启动hdfs集群,打开hadoop100:9870,在wcinput目录下上传一个包含很多个单词的文本文件。
启动之后在spark-shell中写代码。
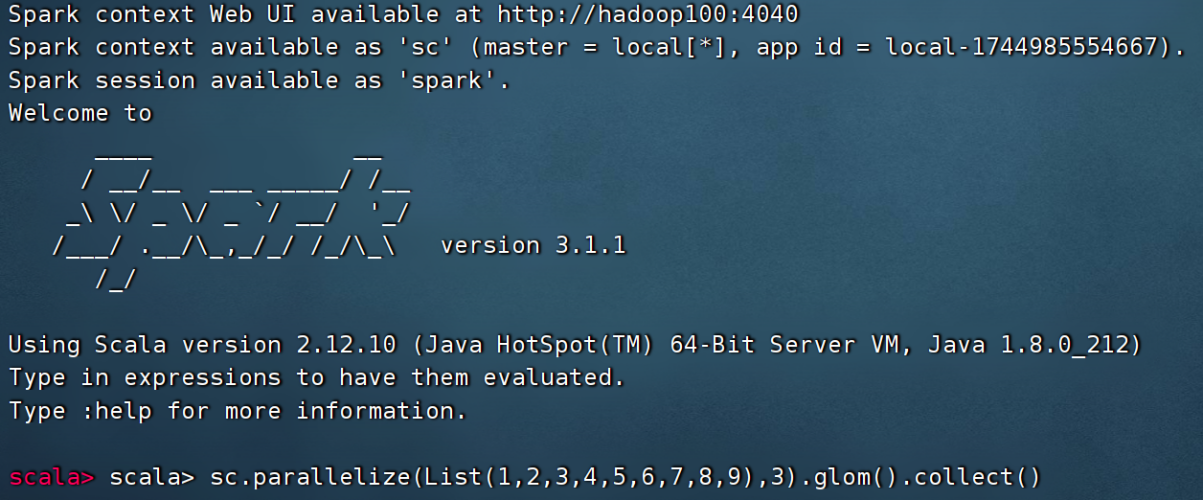
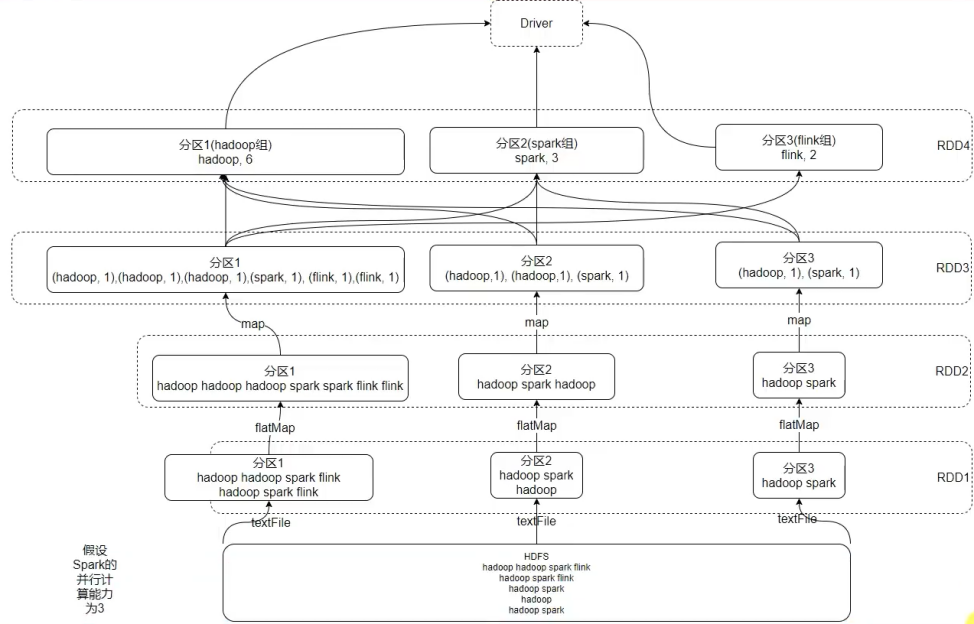
// 读取文件,得到RDD
val rdd1 = sc.textFile("hdfs://hadoop100:8020/wcinput/words.txt")
// 将单词进行切割,得到一个存储全部单词的RDD
val rdd2= fileRDD.flatMap(line => line.split(" "))
// 将单词转换为元组对象,key是单词,value是数字1
val rdd3= wordsRDD.map(word => (word, 1))
// 将元组的value按照key来分组,对所有的value执行聚合操作(相加)
val rdd4= wordsWithOneRDD.reduceByKey((a, b) => a + b)
// 收集RDD的数据并打印输出结果
rdd4.collect().foreach(println)

)
感知机)


