卷积神经网络
CNN:为处理网格状结构数据(图像、音频)而设计的深度学习模型。多层感知机的变种。采用的局部连接和权值共享方式:一方面减少权值数量使网络易于优化,另一方面降低了模型复杂度,减少过拟合风险。
全连接神经网络处理大尺寸图像问题:图像展开为向量会丢失空间信息。参数过多效率低,训练困难。大量参数导致网络过拟合。
卷积神经网络中神经元是3维排列的:宽度(图像宽度)、高度(图像高度)、深度(图像通道数)。中间层是特征图宽和高(卷积和池化决定),深度是特征图通道数(卷积核个数决定)。
组成
- 卷积层:CNN核心部分,用于提取输入数据的局部特征。
卷积运算:通过小滤波器(卷积核)在输入数据上滑动,计算卷积核与输入数据的局部运算生成特征图。是一个降维的过程。
作用:捕捉输入数据空间层次结构,提取边缘纹理等低级特征,组合成高级特征
参数:大小、步长、填充。
- 图像:7x7x3(R、G、B三通道) 卷积核:权重参数(3x3x3)
- 卷积核内数值:float、一开始是随机的、不断更新、形成更好的参数
- stride:窗口移动步长。pad:填充边界,让边界也有参与且防止内层多计算了几遍的问题
- 卷积结果计算:输出长度 H 2 = H 1 − F H + 2 P S + 1 H_2=\frac{H_1-F_H+2P}{S}+1 H2=SH1−FH+2P+1,输出宽度 W 2 = W 1 − F W + 2 P S + 1 W_2=\frac{W_1-F_W+2P}{S}+1 W2=SW1−FW+2P+1 H1、W1:输入长度宽度,F卷积核长款,S滑动窗口步长,P边界填充几圈
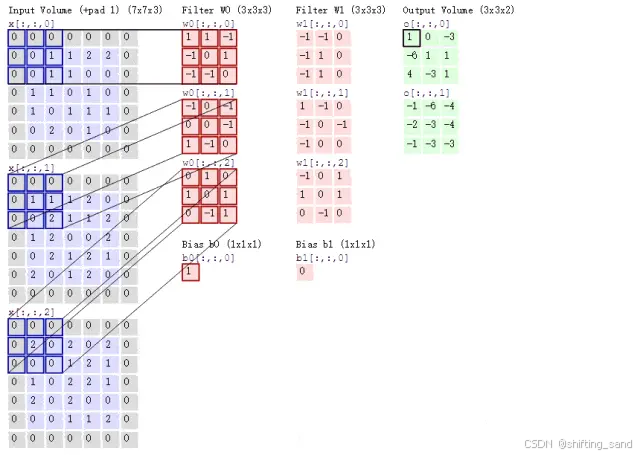
- 激活函数:卷积之后应用非线性函数,能学习复杂特征(ReLU、ELU等)
- 池化层:又叫下采样,降低特征图的空间维度,减少计算量,防止过拟合。
有几个卷积核就有几个特征图,特征图变多,特征也就多,有些特征不是需要的。
作用:降低维度,防止过拟合,增加鲁棒性
- 最大池化:取局部区域的最大值,形成一个新pool。
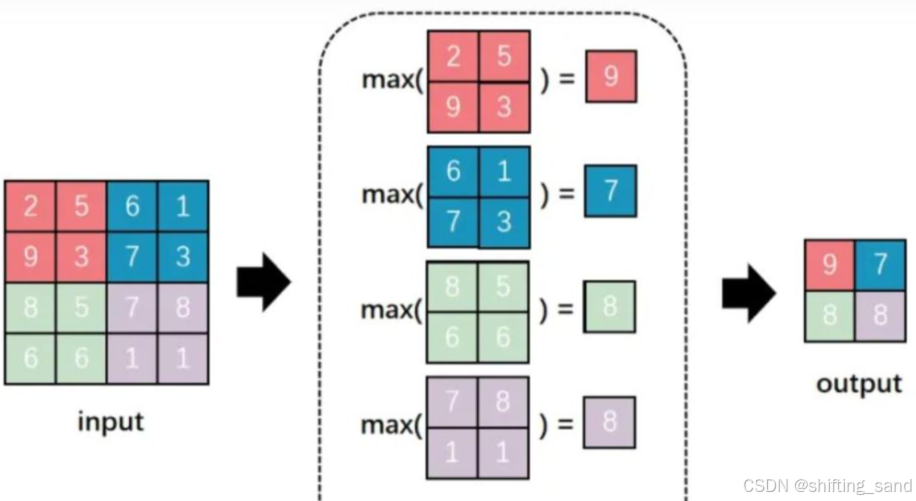
- 平均池化:取局部区域的平均值,向上取整。
池化层优点:减少参数数量保留原始特征。防止过拟合。为卷积神经带来平移不变性。
- 全连接层:将卷积和池化层提取的特征组合,用于最终分类或回归任务
将所有特征展开并运算,得到一个概率值。
作用:将高维特征映射到低维输出。逐渐被全局平均池化取代。
- 输出层:根据全连接层的信息得到概率最大结果。
其他概念
- 感受野:卷积核对应的前一层窗口的大小。感受野越大卷积神经网络层次越深。
由生物学家休博尔和维瑟尔在早期关于猫视觉皮层的研究发展而来,视觉皮层的细胞存在一个复杂的构造,这些细胞对视觉输入空间的子区域非常敏感,称之为感受野。
感受野指卷积神经网络每一层输出的特征图上像素点映射回输入图像上的区域大小。感受野越大表示接触到的原始图像范围越大,学习更全局。网络越深,神经元的感受野越大。
- 权值共享
可以有效减少所需求解的参数。一个卷积核在和n通道的特征图进行卷积运算时,这个特征图每个位置被同样卷积核扫描,权重是一样的,也就是共享。卷积核上的数字就是参数。
- 上采样
输入图像通过卷积神经网络提取特征后,输出的尺寸会变小,将尺寸恢复到原来的过程就是上采样。三种方法:
- 插值:双线性插值。
- 转置卷积:又叫反卷积,对输入特征间隔填充0,在竞选标准卷积计算。
- max unpooling:记录最大值的索引位置,在unpooling阶段恢复最大值,其余位置补0
- 归一化层:加速训练提高模型稳定(批归一化、层归一化)
- 损失函数:衡量预测与真实的差异。交叉熵损失(分类任务)、均方误差(回归任务)
- 优化器:更新模型参数减小损失函数:SGD、Adam、RMSProp
- CNN典型结构:多个卷积层、池化层、全连接层交替组成
输入层->卷积层->激活函数->池化层->卷积层->激活函数->池化层->全连接层->输出层
激活函数和池化层没有权重参数。带权重参数的才是一层,然后再加一。
- 为什么使用3x3卷积核
所需参数少、抽取的特征多,网络非线性越强,英伟达优化的好
经典CNN介绍
- VGG(卷积核大,步长大,因为以前硬件配置低)
- Resnet(当卷积层训练到20层时,损失不再降低了,梯度消失了)
残差网络:每个附加层都应该更容易地包含原始函数作为其元素之一。在残差块中,输入可通过跨层数据线路更快地向前传播。


)


