
🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、前言
1、微调大模型的现实难题
2、LoRA 的高效微调优势
二、技术基础简介
1、什么是 LoRA?它如何节省参数与显存?
2、什么是 vLLM?相比 Transformers 推理快在哪?
3、支持 LoRA 的大模型有哪些?
4、常见的模型微调方式
三、微调实战
1、微调步骤
2、微调
3、测试
四、使用 vLLM 启动服务(支持 LoRA)
1、启动 API Server
2、使用带 LoRA 的模型进行推理
一、前言
1、微调大模型的现实难题
1️⃣ 训练成本高 💰💰💰
想让一个大模型掌握新知识,不是件容易事:
-
✅ 你需要成千上万条高质量数据📄
-
✅ 你要反复训练几十轮🔁
-
✅ 每一轮都在烧算力🔥
如果你用全参数微调(full fine-tuning),就相当于重塑整个模型的大脑——太!贵!了!
💬 比喻一下:就像你买了个机器人保姆,还要送它去国外培训班,机票+学费+住宿样样都贵!
2️⃣ 硬件资源要求高 🖥️🧊
大模型动不动就几十亿参数,训练它需要:
-
🚀 顶级显卡:A100、H100、3090 双卡起步
-
🧠 大内存:至少 40GB 显存,不然直接 OOM(炸了)
-
🧊 高散热、稳定供电、电费直飙!
🧾 很多普通开发者根本负担不起这么豪华的硬件环境。

3️⃣ 调优过程复杂 🧩🛠️
全量微调要处理:
-
模型结构理解
-
数据格式适配(prompt 格式、token 对齐)
-
超参调整(学习率、batch size、epoch)
-
checkpoint 管理
一个不小心就训练失败,或模型忘记了之前学的知识(遗忘问题)😢
4️⃣ 模型越大,越“难带” 🧱📦
你以为换个 13B 模型训练就能轻松搞定?
错 ❌:
-
参数越多,训练越慢
-
存储开销越大(几百 GB 模型体积)
-
上线部署也成难题(推理速度慢、内存爆炸)
💬 就像养了一头大象🐘,吃得多、占地方,还不好带出去工作……

2、LoRA 的高效微调优势
大模型动辄几十亿参数,
想微调一下就像给大象洗澡——又贵又累又慢🐘🛁
但自从有了 LoRA,微调也能变成 快、轻、准 的轻松体验!
🎯 只调 Adapter 层:目标明确,避免大修大动
LoRA 不去动模型里那些巨大的权重矩阵,而是:
🧩 在里面加两个小小的“低秩矩阵”👉 就是我们说的 Adapter 层!
比喻一下:
原始模型是一部豪华跑车🚗,LoRA 只是给你加了个贴心导航仪📡,而不是换发动机!
⚡ 快:训练时间更短!
-
传统微调:更新整个模型,动辄几天☁️
-
LoRA 微调:只更新少量参数,训练几小时就能出成果⏱️
✅ 适合快速上线新功能 / 快速迭代测试
🪶 轻:显存占用更少!
-
全量微调可能需要 80GB 显存以上🔥
-
LoRA 通常只需十几 GB,甚至可以在消费级显卡如 3090 上运行🎮
✅ 在本地也能“玩得起”的大模型微调!
🎯 准:效果也能打!
别看你调的参数少,但:
-
LoRA 插在注意力机制等核心结构中,能有效捕捉新知识🧠
-
多数 NLP 和对话任务中,LoRA 的效果能接近甚至媲美全量微调💥
✅ 高性价比、不妥协的效果,是不是很香?😋
📦 举个现实例子:
比如你想让大模型写古诗、说上海话、模仿你家猫咪说话😼:
-
你不需要训练整个大模型
-
只需针对这些任务分别微调 LoRA Adapter
-
一个模型挂多个 LoRA 插件,随时切换技能!
二、技术基础简介
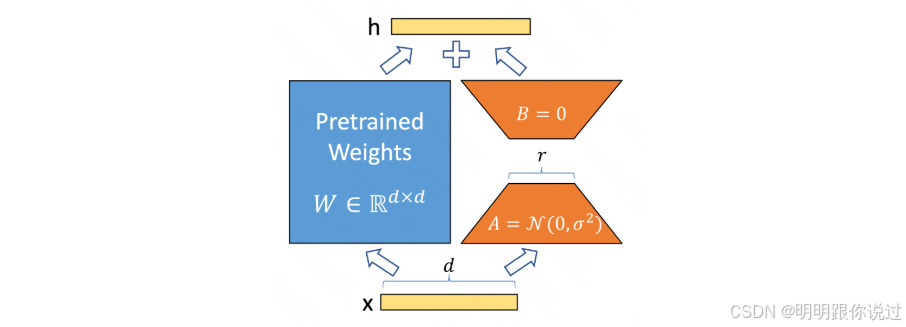
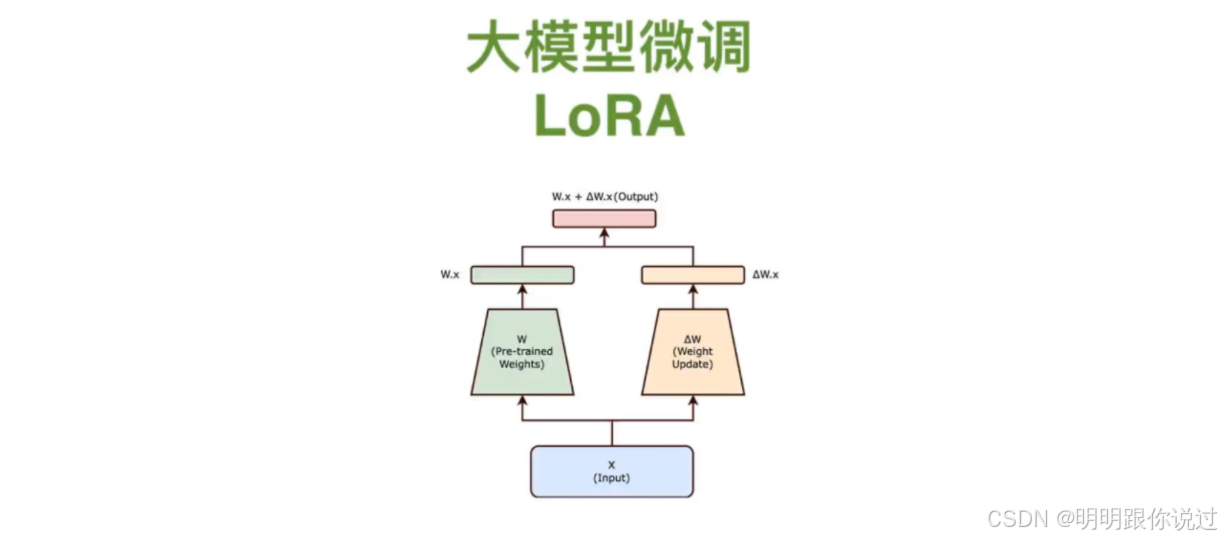
1、什么是 LoRA?它如何节省参数与显存?
LoRA(Low-Rank Adaptation)是一种只调整“大模型一小部分参数”的微调方法,让你用更少资源、更快速度**,获得接近全量微调的效果。
🧠 类比解释:全量微调 vs LoRA
传统微调:
就像装修整栋大楼🧱,每扇门、每面墙都改,工程大、费钱、时间久!
LoRA 微调:
只在关键房间里加装一些“智能小设备”🔌(低秩矩阵),快速升级核心功能,外观不动、能效暴涨!
🎯 LoRA 是怎么做的?
大语言模型中有大量的矩阵,比如注意力模块里的权重矩阵 WWW,维度可能是几千 × 几千,非常大。
LoRA 的关键做法:
将这些大矩阵的更新部分 分解成两个小矩阵 AAA 和 BBB:
W_new = W + ΔW
ΔW ≈ A × B
其中:
-
A∈Rd×r,B∈Rr×d
-
r很小,比如 4、8(远小于 d)
这样相比于直接更新整个 W,只需要训练参数量是:
r × d × 2 ≪ d × d
🎉 这就是节省的秘诀!
✅ LoRA 的三大节省点
| 节省项 | 原因说明 |
|---|---|
| 🧮 参数量 | 只训练两小矩阵 AA 和 BB,原始模型不动 |
| 💾 显存使用 | 不保存原始矩阵的梯度、优化器状态,大大减少显存 |
| 🕒 训练时间 | 参数少 → 梯度更新快 → 收敛也更快 |
📊 实测对比
| 项目 | 全量微调 | LoRA 微调 |
|---|---|---|
| 参数更新量 | 100% | <1%(约 0.1~1%) |
| 显存占用 | 高(A100 40G) | 低(3090/24G 也能跑) |
| 效果(准确率) | 100% | 95~99%(非常接近) |
| 训练时间 | 1~3 天 | 几小时~半天 |
📦 与其它技术兼容好
LoRA 支持搭配:
-
✅ 多种大模型(LLaMA、Qwen、Baichuan、ChatGLM 等)
-
✅ 量化技术(QLoRA = Quantized LoRA)进一步压缩显存
-
✅ LangChain / vLLM 等推理框架,实现插件式加载 LoRA 模型
🧠 小结
LoRA 是一种 既聪明又省资源 的微调策略:
✅ 只改关键小部分(Low-Rank)
✅ 保持大模型原始能力不变
✅ 训练快、显存省、效果好
2、什么是 vLLM?相比 Transformers 推理快在哪?
🧠 一句话解释:
vLLM 是一个专为大语言模型打造的高性能推理引擎,相比 HuggingFace Transformers,它可以 更快、更省显存、更能并发处理多个请求。
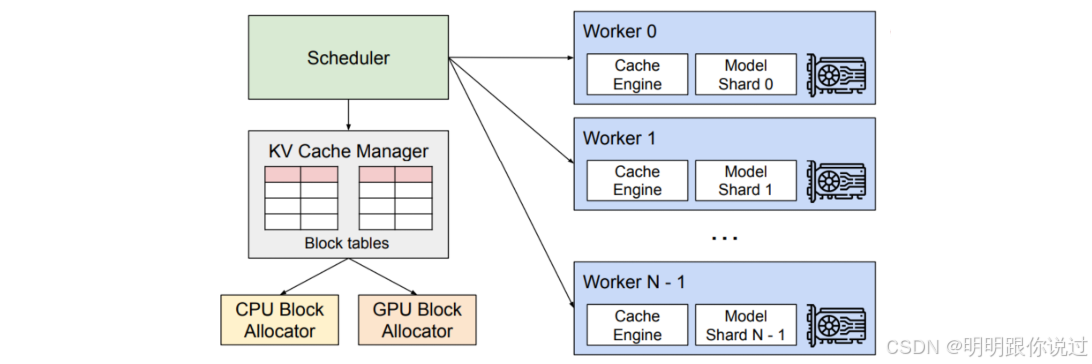
🔍 vLLM 是什么?
vLLM = very fast LLM,由 UC Berkeley 和前 OpenAI 工程师团队开发,核心目标是:
-
🚀 提升推理速度
-
💾 高效利用 GPU 显存
-
👥 支持多个用户同时访问
-
💬 原生支持流式输出
它支持 GPT-2、LLaMA、Qwen、Baichuan 等多种开源大模型,并兼容 HuggingFace 接口和 OpenAI API。
⚙️ 核心技术亮点:PagedAttention
传统 Transformers 推理是这样的:
每个请求都要分配完整的上下文缓存(KV Cache),浪费显存 + 容量上限受限 😫
vLLM 的创新点就是:PagedAttention —— 像操作系统的虚拟内存机制一样,把 KV 缓存“分页”管理 📄📄📄

✅ 优势:
| 对比点 | Transformers | vLLM |
|---|---|---|
| 显存利用 | 🟥 固定分配,浪费多 | ✅ 动态分页,利用率高 |
| 并发能力 | 🟥 并发少就炸显存 | ✅ 高并发不卡 |
| 推理速度 | ⏳ 快但易堵塞 | ⚡ 超高吞吐量 |
| 支持流式 | ❌ 需魔改 | ✅ 原生支持 |
| API 接入 | 🟨 HuggingFace 需要配置 | ✅ 兼容 OpenAI 接口 |
📊 一个真实测试场景
比如你有一张 A100 显卡,想同时给 10 个用户响应聊天请求:
-
用 Transformers,大概撑到 3~4 个用户就 OOM(爆内存)💥
-
用 vLLM,可以轻松支持 几十个并发请求,还更快!
在同等硬件下,吞吐量提升 2~4 倍,延迟下降 30%~70% 是常见表现。
如果你正在考虑部署 LLM,大概率你想做的是:
-
💬 聊天机器人
-
📄 文档问答系统
-
🧪 AI Copilot / 智能体系统
👉 那么直接用 vLLM 部署会比 Transformers 更稳定、更高效!
✅ 小结:
vLLM 就像是 Transformers 的“超进化形态”:
更聪明地管理内存 + 更高效地做推理 + 更流畅地接入产品
3、支持 LoRA 的大模型有哪些?
🔥 支持 LoRA 的大模型一览
| 大模型名称 | 参数规模 | 特色/用途 | LoRA 支持情况 |
|---|---|---|---|
| LLaMA 系列 | 7B/13B/65B | 轻量开源,效果好,社区活跃 | 完全支持,LoRA 微调最早适配之一 |
| LLaMA2 系列 | 7B/13B/70B | Meta 发布,性能提升 | 支持,广泛应用于各类微调和下游任务 |
| Falcon 系列 | 7B/40B | 性价比高,适合对话和生成 | 支持,社区已有丰富 LoRA 微调案例 |
| Qwen 系列 | 7B/14B | 中文+英文双语强劲 | 支持,支持 QLoRA(量化 + LoRA) |
| Baichuan 系列 | 7B/13B/26B | 中文开源大模型 | 支持,社区微调工具链日渐完善 |
| ChatGLM 系列 | 6B/12B | 中文对话,开源效果不错 | 支持,LoRA 微调文档和代码较多 |
| StableLM | 7B/13B | 主要用于文本生成 | 支持,已被 LoRA 微调和扩展 |
| GPT-NeoX / GPT-J | 6B/20B | 开源替代方案,结构类似 GPT-3 | 支持,LoRA 微调方案成熟 |
🌟 额外说明
-
绝大多数基于 Transformer 架构的模型都可以用 LoRA 进行微调,只要模型权重和结构开放,配合 PEFT(Parameter-Efficient Fine-Tuning)工具就能用。
-
LoRA 还能和量化技术(如 QLoRA)结合,极大降低显存占用。
-
大模型社区通常会配套提供 LoRA 微调脚本,省心又方便!

4、常见的模型微调方式
1️⃣ 全参数微调(Full Fine-tuning)💪
🧠原理:直接对模型中所有参数都进行训练。
🔧特点:
-
优点:效果最好,模型彻底“学会”你的任务。
-
缺点:需要超大显存、训练时间长、不易迁移。
📦 适用场景:你有 大量高质量数据 和 足够计算资源(比如几张 A100),比如企业级模型定制。
2️⃣ LoRA(Low-Rank Adaptation)✨🔥
🧠原理:只微调模型中的“低秩插入模块”(adapter),主模型参数保持不动。
🔧特点:
-
优点:显存需求大减,训练速度快,可以快速切换多个微调版本。
-
缺点:对于一些复杂任务可能效果略逊全参微调。
📦 适用场景:中小模型、消费级显卡(如 3090/4090)、定制 ChatGPT、AI Agent 等。
🌟 关键词:快、轻、准!
3️⃣ Adapter 微调 🧩
🧠原理:在模型层之间插入小网络模块(Adapter),只训练这些模块。
🔧特点:
-
思路类似 LoRA,但实现不同,通常训练效率略低。
-
模块化设计,可插拔、迁移性好。
📦 适用场景:多任务迁移学习、研究型探索。
4️⃣ Prefix Tuning / Prompt Tuning 📝
🧠原理:不是训练模型参数,而是训练“前缀向量”或“提示词向量”。
🔧特点:
-
极其轻量,参数少到只有几万甚至几千个。
-
对模型影响小,可快速应用于多个任务。
📦 适用场景:多任务快速适配、参数敏感场景、嵌入式模型部署。
5️⃣ Instruction Fine-tuning(指令微调)📘
🧠原理:训练模型更好理解“指令风格”的提示(Prompt),如“请帮我总结这段文字”。
🔧特点:
-
类似 full fine-tuning,但用的数据是“指令-输出”格式。
-
通常结合 LoRA 或 PEFT 方式实现。
📦 适用场景:对话模型(如 ChatGPT)、助手型 Agent、大语言模型服务。
6️⃣ DPO(Direct Preference Optimization)⚖️
🧠原理:使用用户偏好(偏好对比数据)训练模型生成更符合人类偏好的回复。
🔧特点:
-
是 RLHF(人类反馈强化学习)的替代方案。
-
更稳定、易于训练、常配合 SFT 使用。
📦 适用场景:训练更“聪明、讨喜”的助手型大模型(如 Claude、GPT 等)
✅ 小结:
| 微调方式 | 参数量 | 显存占用 | 训练速度 | 效果 | 适合谁 |
|---|---|---|---|---|---|
| 全参数微调 | 高 | 高 | 慢 | 💯 | 预算充足企业级 |
| LoRA | 低 | 低 | 快 | 👍 | 个人 / 中小团队 |
| Adapter | 中 | 中 | 中 | 👍 | 多任务研究 |
| Prompt Tuning | 极低 | 极低 | 非常快 | 一般 | 快速验证 |
| Instruction Tuning | 中 | 中 | 中 | 💡 | 聊天模型、Q&A |
| DPO | 中 | 中 | 中 | 😍 | 聊天助手优化 |

三、微调实战
1、微调步骤
📌 项目目标
利用大语言模型(LLM)能力,通过 LoRA 微调方法,让模型能够判断商品评论文本的情感倾向(积极/消极)。
🧰 主要技术栈
| 类别 | 工具 |
|---|---|
| 模型结构 | Transformer-based LLM(如 LLaMA、Qwen) |
| 微调方式 | LoRA(Low-Rank Adaptation) |
| 模型加载 | 🤗 HuggingFace transformers + peft |
| 推理部署 | PyTorch + Transformers |
| 数据格式 | JSON 格式,字段为 "sentence" 和 "label" |
| 性能评估 | scikit-learn → accuracy_score |
📁 数据准备
✅ 训练数据格式(训练集 & 验证集)
{"sentence": "这家店的服务态度很好,菜品也很精致。","label": 1 // 1表示积极,0表示消极
}-
sentence: 商品评论文本 -
label: 对应的情感标签(0=消极,1=积极)
✅ 划分建议
-
训练集:90%
-
验证集:10%
-
测试集:单独保留,不参与训练
🛠 LoRA 微调流程(训练阶段)
-
加载基座大模型
-
支持 4bit/8bit 加载节省显存(使用
load_in_4bit=True)。
-
-
准备 LoRA 配置和适配器
-
设置
target_modules、r、alpha、dropout等超参数。 -
使用
peft的get_peft_model。
-
-
构造 prompt 格式
-
采用“指令微调”风格输入,结构如下:
-
<s>[INST] 请判断下面商品评论的情感(积极/消极):评论内容如下:
这家服务不错,值得再来。 [/INST]-
训练模型
-
常用框架:
transformers.Trainer或LoRA + SFT Trainer -
监控验证集 loss 或准确率,必要时使用 early stopping
-
-
保存 LoRA Adapter
-
保存 adapter(差异权重)而非整个模型,便于后续部署
-
🚀 微调后推理(inference)
-
加载 base 模型 + LoRA adapter
base_model = AutoModelForCausalLM.from_pretrained(...) model = PeftModel.from_pretrained(base_model, adapter_path) -
生成 prompt 并预测
-
使用 tokenizer 编码输入
-
model.generate(...)生成预测 -
截取生成的前几个 token 判断是否包含“积极”或“消极”
-
-
标签识别
-
如果生成内容中包含“积极”,记为 1
-
包含“消极”记为 0
-
否则为 -1(无效预测)
-
📊 模型效果评估
-
批量推理预测
-
使用
predict_labels_batch()支持 batch_size 并行预测
-
-
计算准确率
-
使用
sklearn.metrics.accuracy_score -
忽略预测为
-1的样本(即模型未识别出的标签)
-
-
打印预测示例
-
输出示例对比:文本 / 真实标签 / 预测标签
-

2、微调
1. 模型加载与 LoRA 适配阶段
# 本地模型路径
model_path = "/root/autodl-tmp/llama2-7b"# 加载 tokenizer(本地)
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
tokenizer.pad_token = tokenizer.eos_token# 加载模型(本地)
model = AutoModelForCausalLM.from_pretrained(model_path,device_map="auto",torch_dtype=torch.float16,load_in_4bit=True # 如果你要使用 4bit 加载(需要 bitsandbytes 支持)
)# LoRA 配置
lora_config = LoraConfig(r=8,lora_alpha=16,target_modules=["q_proj", "v_proj"],lora_dropout=0.05,task_type=TaskType.CAUSAL_LM
)# 应用 LoRA
model = get_peft_model(model, lora_config)-
AutoTokenizer.from_pretrained(...):从指定路径加载分词器。 -
use_fast=False:使用原始(非 Rust 实现的)分词器,更兼容复杂的自定义模型。 -
tokenizer.pad_token = tokenizer.eos_token:-
因为 LLaMA2 默认没有
<pad>token,这里将pad_token设置为eos_token(即句子结束符),确保在做 padding 时不会出错。
-
-
AutoModelForCausalLM:加载一个用于因果语言建模(Causal LM)的模型,也就是用于文本生成任务。 -
device_map="auto":让 transformers 自动将模型权重分布在多个 GPU 上。 -
torch_dtype=torch.float16:用半精度加载模型,节省显存。 -
load_in_4bit=True:使用 4bit 量化加载模型(需要安装bitsandbytes),进一步减小显存占用,适合在 3090 或较小显存机器上运行。
LoRA 微调的超参数:
| 参数 | 说明 |
|---|---|
r=8 | 降维后矩阵的秩,控制 LoRA 层的容量(越大越强) |
lora_alpha=16 | 缩放系数,用于调节 LoRA 的影响力 |
target_modules=["q_proj", "v_proj"] | 指定要注入 LoRA 的线性层(这里只对 Attention 中的 Query 和 Value 投影层进行适配) |
lora_dropout=0.05 | 在 LoRA 层输入上添加 Dropout,提高鲁棒性 |
task_type=TaskType.CAUSAL_LM | 指明当前任务是 Causal LM,用于设置 LoRA 适配的上下文 |
-
get_peft_model(...):使用我们提供的 LoRA 配置,将 LoRA 层注入到指定的模型中。 -
注入后,训练时只会更新 LoRA 层参数,而不会修改原始模型的权重,这种方式称为 参数高效微调(PEFT)。
这段代码的作用是:加载 LLaMA2 模型及 tokenizer,并通过 LoRA 技术为其增加可微调的轻量参数结构,为接下来的微调训练做准备。
2. 数据预处理阶段
# 标签映射
label_map = {1: "积极", 0: "消极"}def preprocess(example):prompt = (f"<s>[INST] 请判断下面商品评论的情感(积极/消极):评论内容如下:\n"f"{example['sentence']} [/INST] {label_map[example['label']]} </s>")tokenized = tokenizer(prompt,padding="max_length",truncation=True,max_length=512,)tokenized["labels"] = tokenized["input_ids"].copy()return tokenized# 加载本地 JSON 文件(数组格式)
dataset = load_dataset("json", data_files="/root/autodl-tmp/data.json", split="train")# 数据预处理
tokenized_dataset = dataset.map(preprocess, remove_columns=dataset.column_names)-
<s>和</s>:LLaMA2 格式中的起始和结束 token。 -
[INST]...[/INST]:是 LLaMA2 对话式输入格式,指示模型这是一个“指令 + 输入”,目标是学习输出答案(“积极”或“消极”)。 -
padding="max_length":将所有样本补齐到固定长度(512)。 -
truncation=True:若样本过长,则截断到max_length=512。 -
结果是一个字典,包含
input_ids,attention_mask, 等字段。 -
在
CausalLM训练中,模型的目标就是预测下一个 token,因此把输入本身作为标签是常见做法。 -
这样模型就能学习根据 prompt 输出一个合适的响应(情感判断)。
-
split="train"表示将其视作训练集。 -
map(preprocess):对每条数据运行preprocess。 -
remove_columns=dataset.column_names:删除原始字段(如"sentence","label"),只保留 tokenizer 返回的字段(如"input_ids","labels")。
✅ 小结:
-
加载原始 JSON 格式的数据(每条是评论 + 情感标签);
-
对每条评论构造 prompt(问答形式);
-
使用 tokenizer 编码;
-
设置输入和标签;
-
最终得到适合用于 LLaMA2 微调的训练数据。
3. 训练参数配置阶段
training_args = TrainingArguments(output_dir="./lora-llama2-sentiment",per_device_train_batch_size=4,dataloader_num_workers=12,gradient_accumulation_steps=8,num_train_epochs=3,learning_rate=2e-4,fp16=False,bf16=True,logging_steps=10,save_steps=100,save_total_limit=2
)- 创建一个
TrainingArguments实例,用于控制模型训练的各种行为,比如批大小、学习率、训练轮数、日志记录等。 - 指定训练结果输出目录,包括:
-
微调后的模型权重(如 adapter)
-
tokenizer
-
日志文件
-
检查点(checkpoints)
-
- 每张 GPU 上的训练批大小是 4。
-
如果你用了多张 GPU,会自动乘以 GPU 数;
-
总的批大小 =
batch_size × gradient_accumulation_steps × num_GPUs
-
- 设置 Adam 优化器的学习率为 0.0002。
-
适合 LoRA 微调任务(只训练 adapter 参数)
-
4. 训练启动阶段
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_dataset,tokenizer=tokenizer
)trainer.train()- model:使用了 LoRA 适配器的 LLaMA2 模型,这是我们前面通过 get_peft_model() 得到的微调模型。
- args:即训练超参数,使用我们在前面 TrainingArguments(...) 中配置的参数(如学习率、保存频率、batch size 等)。
- train_dataset:微调使用的训练数据集,已经过 preprocess 函数处理并被 tokenizer 编码为模型可以识别的格式。
- tokenizer:用于训练过程中自动对输入进行编码,以及在保存模型时保存 tokenizer 配置。
启动模型训练过程:
-
加载
train_dataset,按照设定的 batch size 分批送入模型; -
每一步训练都会计算 loss、执行反向传播、更新 LoRA adapter 参数;
-
根据设定的
save_steps、logging_steps自动保存 checkpoint 和日志; -
整个过程持续
num_train_epochs个 epoch; -
训练完成后,模型会保留在内存中,我们可以用
.save_pretrained()保存结果。
5. 模型保存阶段
model.save_pretrained("lora-sentiment-adapter")
tokenizer.save_pretrained("lora-sentiment-adapter")完整代码
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from peft import get_peft_model, LoraConfig, TaskType
import torch
from datasets import load_dataset# 本地模型路径
model_path = "/root/autodl-tmp/llama2-7b"# 加载 tokenizer(本地)
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
tokenizer.pad_token = tokenizer.eos_token# 加载模型(本地)
model = AutoModelForCausalLM.from_pretrained(model_path,device_map="auto",torch_dtype=torch.float16,load_in_4bit=True # 如果你要使用 4bit 加载(需要 bitsandbytes 支持)
)# LoRA 配置
lora_config = LoraConfig(r=8,lora_alpha=16,target_modules=["q_proj", "v_proj"],lora_dropout=0.05,task_type=TaskType.CAUSAL_LM
)# 应用 LoRA
model = get_peft_model(model, lora_config)# ____________________________________________________________________________# ✅ 提前定义 label_map
label_map = {1: "积极", 0: "消极"}
def preprocess(example):prompt = (f"<s>[INST] 请判断下面商品评论的情感(积极/消极):评论内容如下:\n"f"{example['sentence']} [/INST] {label_map[example['label']]} </s>")tokenized = tokenizer(prompt,padding="max_length",truncation=True,max_length=512,)tokenized["labels"] = tokenized["input_ids"].copy()return tokenized# 加载本地 JSON 文件(数组格式)
dataset = load_dataset("json", data_files="/root/autodl-tmp/data.json", split="train")# 数据预处理
tokenized_dataset = dataset.map(preprocess, remove_columns=dataset.column_names)# ___________________________________________________________________________________________training_args = TrainingArguments(output_dir="./lora-llama2-sentiment",per_device_train_batch_size=4,dataloader_num_workers=12,gradient_accumulation_steps=8,num_train_epochs=3,learning_rate=2e-4,fp16=False,bf16=True,logging_steps=10,save_steps=100,save_total_limit=2
)trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_dataset,tokenizer=tokenizer
)trainer.train()# _______________________________________________________________________________________
model.save_pretrained("lora-sentiment-adapter")
tokenizer.save_pretrained("lora-sentiment-adapter")启动训练:
整个训练过程大概会持续8~10小时左右,耐心等待即可
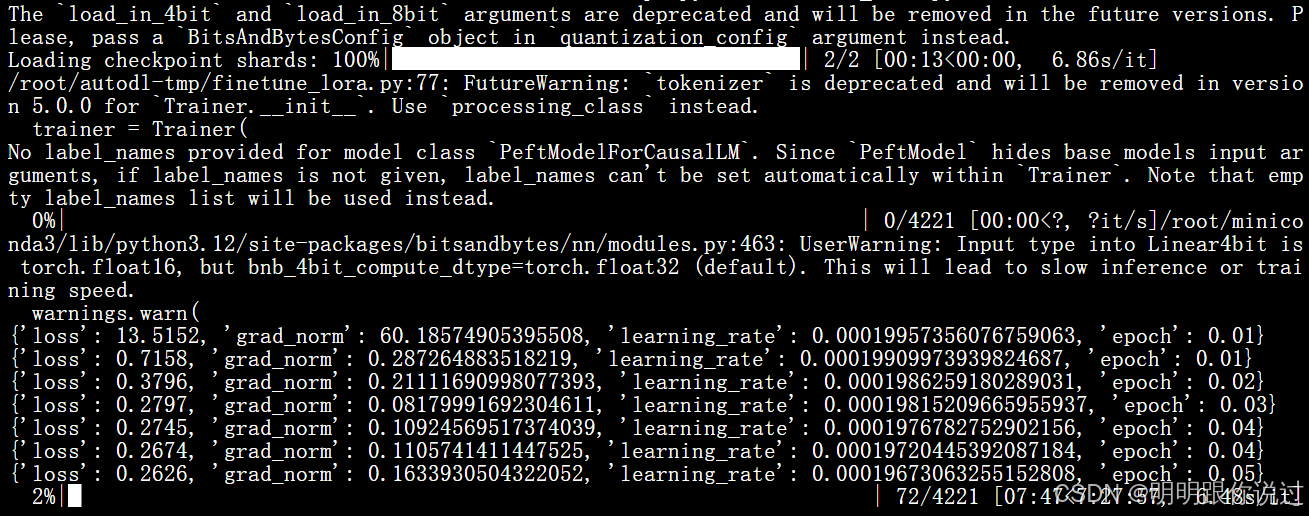
{'loss': 13.5152, 'grad_norm': 60.18574905395508, 'learning_rate': 0.00019957356076759063, 'epoch': 0.01}
{'loss': 0.7158, 'grad_norm': 0.287264883518219, 'learning_rate': 0.00019909973939824687, 'epoch': 0.01}
{'loss': 0.3796, 'grad_norm': 0.21111690998077393, 'learning_rate': 0.0001986259180289031, 'epoch': 0.02}
{'loss': 0.2797, 'grad_norm': 0.08179991692304611, 'learning_rate': 0.00019815209665955937, 'epoch': 0.03}
{'loss': 0.2745, 'grad_norm': 0.10924569517374039, 'learning_rate': 0.0001976782752902156, 'epoch': 0.04}
{'loss': 0.2674, 'grad_norm': 0.1105741411447525, 'learning_rate': 0.00019720445392087184, 'epoch': 0.04}
{'loss': 0.2626, 'grad_norm': 0.1633930504322052, 'learning_rate': 0.00019673063255152808, 'epoch': 0.05}
✅ 每一条日志都包含以下信息:
| 字段 | 含义 | 示例 |
|---|---|---|
loss | 当前步的平均训练损失(越低越好) | 0.2674 |
grad_norm | 梯度范数(表示模型参数更新的强度) | 0.1105 |
learning_rate | 当前步使用的学习率(会随 scheduler 动态变化) | 0.0001972 |
epoch | 当前所在的训练周期(总共设为 3 epoch) | 0.05 表示刚刚开始第 1 个 epoch |
🔍 各指标解读:
1. Loss 损失值
-
第一个 step loss 是
13.5152,说明模型刚开始训练误差很大(常见)。 -
很快收敛到
0.2~0.3,说明模型已经学会了基本的模式,训练效果良好。
2. Grad Norm(梯度范数)
-
初始
grad_norm = 60.18,表示参数更新很剧烈(因为误差大)。 -
后续
grad_norm降到0.1 ~ 0.2,表明训练过程趋于稳定。
3. Learning Rate(学习率)
-
学习率从
2e-4开始,逐步下降(我们用了默认的线性学习率调度器lr_scheduler_type="linear")。 -
学习率衰减有助于模型在训练后期微调参数。
4. Epoch(训练周期)
-
当前显示
epoch = 0.05,意味着训练才进行了一小部分(每轮遍历训练集是 1 个 epoch)。
📈 总体训练情况:
从日志看,模型训练 快速收敛、稳定下降,说明:
-
数据预处理格式良好;
-
LoRA 插入位置合适;
-
模型能够很好地学习我们定义的情感分析任务。
此时观看显卡,可以明显看到GPU使用率和显存使用率明显上升
训练结束后,会产生两个新的文件夹,这就是我们刚刚训练的模型参数:
3、测试
编写测试脚本
import json
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
from sklearn.metrics import accuracy_score# 标签映射
label_map = {"积极": 1, "消极": 0}
label_map_reverse = {1: "积极", 0: "消极"}# 构造提示词模版
def build_prompt(text):return f"<s>[INST] 请判断下面商品评论的情感(积极/消极):评论内容如下:\n{text} [/INST]"# 加载模型与 tokenizer
def load_model_tokenizer(model_path):base_model = AutoModelForCausalLM.from_pretrained(model_path,device_map="auto",torch_dtype=torch.float16,load_in_4bit=True)model = PeftModel.from_pretrained(base_model, model_path, device_map="auto")tokenizer = AutoTokenizer.from_pretrained(model_path)tokenizer.pad_token = tokenizer.eos_tokenreturn model, tokenizer# 预测情感类别(返回 0 或 1)
def predict_label(model, tokenizer, text):prompt = build_prompt(text)inputs = tokenizer(prompt, return_tensors="pt", truncation=True, max_length=512).to(model.device)input_ids_len = inputs["input_ids"].shape[1]with torch.no_grad():outputs = model.generate(**inputs,max_new_tokens=10,do_sample=False,eos_token_id=tokenizer.eos_token_id,pad_token_id=tokenizer.pad_token_id)generated_ids = outputs[0][input_ids_len:]generated_text = tokenizer.decode(generated_ids, skip_special_tokens=True).strip()print("🧾 回答部分:", repr(generated_text))for key in label_map:if key in generated_text[:6]:return label_map[key]return -1# 主函数:读取数据并评估
def main():model_path = "./lora-sentiment-adapter"test_file = "test.json"model, tokenizer = load_model_tokenizer(model_path)with open(test_file, "r", encoding="utf-8") as f:test_samples = json.load(f)y_true = []y_pred = []print("\n预测结果示例:")for sample in test_samples:text = sample["sentence"]true_label = sample["label"]pred_label = predict_label(model, tokenizer, text)y_true.append(true_label)y_pred.append(pred_label)print(f"文本: {text}")print(f"真实: {label_map_reverse[true_label]},预测: {label_map_reverse.get(pred_label, '无法识别')}")print("-" * 40)# 计算准确率(忽略预测失败项)valid_pairs = [(yt, yp) for yt, yp in zip(y_true, y_pred) if yp != -1]if valid_pairs:acc = accuracy_score([yt for yt, _ in valid_pairs], [yp for _, yp in valid_pairs])print(f"\n✅ 有效预测准确率: {acc * 100:.2f}%")else:print("\n❌ 所有样本预测失败,请检查模型是否能正确生成标签")if __name__ == "__main__":main()📌 整体测试流程大致分为 4 个部分:
- 定义标签映射与提示模板
- 加载模型与 tokenizer
- 单个样本预测逻辑
- 主流程:加载测试数据,预测并评估准确率
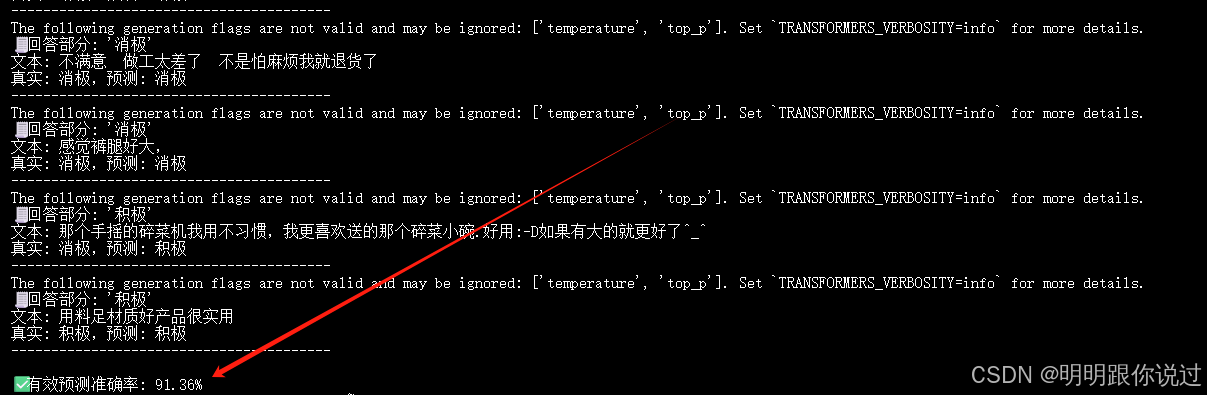
测试结果:
四、使用 vLLM 启动服务(支持 LoRA)
1、启动 API Server
python -m vllm.entrypoints.openai.api_server \--model /root/autodl-tmp/llama2-7b \--tokenizer /root/autodl-tmp/llama2-7b \--enable-lora \--dtype float16 \--max-model-len 2048- python -m vllm.entrypoints.openai.api_server:👉 启动 vLLM 的 OpenAI API 接口服务,相当于本地部署一个类似 OpenAI 的 API 服务。
- --model /root/autodl-tmp/llama2-7b:📦 指定主模型权重路径(通常是 Hugging Face 的
.bin权重或本地保存的模型目录)。我们已经把meta-llama/Llama-2-7b-hf拉到了本地/root/autodl-tmp/llama2-7b,这边加载它。 - --tokenizer /root/autodl-tmp/llama2-7b:🧾 指定 tokenizer 的路径,通常和模型路径一样(除非你用了不同的 tokenizer)。
- --enable-lora:🔧 启用 LoRA 支持,表示这个模型加载后,可以在运行时动态加载 LoRA adapter 权重(例如通过 API 指定
lora_id),支持多 LoRA 热切换。
⚠️ 注意:vLLM 并不会自动加载 LoRA adapter,需要通过 API 发送加载请求或传参。
- --dtype float16:🧮 指定推理使用的数据类型为
float16,即半精度浮点,能显著降低显存占用、提升速度。3090 显卡支持得很好。 - --max-model-len 2048:📝 设置最大上下文长度(即每次输入序列最大长度),默认是 2048,如果你训练时有更长上下文可设置得更大(前提是模型结构支持)。
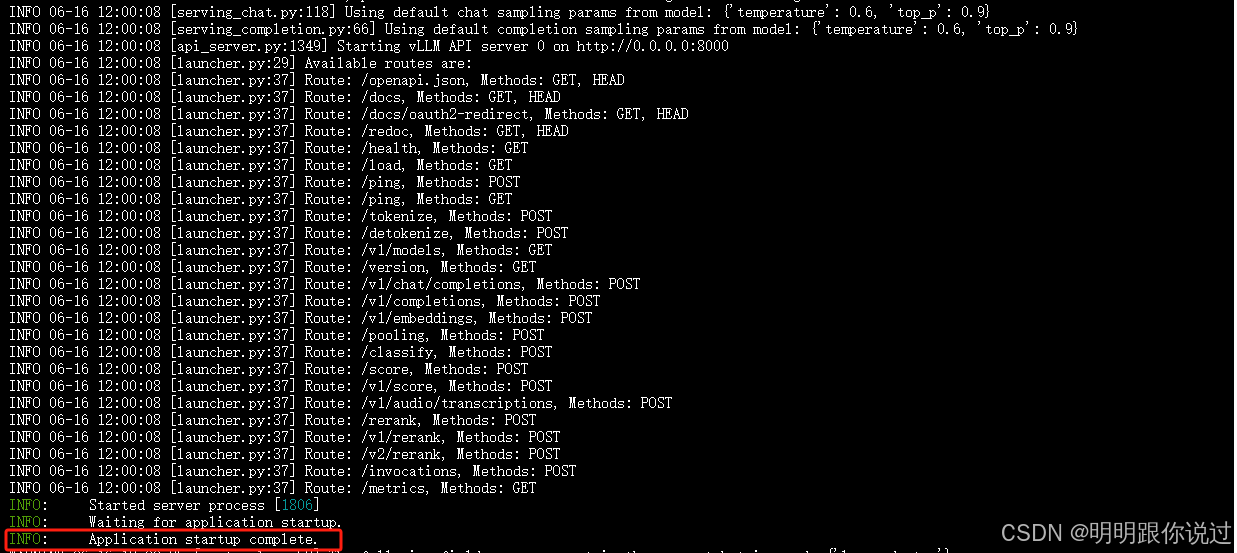
2、使用带 LoRA 的模型进行推理
加载后,通过 Completions API 调用时指定 lora_adapter 参数:
curl -X POST http://localhost:8000/v1/completions \-H "Content-Type: application/json" \-d '{"model": "/root/autodl-tmp/llama2-7b","prompt": "<s>[INST] 请判断下面商品评论的情感(积极/消极):评论内容如下:\n手机质量很好,值得购买! [/INST] 积极 </s>\n<s>[INST] 请判断下面商品评论的情感(积极/消极):评论内容如下:\n外包装破损严重,产品不满意。 [/INST] 消极 </s>\n<s>[INST] 请判断下面商品评论的情感(积极/消极):评论内容如下:\n这个产品很好 [/INST]","max_tokens": 10,"temperature": 0,"lora_adapter": "sentiment"}'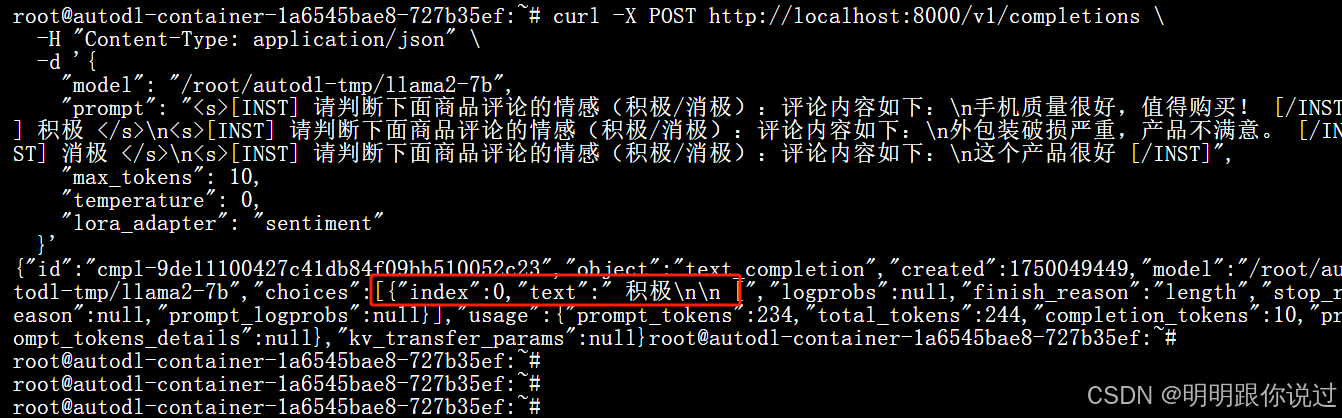
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!

)
感知机)


