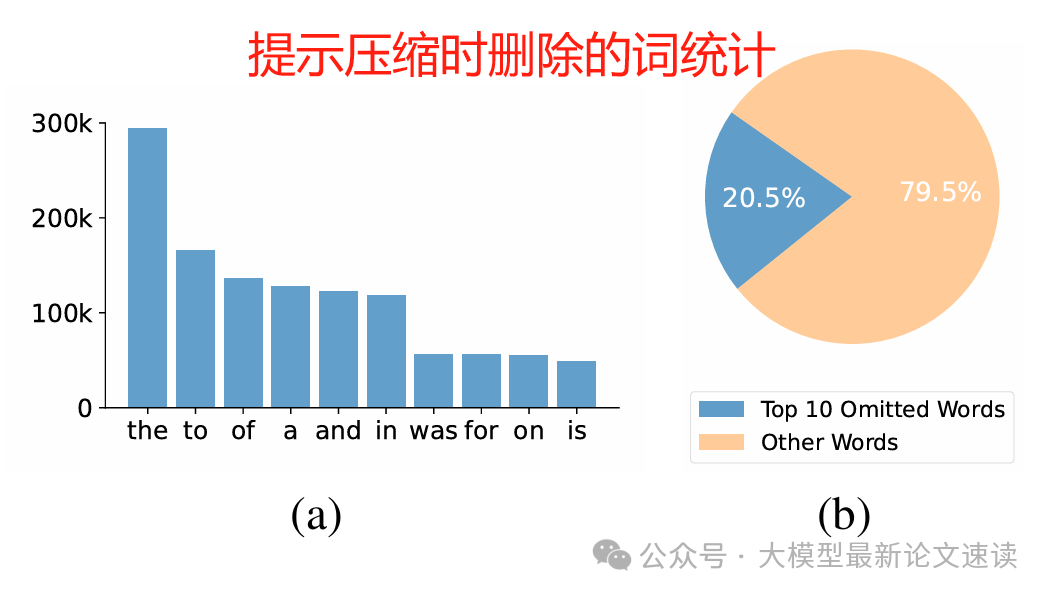
五、压缩算法倾向去除哪些词
无论哪种算法,被删单词大多是英语中的功能词(the, to, of, a, and等)。统计显示排名前10的高频被删词占所有删除词的约20%,其余80%是各种低频词。换言之,各算法经常会首先砍掉冠词、介词这些对语义影响不大的词
作者还考察了单独删除这些功能词,长短上下文任务的影响差异:
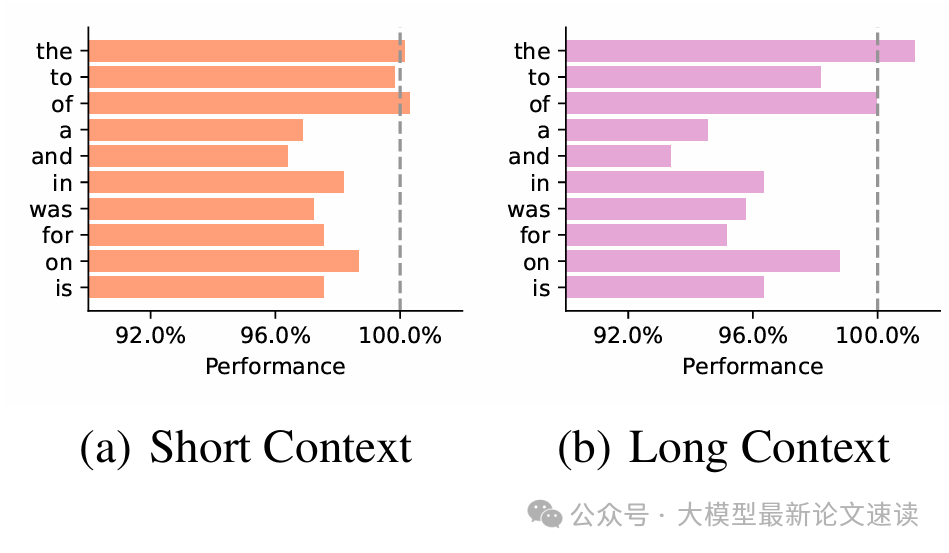
结果表明,如果删除了某些看似信息量很低的功能词(如a、the等),模型性能会明显下降,并且在长文本场景下这一影响更加显著
作者类比视觉Transformer的发现来解释这一点:Transformer会在背景等不重要区域产生高激活的token,作为模型计算的“寄存器”。类似地,LLM也许利用了一些不太重要的词(如冠词)来存储和传递中间推理信息,因此盲目删除它们反而破坏了模型的推理链条。这一推测为设计压缩算法提供了新视角:并非频率低或语义弱的词就可随意丢弃,我们需要考虑模型潜在的机制


》逐章精华笔记第五章)
)


