简介
MinerU 是一款功能全面的文档处理系统,旨在将 PDF 和其他文档格式转换为机器可读的格式,例如 Markdown 和 JSON。该系统专注于在保留文档结构的同时,准确提取文档内容,处理复杂的布局,并转换公式和表格等特殊元素。
解析流程
MinerU系统将处理流程划分为三个阶段:数据、推理、程序处理,分别对应Dataset、InferenceResult和PipeResult
InferenceResult(推理结果)详细功能
- 布局分析:识别文档中的各种元素(标题、段落、图像、表格等)
- 公式检测与识别:包含公式检测模型(MFD)与公式识别模型(MFR)
- 表格识别:负责分析和提取表格结构
- 语言检测:使用YOLOv11模型检测文档语言,以选择合适的OCR模型
- 文本识别:根据模式不同,使用OCR或直接提取文本
PipeResult(管道结果)详细功能
- 结构化处理:将InferenceResult中的原始数据组织成结构化的文档
- 阅读顺序排序:确定文档元素的正确阅读顺序
- 格式转换:生成多种输出格式(Markdown、JSON等)
- 可视化生成:创建各种可视化结果(布局图、文本跨度图等)
- 元素关系处理:处理文档元素之间的层次和逻辑关系
术语
bbox
bounding box(边界框),指的是文档中每个文本元素(如词语、短语、文本块)在页面上的位置和大小。每个 bbox 通常表示为一个四元组:[x0, y0, x1, y1],表示左上角和右下角的坐标。
poly
Polygon Coordinates(多边形坐标),用来描述图像中某个区域的几何形状,常用于表示文本框、表格单元格、图形轮廓等。这些坐标定义了一个多边形区域,可以是矩形、四边形或任意多边形。
一个 polygon coordinate 通常是一个点的列表,每个点是一个 (x, y) 坐标对:
[[x1, y1],[x2, y2],[x3, y3],[x4, y4]
]
这表示一个 4 个点的多边形,如果首尾闭合,它就是一个四边形。
安装
模型文件
解析PDF需要用到以下模型:
- Layout:布局识别模型,用于对页面元素进行识别,包含LayoutLMv3,YOLO(默认)
- MFD: 公式检测(Math Formula Detection),框选出公式的位置,用的YOLO
- MFR:公式识别(Math Formula Recognition),将图像中的公式转化为接过话表达(如LaTex),用的是UniMERNet。
- OCR:光学字符识别(Optical Character Recognition),将图像中的文字提取出来
- TableRec:表格识别,包含 StructEqTable 和 TableMaster
模型文件发布在
modelscope
和
huggingface
上,官方提供了一个脚本去下载权重文件:
download_models.py
# huggingface
pip install huggingface_hub
wget https://github.com/opendatalab/MinerU/raw/master/scripts/download_models_hf.py -O download_models_hf.py
python download_models_hf.py# modelscope
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/scripts/download_models.py -O download_models.py
python3 download_models.py
MinerU额外用了一个LayoutReader
模型,用于对文档中词语的顺序进行重拍,基于微软的LayoutLMv3进行微调(提升性能,由seq2seq改为transfomer库),详细参考github仓库
解析完成后生成的文件中,xxx_layout.pdf就是该模型输出的文件,点开会发现比xxx_model.pdf中的文件标记的位置更合理。
Windows
pip3 install -U magic-pdf[full] -i https://mirrors.aliyun.com/pypi/simple# 如果要解析word、pptx,需要安装libreoffice(伪代码)
install libreoffice
append "install_dir\LibreOffice\program" to ENVIRONMENT PATH
Linux
pip3 install -U magic-pdf[full] -i https://mirrors.aliyun.com/pypi/simple# 如果要解析word、pptx,需要安装libreoffice
apt-get/yum/brew install libreoffice
Docker
wget https://github.com/opendatalab/MinerU/raw/master/Dockerfile
docker build -t mineru:latest .
docker run --rm -it --gpus=all mineru:latest /bin/bash
magic-pdf --help
配置
minerU会读取用户目录下的magic-pdf.json文件,可以通过MINERU_TOOLS_CONFIG_JSON环境变量,修改默认位置。
如果你的文档不涉及公式,关闭公式识别更好点。
magic-pdf.json
{"bucket_info":{"bucket-name-1":["ak", "sk", "endpoint"],"bucket-name-2":["ak", "sk", "endpoint"]},"models-dir":"/data/model/opendatalab/PDF-Extract-Kit-1___0/models","layoutreader-model-dir":"/data/model/ppaanngggg/layoutreader","device-mode":"cpu","layout-config": {"model": "doclayout_yolo"},"formula-config": {"mfd_model": "yolo_v8_mfd","mfr_model": "unimernet_small","enable": true},"table-config": {"model": "rapid_table","enable": true,"max_time": 400},"config_version": "1.0.0"
}
解析
详细API,参考:https://mineru.readthedocs.io/en/latest/user_guide/usage/api.html
def process_pdf(pdf_file_name:str):import osfrom magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReaderfrom magic_pdf.data.dataset import PymuDocDatasetfrom magic_pdf.model.doc_analyze_by_custom_model import doc_analyzefrom magic_pdf.config.enums import SupportedPdfParseMethodname_without_suff = pdf_file_name.split(".")[0]# prepare envlocal_image_dir, local_md_dir = "output/images", "output"image_dir = str(os.path.basename(local_image_dir))os.makedirs(local_image_dir, exist_ok=True)image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(local_md_dir)# read bytesreader1 = FileBasedDataReader("")pdf_bytes = reader1.read(pdf_file_name) # read the pdf content# proc## Create Dataset Instanceds = PymuDocDataset(pdf_bytes)## inferenceif ds.classify() == SupportedPdfParseMethod.OCR:infer_result = ds.apply(doc_analyze, ocr=True)## pipelinepipe_result = infer_result.pipe_ocr_mode(image_writer)else:infer_result = ds.apply(doc_analyze, ocr=False)## pipelinepipe_result = infer_result.pipe_txt_mode(image_writer)### draw model result on each pageinfer_result.draw_model(os.path.join(local_md_dir, f"{name_without_suff}_model.pdf"))### get model inference resultmodel_inference_result = infer_result.get_infer_res()### draw layout result on each pagepipe_result.draw_layout(os.path.join(local_md_dir, f"{name_without_suff}_layout.pdf"))### draw spans result on each pagepipe_result.draw_span(os.path.join(local_md_dir, f"{name_without_suff}_spans.pdf"))### get markdown contentmd_content = pipe_result.get_markdown(image_dir)### dump markdownpipe_result.dump_md(md_writer, f"{name_without_suff}.md", image_dir)### get content list contentcontent_list_content = pipe_result.get_content_list(image_dir)### dump content listpipe_result.dump_content_list(md_writer, f"{name_without_suff}_content_list.json", image_dir)### get middle jsonmiddle_json_content = pipe_result.get_middle_json()### dump middle jsonpipe_result.dump_middle_json(md_writer, f'{name_without_suff}_middle.json')
Office
def process_office_file(input_file: str):import osfrom magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReaderfrom magic_pdf.model.doc_analyze_by_custom_model import doc_analyzefrom magic_pdf.data.read_api import read_local_office# prepare envlocal_image_dir, local_md_dir = "output/images", "output"image_dir = str(os.path.basename(local_image_dir))os.makedirs(local_image_dir, exist_ok=True)image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(local_md_dir)input_file_name = input_file.split(".")[0]ds = read_local_office(input_file)[0]ds.apply(doc_analyze, ocr=True).pipe_txt_mode(image_writer).dump_md(md_writer, f"{input_file_name}.md", image_dir)
输出格式
MinerU 在处理文档时会生成的许多输出文件,括 Markdown、JSON 格式和可视化 PDF。这些输出可用于多种用途,涵盖内容呈现、调试和质量检查等。
Markdown
以Markdown格式,组织pdf文件中的内容。目前只支持一级标题。格式如下:
# 用途
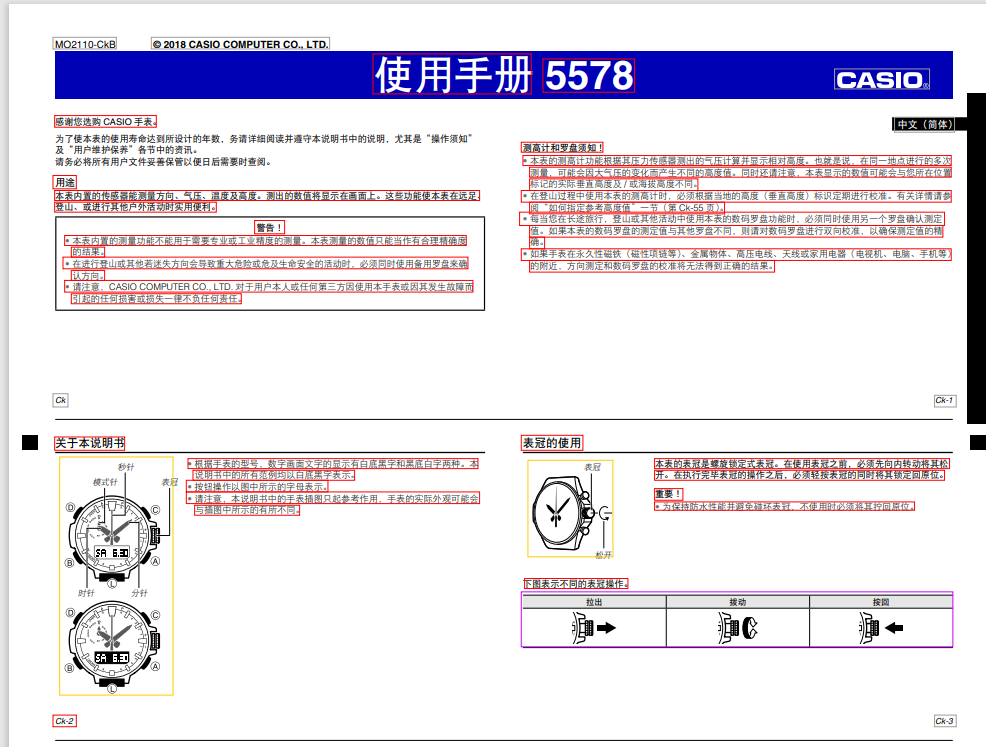
本表内置的传感器能测量方向、气压、温度及高度。测出的数值将显示在画面上。这些功能使本表在远足、登山、或进行其他户外活动时实用便利。 # 警告
·本表内置的测量功能不能用于需要专业或工业精度的测量。本表测量的数值只能当作有合理精确度的结果。
·在进行登山或其他若迷失方向会导致重大危险或危及生命安全的活动时,必须同时使用备用罗盘来确认方向。
·请注意,CASIOCOMPUTERCO.,LTD.对于用户本人或任何第三方因使用本手表或因其发生故障而引起的任何损害或损失一律不负任何责任。Model Output JSON
模型 JSON 输出( document_name_model.json )包含来自布局检测模型的原始推理结果,提供有关每个页面上检测到的元素的信息。
[{"layout_dets": [{"category_id": 0, // Element category (0=title, 1=text, etc.)"poly": [x0,y0,x1,y1,...], // Bounding polygon coordinates"score": 0.999, // Confidence score"latex": "x^2 + y^2 = z^2", // LaTeX content (if applicable)"html": "<table>...</table>" // HTML content (if applicable)},// More detected elements...],"page_info": {"page_no": 0, // Page number (0-indexed)"height": 792, // Page height in points"width": 612 // Page width in points}},// More pages...
]
Intermediate JSON
中间的 JSON 输出( document_name_middle.json )包含中间处理结果,提供了预处理和段落分割后的文档结构的详细信息。
{"pdf_info": [{"preproc_blocks": [...], // Preprocessed blocks before segmentation"layout_bboxes": [...], // Layout bounding boxes"page_idx": 0, // Page index"page_size": [width, height], // Page dimensions"_layout_tree": [...], // Layout tree structure"images": [...], // Image blocks"tables": [...], // Table blocks"interline_equations": [...], // Block equation blocks"discarded_blocks": [...], // Discarded elements"para_blocks": [...] // Segmented paragraph blocks},// More pages...],"_parse_type": "ocr", // Parsing method used"_version_name": "1.3.11" // MinerU version
}
Content List JSON
内容列表 JSON 输出 ( document_name_content_list.json ) 提供文档内容的结构化表示,按内容类型组织。
[{"type": "text", // Content type (text, title, image, table, equation)"text": "Content text", // Text content for text/title types"text_level": 1, // Heading level for title type"page_idx": 0, // Page index// Additional fields for specific types:"img_path": "path/to/image", // For image type"img_caption": ["Caption"], // For image type"table_body": "HTML or LaTeX", // For table type"table_caption": ["Caption"] // For table type},// More content items...
]
如果想获取某个内容的位置,可以按照索引位置(content在当前页出现的位置)跟document_name_middle.json的pdf_info[page_index].preproc_blocks[block_index].bbox
xxx_pdf
infer_result提供了一系列的draw方法,用来将响应的生成内容画到pdf文件上去,便于调试效果(主要是给人看)。如draw_model,draw_layout,draw_span等。
document_name_span.pdf

document_name_model.pdf
document_name_layout.pdf
可以看到,经过layout重拍后,阅读顺序更贴近人阅读的顺序。

)
感知机)


