摘要:最近在大型推理模型(LRMs)方面的进展表明,通过简单的基于规则的奖励进行强化学习(RL),可以涌现出复杂的行为,例如多步推理和自我反思。然而,现有的零强化学习(zero-RL)方法本质上是“在策略”的,仅限于学习模型自身的输出,无法获得超出其初始能力的推理能力。我们引入了LUFFY(Learning to reason Under oFF-policY guidance,即在离策略指导下学习推理)框架,该框架通过增加离策略推理轨迹来增强零强化学习。LUFFY通过在训练过程中结合离策略演示和在策略展开,动态平衡模仿和探索。值得注意的是,我们提出了通过正则化重要性采样进行策略塑形,以避免在混合策略训练中进行表面化和僵化的模仿。令人印象深刻的是,LUFFY在六个数学基准测试中平均提升了超过7.0分,并且在分布外任务中获得了超过6.2分的优势。它还在泛化能力方面显著超过了基于模仿的监督微调(SFT)。分析表明,LUFFY不仅能够有效地进行模仿,还能在演示之外进行探索,为使用离策略指导训练可泛化的推理模型提供了一条可扩展的路径。
本文目录
一、背景动机
二、核心贡献
三、实现方法
四、实验结果
一、背景动机
论文题目:Learning to Reason under Off-Policy Guidance
论文地址:https://arxiv.org/pdf/2504.14945
大模型通过强化学习展现出了复杂的推理能力,例如多步推理和自我反思。然而,现有的零强化学习(zero-RL)方法本质上是“在线策略”的,这意味着它们只能基于模型自身的输出进行学习,无法超越模型的初始能力。
在线策略学习虽然稳定,但样本效率较低,且容易陷入局部最优。离线策略学习则可以利用其他策略生成的经验进行学习,从而扩展模型的学习能力。
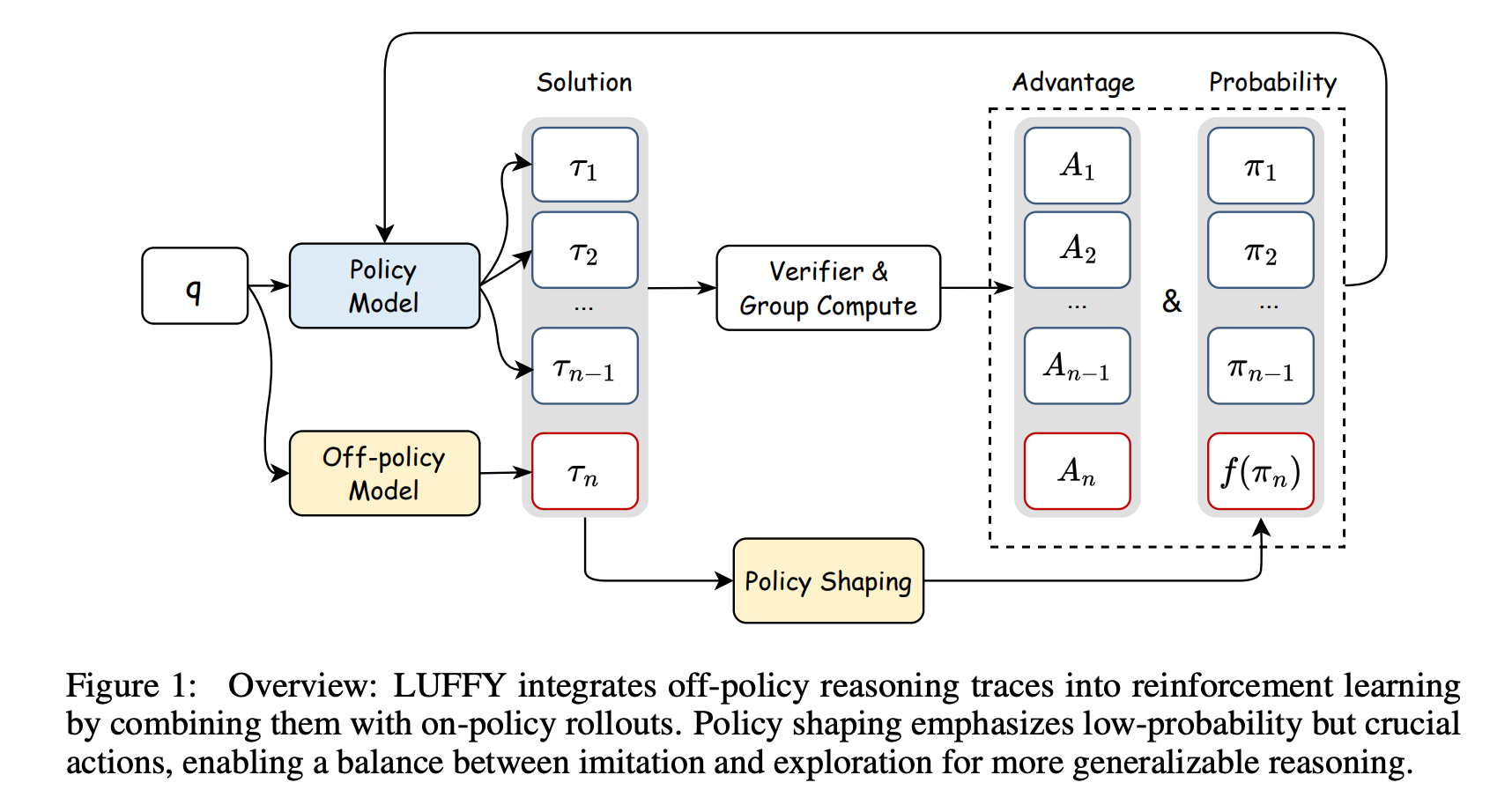
本文章提出了 LUFFY 的框架,旨在通过结合离线策略(off-policy)推理轨迹和在线策略(on-policy)rollouts 来增强强化学习(RL)在推理任务中的表现。LUFFY 证明了离策略指导在提升模型高阶推理能力上的巨大潜力:模型可以突破自身的先天局限,吸收更强者的经验而又不失自我进化的空间。
二、核心贡献
1、提出了LUFFY框架,通过结合离线策略推理轨迹和在线策略推理轨迹,动态平衡模仿学习(SFT)和强化学习(RL )。
2、引入了通过正则化重要性采样进行策略塑形(policy shaping),以避免在混合策略训练中出现的表面化和僵化模仿问题。
三、实现方法
1、混合策略 GRPO:为了引入离线策略数据,文章将离线策略 rollouts 和 在线策略 rollouts 相结合,形成一种混合的训练策略(Mixed-Policy)。即在每一轮更新中,模型的自身 rollout 生成的轨迹与来自更强模型的 off-policy 轨迹一起用于计算强化学习中的优势函数(advantage)。
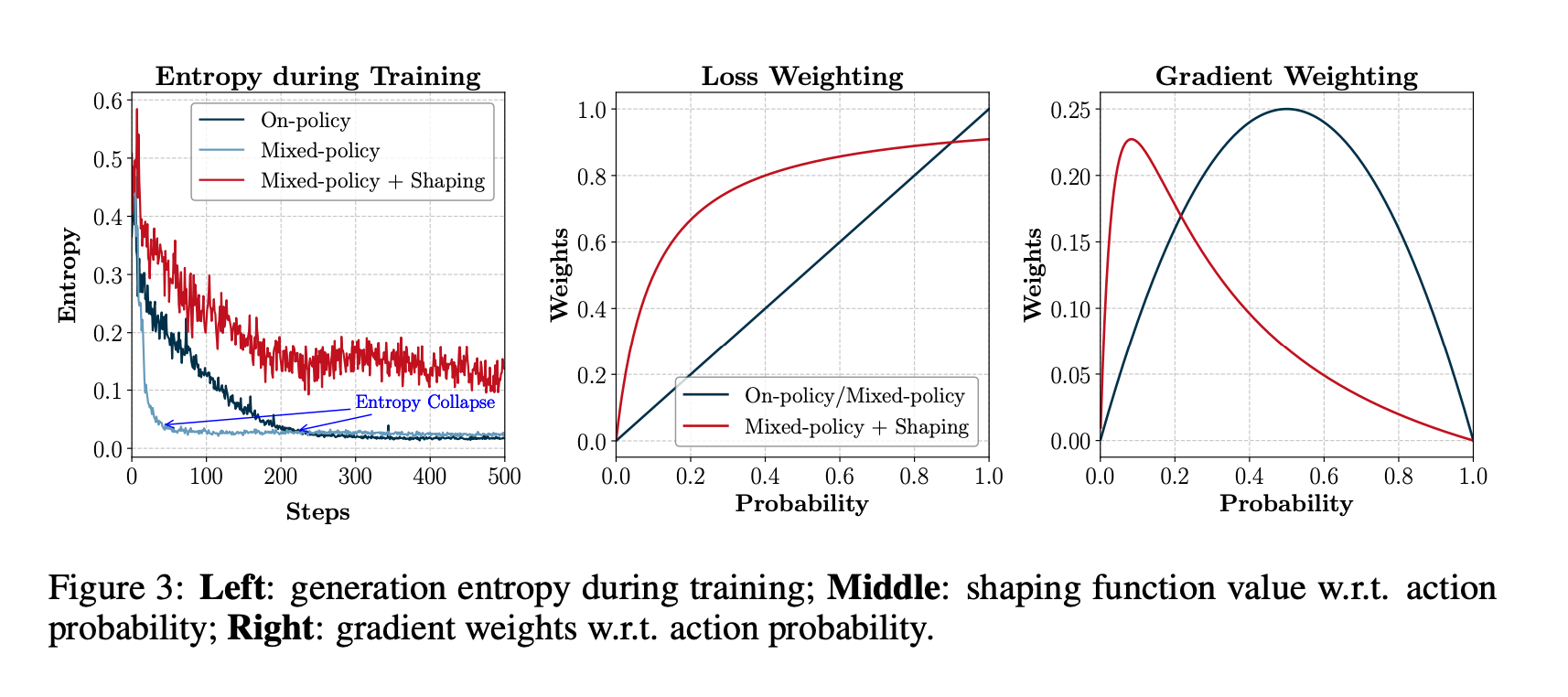
2、策略塑形:混合策略 GRPO 虽然能够利用离线策略数据,但会导致模型过早收敛,降低探索能力。为了解决这一问题,文章引入了策略塑形,通过正则化重要性采样来增强对低概率但关键动作的学习信号。即放大那些对成功至关重要但在模型当前策略下出现概率很低的行动的学习信号。
3、移除在线策略剪辑:在 PPO 中,剪辑机制用于限制策略更新的范围,以确保训练的稳定性。然而,当引入离线策略数据时,目标行为可能与当前策略有较大偏差,剪辑机制可能会抑制对高质量离线策略数据的学习。因此,文章移除了在线策略的剪辑机制,以允许模型更灵活地更新到不熟悉的但有效的动作。
四、实验结果
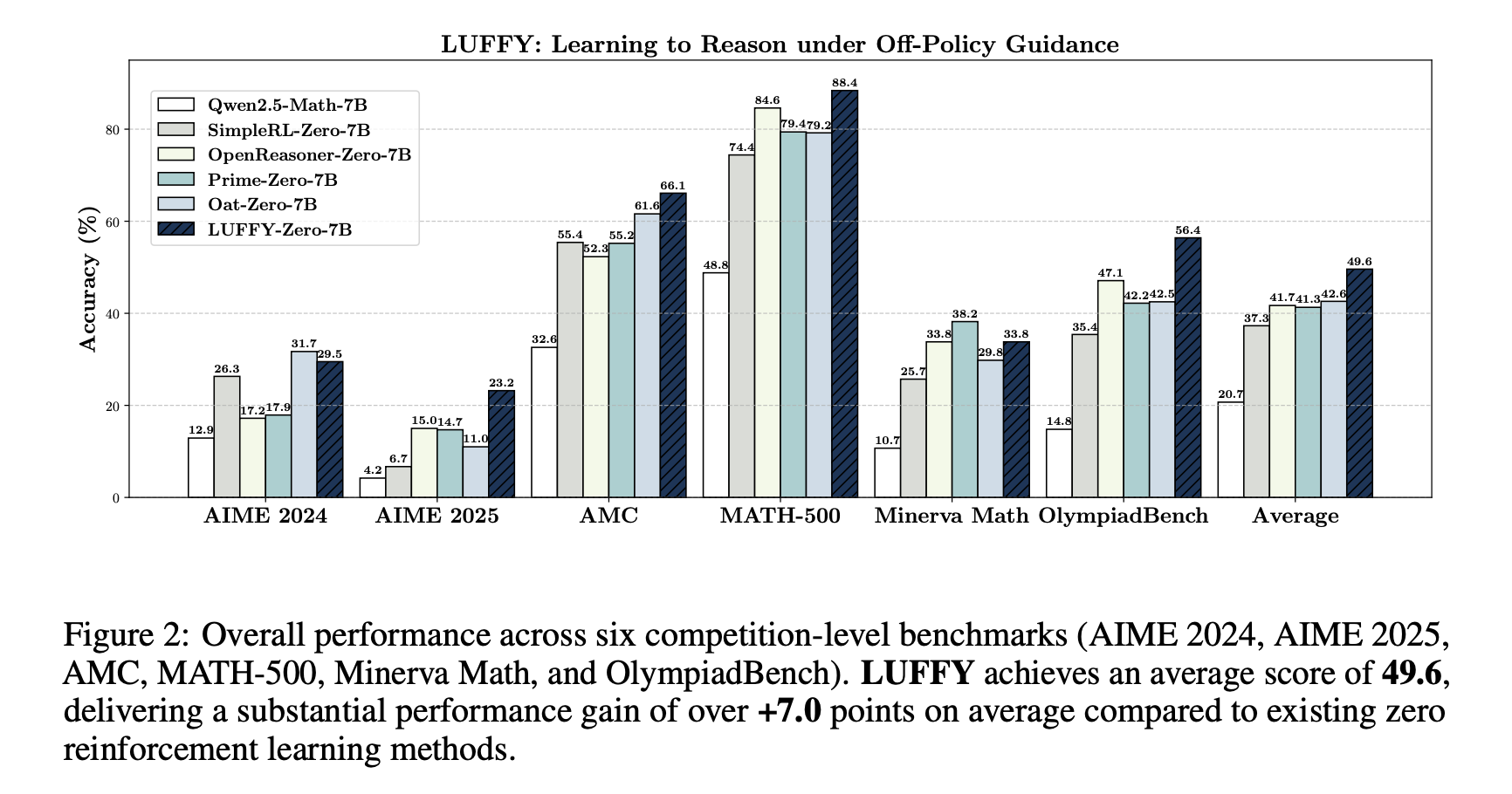
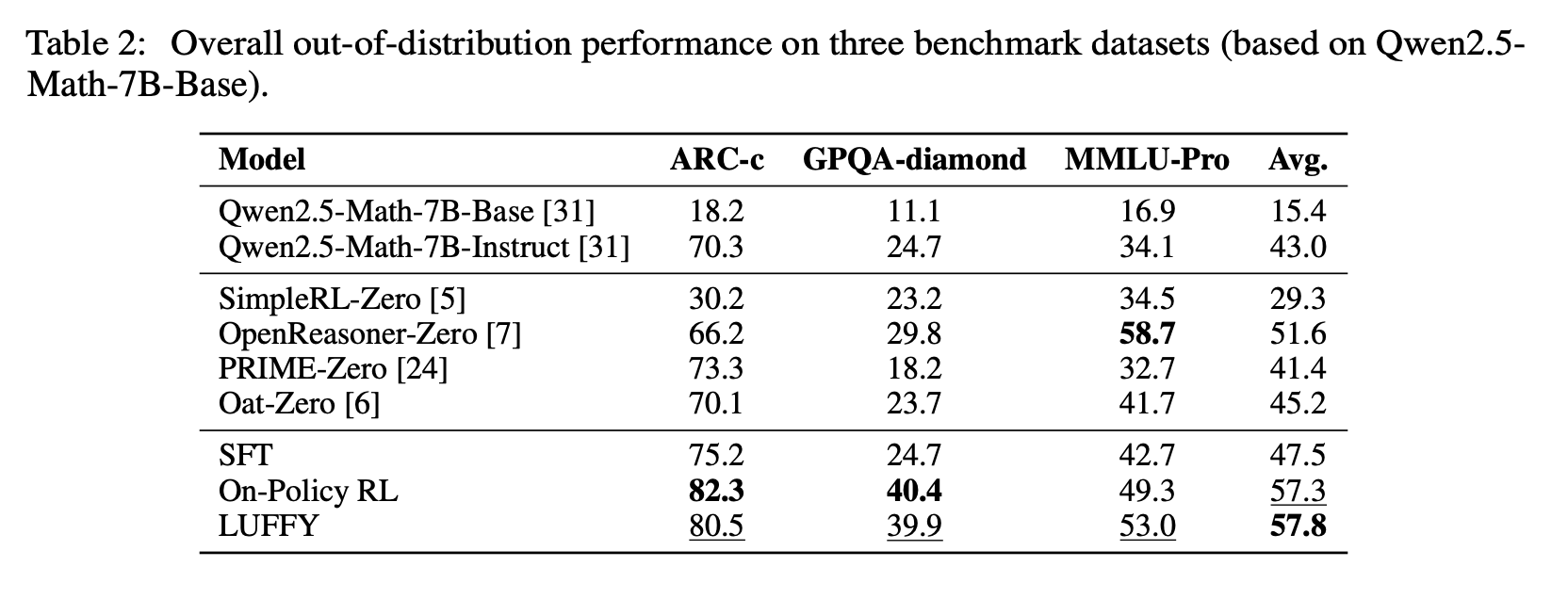
1、LUFFY在六个数学基准测试(AIME 2024, AIME 2025, AMC, MATH-500, Minerva Math, OlympiadBench)中平均得分为49.6,相比现有的零强化学习方法平均提升了7.0分。
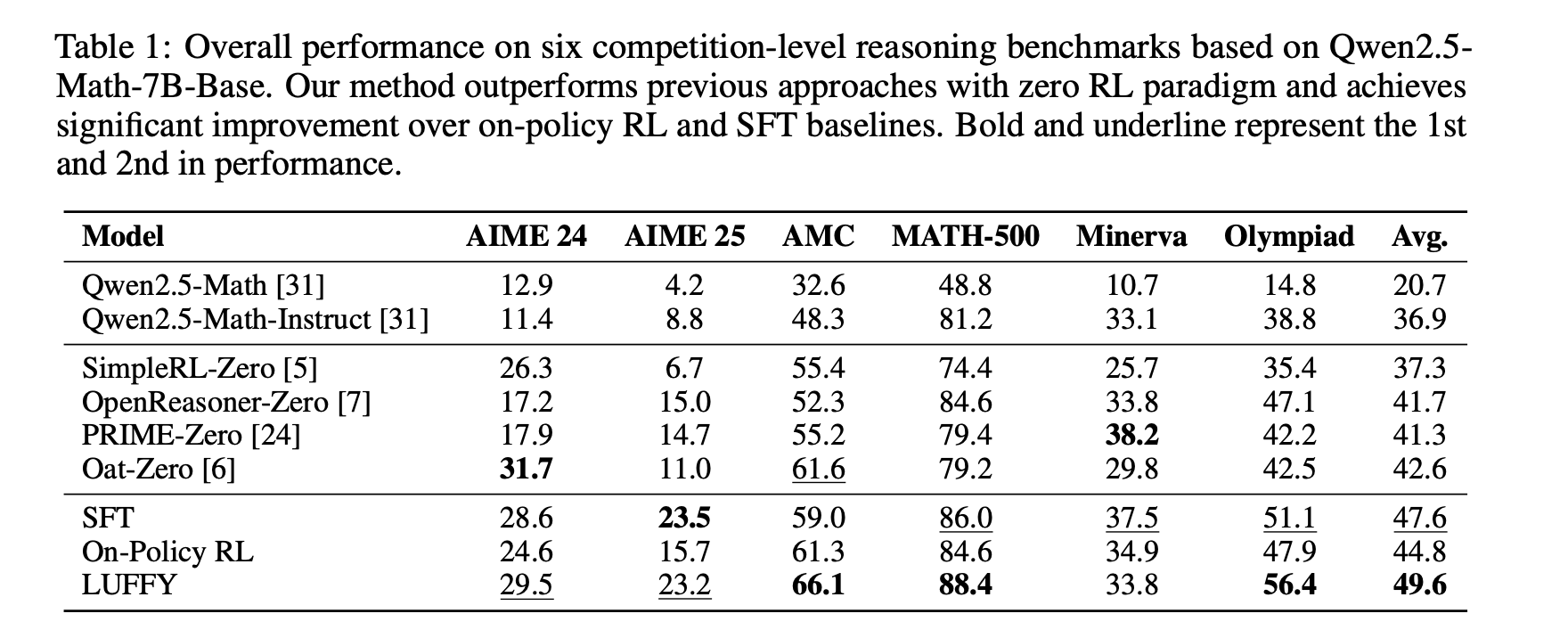
2、在三个分布外基准测试(ARC-c, GPQA-diamond, MMLU-Pro)中,LUFFY平均得分为57.8,相比在线策略RL和SFT有显著提升。
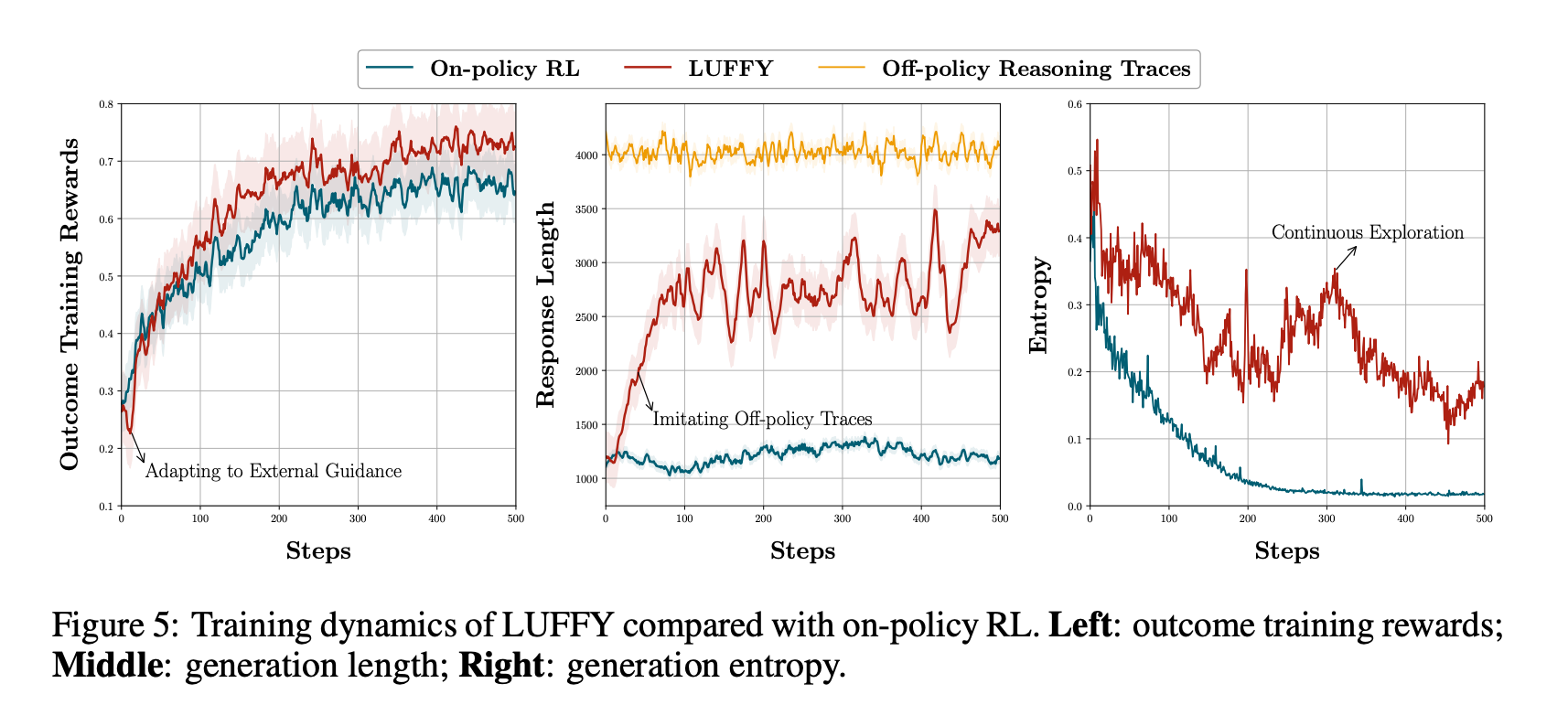
3、LUFFY在训练初期主要模仿离线策略轨迹,随着训练的进行,逐渐增加在线策略rollouts的比重,实现了模仿和探索的动态平衡。在整个训练过程中,LUFFY的生成熵始终高于在线策略强化学习,这使得模型能够持续探索不那么确定但可能更优的策略,从而发现和学习新的认知行为
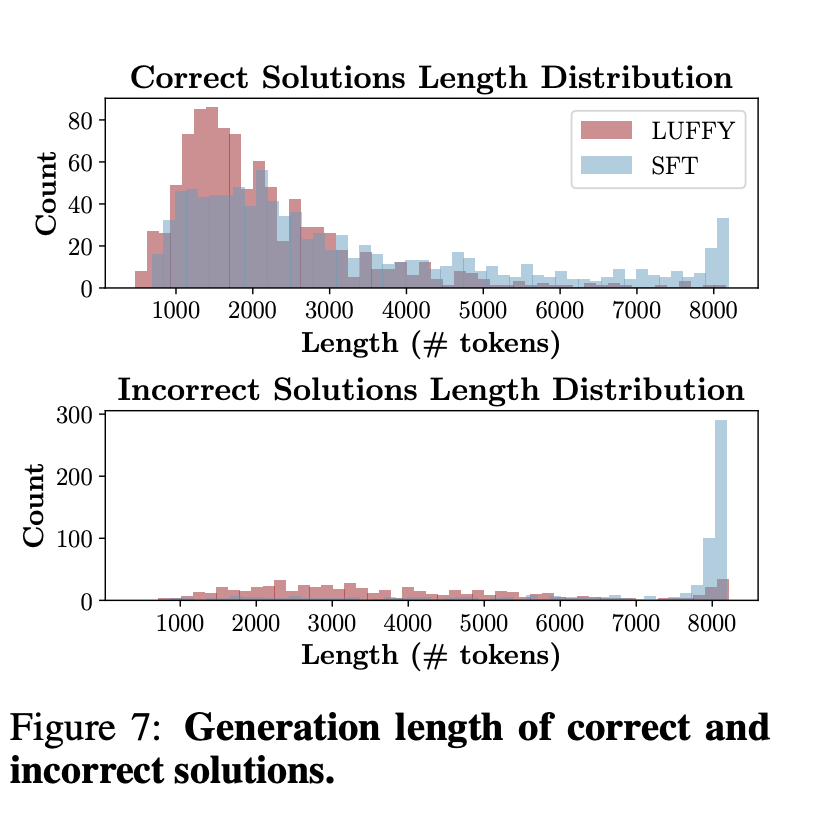
4、对比SFT和LUFFY的回复长度,LUFFY 在生成正确解时的平均推理长度明显短于 SFT,展现出更高效的推理路径。尤其在错误解的分布中,SFT 倾向于陷入冗长、低效的表面推理过程,生成大量无效信息;而 LUFFY 则更倾向于早停错误尝试,避免无意义展开,体现了其更强的推理控制能力和路径优化能力。