1. 引言:什么是上下文长度及其重要性
上下文长度(Context Length),也称为上下文窗口(Context Window),指的是大语言模型(LLM)在处理和生成文本时能够有效记忆和利用的信息范围。简单来说,就是模型一次能够“看到”和“记住”的文本序列的最大长度,通常以**词元(token)**的数量来衡量。一个词元可以是一个词、一个子词,甚至一个字符,具体取决于模型的分词策略。
重要性:
-
理解复杂指令和对话: 更长的上下文使得模型能够理解包含多个步骤或依赖先前信息的复杂指令,并在多轮对话中保持连贯性和相关性。
-
处理长文档: 对于文档摘要、问答、信息提取等任务,模型需要能够处理整个文档或大部分内容才能给出准确的结果。例如,分析一份几万词元的法律合同。
-
提升生成质量: 更长的上下文有助于模型捕捉更广泛的语境信息,从而生成更相关、更一致、更有深度的文本。例如,在写故事或报告时,模型可以回顾数千词元前提到的细节。
-
减少信息丢失: 在处理长序列时,如果上下文长度不足,模型可能会丢失早期的重要信息,导致理解偏差或生成内容不连贯。
-
支持更复杂的应用: 许多高级应用,如代码生成与理解(可能涉及数万行代码)、法律文件分析、科学研究等,都依赖于模型处理和理解大规模文本的能力。
因此,扩展上下文长度一直是LLM研究领域的核心目标之一,它直接关系到模型的性能上限和应用场景的广度。
2. 上下文长度的局限性:为什么LLM会受限于上下文长度?
LLM在上下文长度方面受到限制,主要源于以下几个核心技术挑战:
-
计算复杂度 (Computational Complexity):
-
Transformer的自注意力机制 (Self-Attention): 标准的Transformer模型采用自注意力机制,其计算复杂度与上下文长度 N 的平方成正比,即 O(N2⋅d),其中 d 是模型的隐藏层维度。当上下文长度 N 从例如1024词元增加到4096词元(4倍)时,计算量会增加约16倍。这使得在非常长的序列上训练和推理变得非常昂贵和缓慢。
-
-
内存消耗 (Memory Consumption):
-
注意力矩阵: 自注意力机制需要计算并存储一个 N×N 的注意力得分矩阵。这个矩阵的内存消耗同样是 O(N2)。对于一个有32768 (32K) 个词元的上下文,注意力矩阵就需要存储 327682≈109 个值,对内存是巨大的挑战。(大模型在持续推理的过程中,需要缓存一个叫做 KV Cache 的数据快,KV Cache 的大小也与序列长度成正比。以 Llama 2 13B 大模型为例,一个 4K 长的序列大约需要 3G 的显存去缓存 KV Cache,16K 的序列则需要 12G,128K 的序列则需要 100G 显存。)
-

-
激活值存储: 在训练过程中,为了进行反向传播计算梯度,需要存储中间层的激活值。这些激活值的数量也与序列长度 N 成正比,进一步加剧了内存压力。
-
-
位置编码的挑战 (Challenges of Positional Encoding):
-
泛化能力: Transformer模型本身不包含序列顺序信息,需要通过位置编码(Positional Encoding)来注入。传统的绝对位置编码或相对位置编码在训练长度(例如2048词元)之外的序列上泛化能力可能较差。当模型在特定长度的上下文上训练后,直接应用于更长的上下文(例如4096词元)时,位置编码可能无法准确表示超出训练范围的位置信息,导致性能下降。
-
固定与动态: 某些位置编码方法(如正弦位置编码)理论上可以扩展到无限长,但实际效果会受模型学习到的模式限制。可学习的绝对位置编码则直接受限于训练时见过的最大长度。
-
-
长距离依赖问题 (Long-range Dependency Issues):
-
梯度消失/爆炸的缓解: 虽然Transformer通过自注意力机制直接连接任意两个位置的词元,缓解了RNN中的梯度消失/爆炸问题,但在极长的序列中(例如超过数万词元),有效捕捉和利用非常遥远的信息仍然是一个挑战。注意力机制可能会“稀释”或“遗忘”距离过远但仍然相关的信息。
-
信息瓶颈: 即使理论上可以连接,模型是否能有效学习到这些长距离依赖关系,并将其用于后续的预测,也是一个难题。
-
-
训练数据的限制 (Limitations of Training Data):
-
长序列数据的稀缺性: 高质量、多样化的长序列训练数据(例如包含数十万词元的文档)相对短文本数据更为稀缺。模型需要接触足够多的长文本样本才能学会处理长程依赖和利用长上下文。
-
训练成本与效率: 使用长序列进行训练本身就非常耗时耗资源,这限制了研究者和开发者在超长上下文模型上的迭代速度。
-
这些因素共同构成了LLM上下文长度的主要瓶颈。为了突破这些限制,研究者们在注意力机制、模型架构、位置编码和训练策略等多个方面进行了大量的探索和创新。
扩展大模型的上下文长度,一般思路如下:
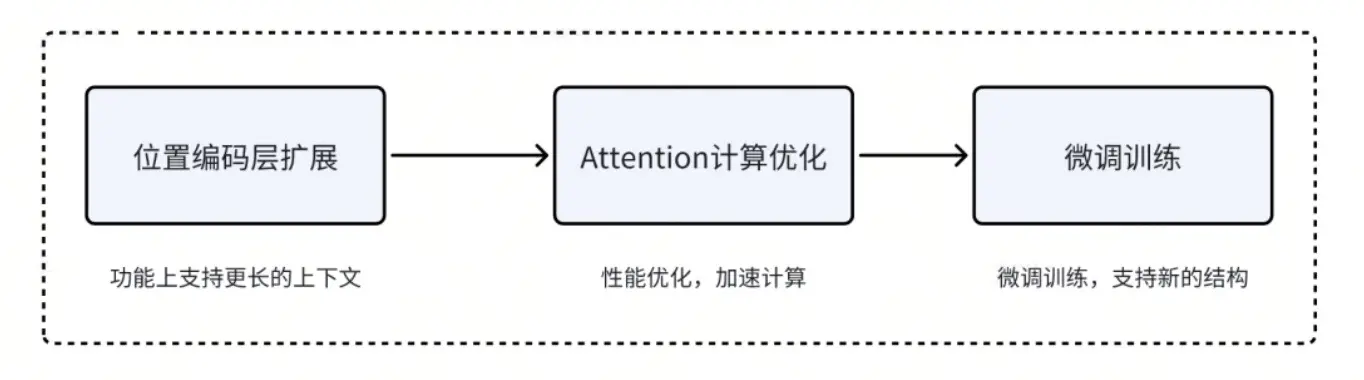
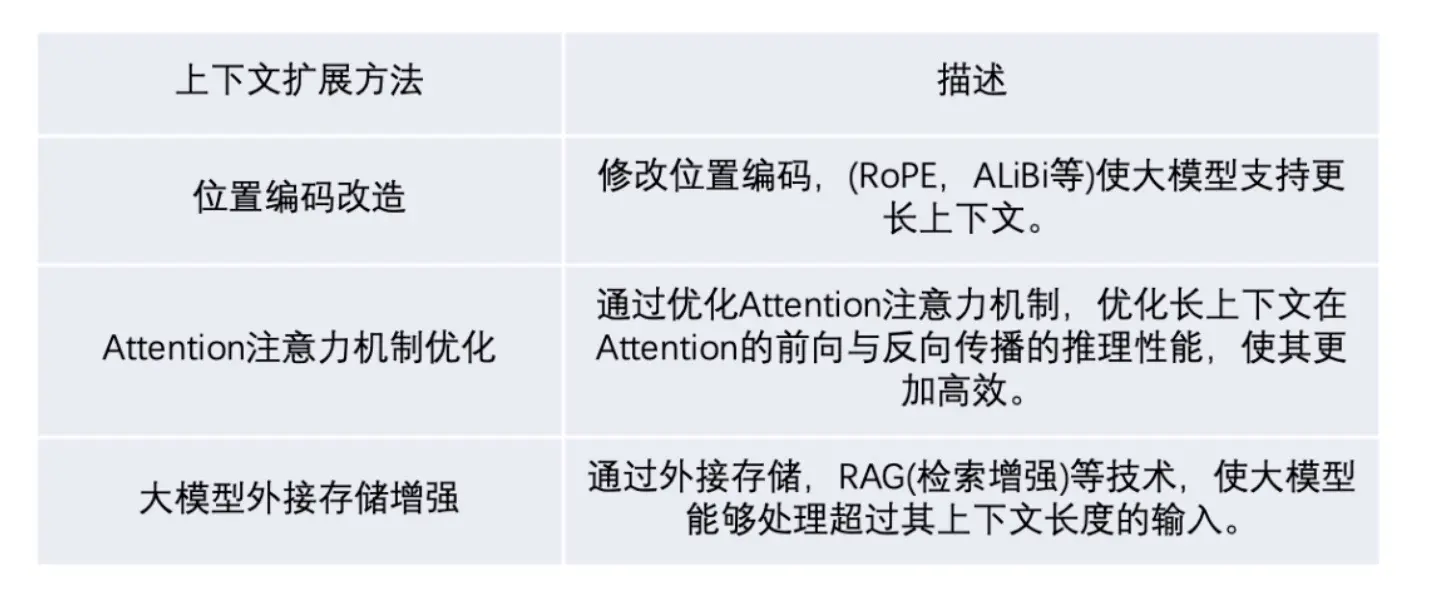
3. 上下文长度的发展历程与技术突破
上下文长度的扩展是LLM发展的一条重要主线,经历了从早期模型的几百个词元到当前动辄数十万甚至上百万词元的过程。
3.1 早期模型 (RNN/LSTM)
-
循环神经网络 (RNN) / 长短期记忆网络 (LSTM) / 门控循环单元 (GRU): 这些模型通过循环结构处理序列信息。
-
Token数范围: 实际有效的上下文长度通常只有几百个词元。
-
技术局限: 它们面临严重的梯度消失/爆炸问题,导致难以捕捉长距离依赖。尽管LSTM和GRU通过门控机制有所缓解,但瓶颈依然存在。
-
3.2 Transformer的出现及其原始Attention
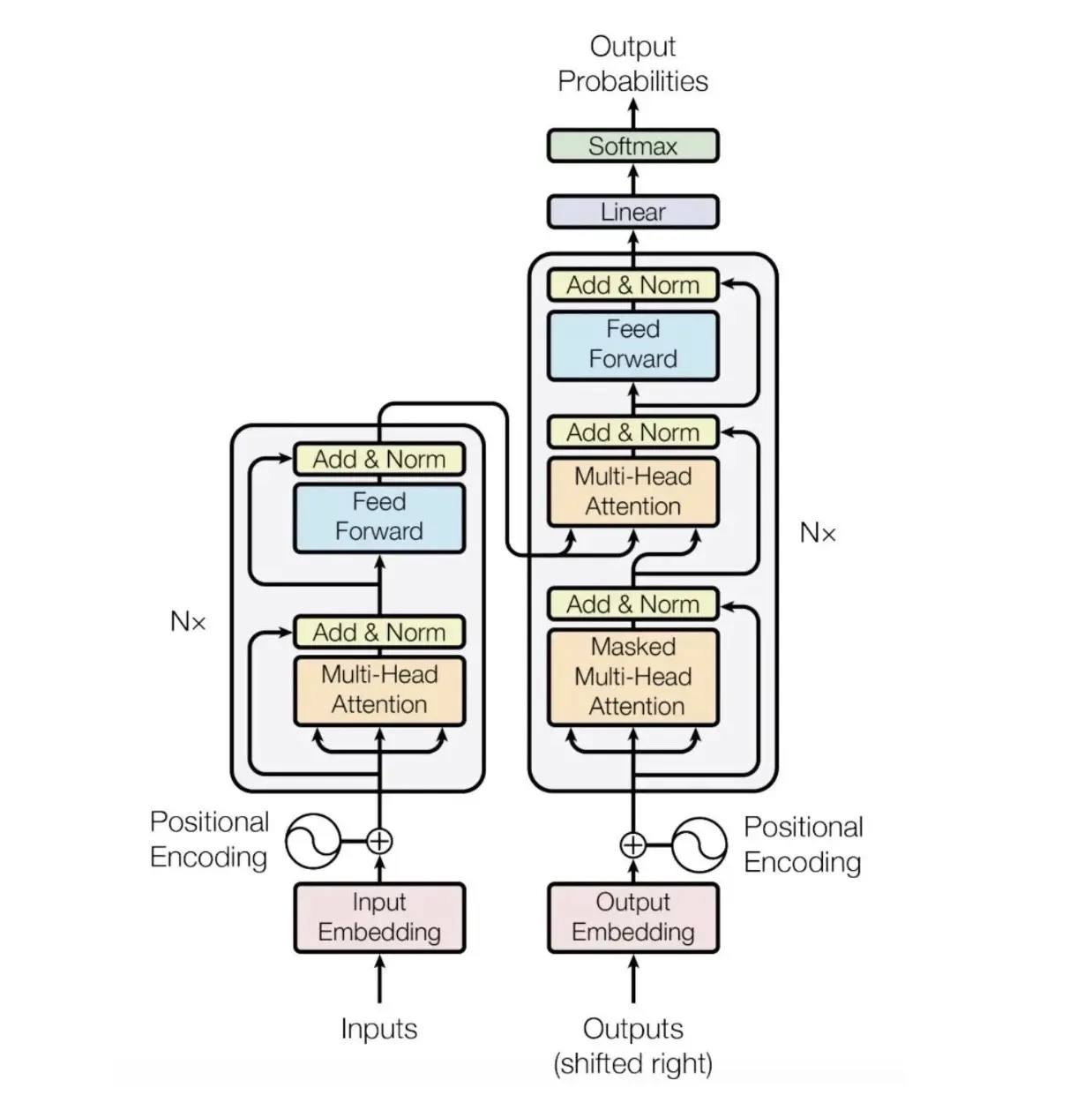
-
Transformer (Vaswani et al., 2017): 引入了自注意力机制 (Self-Attention),允许模型直接计算序列中任意两个词元之间的依赖关系,并行处理整个序列。
-
Token数范围:
-
BERT (Devlin et al., 2018): 通常为 512 词元。
-
GPT-1 (Radford et al., 2018): 512 词元。
-
GPT-2 (Radford et al., 2019): 1024 词元。
-
GPT-3 (Brown et al., 2020): 最初为 2048 词元,后续一些变体支持 4096 词元。
-
-
技术贡献: 极大地改善了长距离依赖的捕捉能力。
-
原始Attention的局限: 其 O(N2) 的计算和内存复杂度成为扩展上下文长度的主要障碍,使得上下文长度难以突破几千词元的规模。
-
3.3 Attention机制的改进
为了克服 O(N2) 的瓶颈,研究者们提出了多种高效的注意力机制变体:
-
稀疏注意力 (Sparse Attention):
-
核心思想: 并非所有词元都需要关注序列中的其他所有词元。
-
代表工作与Token数影响:
-
Longformer (Beltagy et al., 2020): 结合滑动窗口和全局注意力,将复杂度降低到 O(N⋅w)。在其论文中展示了处理高达 4096 词元序列的能力,并为更长序列(如16K甚至32K)提供了理论基础。
-
BigBird (Zaheer et al., 2020): 类似地,通过组合不同类型的稀疏注意力,支持了更长的上下文,例如在实验中达到 4096 词元,并有潜力扩展。
-
-
技术贡献: 这些技术使得模型在不进行近似的情况下,能够处理比标准Transformer更长的序列,通常能将上下文扩展到 4K - 16K 词元的范围。
-
-
线性化注意力 (Linearized Attention):
-
核心思想: 将复杂度降低到线性级别 O(N)。
-
代表工作: Linformer, Performer, Linear Transformer。
-
技术贡献: 理论上允许处理非常长的序列,但有时为了达到线性复杂度可能牺牲一些精度或表达能力。这些方法为探索数十万词元上下文提供了早期思路。
-
-
FlashAttention (Dao et al., 2022) & FlashAttention-2 (Dao, 2023):
-
核心思想: 精确实现标准注意力,但通过I/O感知算法优化内存读写。
-
技术贡献与Token数影响: 这是近年来扩展上下文长度最重要的突破之一。它不是近似注意力,而是通过优化计算过程(分块、重计算)大幅减少了GPU内存带宽瓶颈。
-
这直接推动了主流模型上下文长度的大幅提升:
-
GPT-4 (OpenAI, 2023): 发布时提供 8K 和 32K 词元版本。
-
Claude (Anthropic, 2023): 最初提供 9K,迅速扩展到 100K 词元。
-
Claude 2 & 2.1 (Anthropic, 2023): 上下文长度提升至 200K 词元。
-
GPT-4 Turbo (OpenAI, 2023): 支持高达 128K 词元的上下文。
-
-
FlashAttention使得这些数万到数十万词元级别的精确注意力计算在训练和推理时变得可行且高效。
-
-
3.4 位置编码的改进
-
旋转位置编码 (Rotary Positional Embedding - RoPE) (Su et al., 2021):
-
技术贡献与Token数影响: 具有良好的外推性。例如,LLaMA模型使用RoPE进行预训练,初始上下文长度为 2048 词元。后续通过RoPE的缩放技巧(如NTK-aware scaling, Dynamic NTK)或直接微调,可以将其有效上下文扩展到 4K、8K、16K甚至更长(如Code LLaMA支持高达 100K 词元,LLaMA 2 基础模型支持 4096 词元)。
-
-
ALiBi (Attention with Linear Biases) (Press et al., 2021):
-
技术贡献与Token数影响: 具有出色的外推能力,允许模型在比训练时(例如 2048 词元)更长的序列上(例如 8K 词元或更长)直接推理而无需微调,且性能下降较少。
-
3.5 架构创新
-
Transformer-XL (Dai et al., 2019):
-
Token数影响: 通过片段级循环,有效上下文长度可以远超单个片段的处理长度(例如,片段长度512,但有效上下文可以达到数千)。
-
-
RWKV (Peng et al., 2023):
-
Token数影响: 作为一种结合RNN和Transformer思想的架构,其线性复杂度和常数级推理内存增长,使其在理论上能够处理极长的上下文,已有开源模型支持 数万乃至数十万词元。
-
3.6 其他技术与当前前沿
-
更长的训练序列 (Training with longer sequences):
-
技术贡献与Token数影响: 随着上述高效技术(尤其是FlashAttention和改进的位置编码)的普及,直接使用更长的序列进行预训练和微调成为可能。
-
MPT (MosaicML): 一些MPT模型通过ALiBi等技术支持了 8K 到 65K 的上下文。
-
Gemini 1.5 Pro (Google, 2024): 实现了 100万词元 的标准上下文窗口,并在实验中展示了高达 1000万词元 的处理能力。这是目前公开报道中最长的上下文窗口之一,其背后依赖于注意力机制、架构和训练数据/策略的全面革新。
-
Claude 3 (Anthropic, 2024): 提供高达 200K 词元的上下文窗口,并在“大海捞针”测试中表现出色。
-
-
-
梯度检查点 (Gradient Checkpointing) 和 内存外计算 (Out-of-core computation) 等技术,虽然不直接增加理论上下文长度,但通过优化内存使用,使得在现有硬件上训练和运行具有更长上下文的模型成为现实。
4. 已解决的困难与持续的挑战
4.1 已解决的困难
-
二次方复杂度瓶颈的显著缓解: 通过FlashAttention等技术,精确注意力的实用上下文长度从几千词元(如GPT-3的2K/4K)提升到了数十万词元(如Claude的200K,GPT-4 Turbo的128K),甚至百万级(Gemini 1.5 Pro的1M)。稀疏注意力等方法也为特定场景提供了有效方案。
-
位置编码的外推性增强: RoPE、ALiBi等技术使得模型能够更好地处理超出其原始训练长度的序列。
-
内存管理优化: 使得在有限硬件资源下处理更长序列成为可能。
4.2 持续的挑战
-
计算效率与效果的权衡: 虽然FlashAttention是精确的,但对于百万级甚至更长的上下文,计算成本依然高昂。
-
“大海捞针”问题 (The "Needle in a Haystack" problem): 即使模型能“容纳”100万词元,它是否总能精确找到并利用其中的关键信息?这考验模型在极长上下文中的信息检索和推理能力。虽然像Claude 3和Gemini 1.5 Pro在这方面取得了显著进展,但挑战依然存在,尤其是在信息密度较低或干扰信息较多时。
-
长上下文的有效利用与避免性能退化: 如何确保模型在更长上下文中持续学习和利用信息,而不是仅仅“记住”开头或结尾,或者在中间部分性能下降。
-
评估方法的挑战: 现有的许多基准测试主要针对较短的上下文(几千词元)。如何设计有效的评估方法来衡量模型在数十万乃至百万级词元上下文环境下的真实能力。
-
训练成本和高质量长文本数据: 训练具有超长上下文能力的模型(如百万级)仍然非常昂贵,并且需要大量、多样化的高质量长文本数据。
5. 总结与展望
大语言模型上下文长度的扩展是过去几年中LLM领域最显著的进步之一。从早期RNN的几百词元,到Transformer初期的512-2048词元,再到通过稀疏注意力等技术探索的4K-16K词元,直至以FlashAttention为代表的I/O优化技术带来的32K、128K、200K词元的飞跃,以及当前最前沿的百万级词元上下文(如Gemini 1.5 Pro),我们见证了指数级的增长。
这些技术突破极大地拓展了LLM的应用场景。然而,挑战依然存在。未来,我们可以期待在更高效的注意力机制、更强的长程推理能力、多模态长上下文处理、以及专门优化的硬件等方面取得进一步突破,推动上下文长度的边界持续扩展,并更重要的是,提升模型对这些超长上下文的有效利用率。




