先准备1台机器,配置好后再克隆2台,配置一样

# 修改ip (每个克隆机要执行)
vim /etc/sysconfig/network-scripts/ifcfg-ens33


# 域名解析
vim /etc/hosts
================================= 进入正题=======================
上传hadoop安装包 jdk安装包,这里安装jdk忽略不讲
# 域名解析
tar -zxvf /usr/local/hadoop-3.3.3.tar.gz分别修改配置文件
cd /usr/local/hadoop-3.3.3/etc/hadoop
=============core
<property><name>fs.defaultFS</name><value>hdfs://hadoop10:8020</value>
</property><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop-3.1.3/data</value>
</property>==============hdfs
<property><name>dfs.namenode.http-address</name><value>hadoop10:9870</value>
</property>
<property><name>dfs.namenode.secondary.https-address</name><value>hadoop12:9868</value>
</property>==============yarn<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>hadoop11</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,HADOOP_MAPRED_HOME</value></property>=============mapred
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
节点建立集群关系
cd /usr/local/hadoop-3.3.3/etc/hadoopvim workers# 输入hostname 不能有空格或者空行,也不要带“_”特殊符号 注意! 注意! 注意!hadoop10
hadoop11
hadoop12 
克隆剩下两台,安装第一台配置好ip ,检查机器之间的联同ping 一下
建议配置ssh免密登录,参考ssh免密登录-CSDN博客
# 存储初始化hdfs namenode -format
# 启动集群
sbin/start-dfs.sh 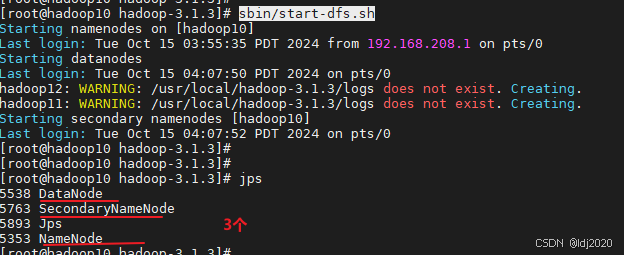
)

)



