因为要做项目,实验室的服务器不联网,所以只能先打包一个基础的docker环境,然后再在实验室的服务器上进行解压和配置环境
参考:https://zhuanlan.zhihu.com/p/23377266873
1.打包基础的docker环境
这里最好用有cuda的,我选择跟服务器匹配的cuda环境,安装系统依赖的时候,最好安装一个curl,我搞忘了
# 使用带有CUDA支持的PyTorch官方镜像
FROM pytorch/pytorch:2.2.1-cuda12.1-cudnn8-runtime# 设置工作目录
WORKDIR /usr/src/app# 安装其他系统依赖
RUN apt-get update && apt-get install -y \openssh-server \vim \&& apt-get clean \&& rm -rf /var/lib/apt/lists/*# 3. 配置SSH服务
RUN mkdir /var/run/sshd && \echo 'root:123456' | chpasswd && \sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config && \sed -i 's/#PasswordAuthentication yes/PasswordAuthentication yes/' /etc/ssh/sshd_config
构建镜像
docker build -t ollama-llm .
docker run -it ollama-llm bash
打包镜像
docker ps -a //查看容器ID
docker commit 368369a3c853【查到的ID】 ubuntu:test
导出:docker image save ubuntu:test -o sl_sum.tar【名字】
2.下载需要在服务器上进行安装的资源:
下载大模型:我选择的是deepseek-1.5b的gguf模型
https://huggingface.co/roleplaiapp/DeepSeek-R1-Distill-Qwen-1.5B-Q2_K-GGUF/tree/main
下载https://github.com/ollama/ollama/releases/里面对应的ollama-linux-amd64.tgz
把这个上传到服务器指定位置
3.在服务器上进行配置
(1)移动、解压文件、权限配置:
//移动
mv ~/data1/lib/ollama-linux-amd64.tgz /usr/src/app/ollama
mv ~/data1/lib/deepseek-r1-distill-qwen-1.5b-q2_k.gguf /usr/src/app/ollama/models
//解压
在/usr/src/app/ollama# 这个路径下
tar -C /usr -xzf ollama-linux-amd64.tgz
//权限配置
chmod +x /usr/bin/ollama
useradd -r -s /bin/false -m -d /usr/share/ollama ollama
(2)配置ollama.service
命令:
vi /etc/systemd/system/ollama.service
ollama.service文件:
[Unit]
Description=Ollama Service
After=network-online.target[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
# 你模型的位置
Environment="OLLAMA_MODELS=/usr/src/app/ollama/models"
# 你要从外面调用服务器的模型一定要设置为这个
Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
(3)启动服务
## 启动Ollama服务
ollama serve
要注意:
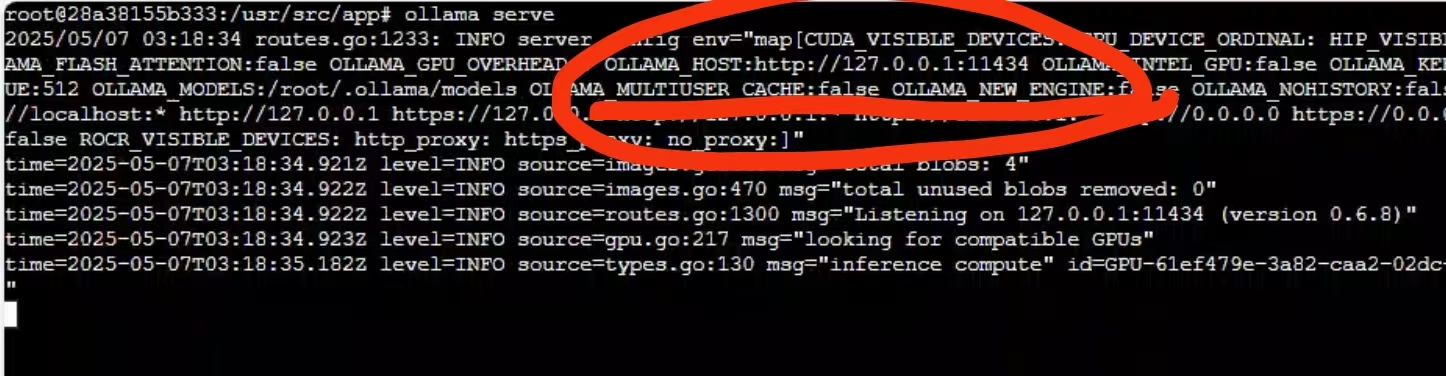
这里如果是127.0.0.1,本地是连不上服务器的
再打开前记得配置一下:
export OLLAMA_HOST=0.0.0.0:11434
再进行ollama serve,如果显示0.0.0.0:11434,就对了。
(4)配置模型:
创建Modelfile文件:
//在/models,这里面我放了ds的gguf模型
//创建Modelfile文件,跟模型一个文件夹 /usr/src/app/ollama/models#
vim deepseek.Modelfile
写入Modelfile文件,可以自定义输出格式:
# 这里的名字,跟你模型要一样
FROM ./deepseek-r1-distill-qwen-1.5b-q2_k.gguf
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
"""
SYSTEM """
你是一个乐于助人的助手,你需要用正经的风格去回答问题。
"""
4.开启服务
(1)在容器中:
//在/models
//格式:ollama create (name) -f (Modelfile地址)
ollama create deepseek:1.5b -f ./deepseek.Modelfile
使用模型:
ollama run deepseek:1.5b "请用几句话写一个中文笑话"
(2)在本地调用
## 启动Ollama服务
ollama serve
在本地打开一个cmd
curl http://10.20.26.187:11434/api/generate -d '{"model": "deepseek:1.5b","prompt": "请简单介绍自己","stream": true #是否采用流式输出
}'
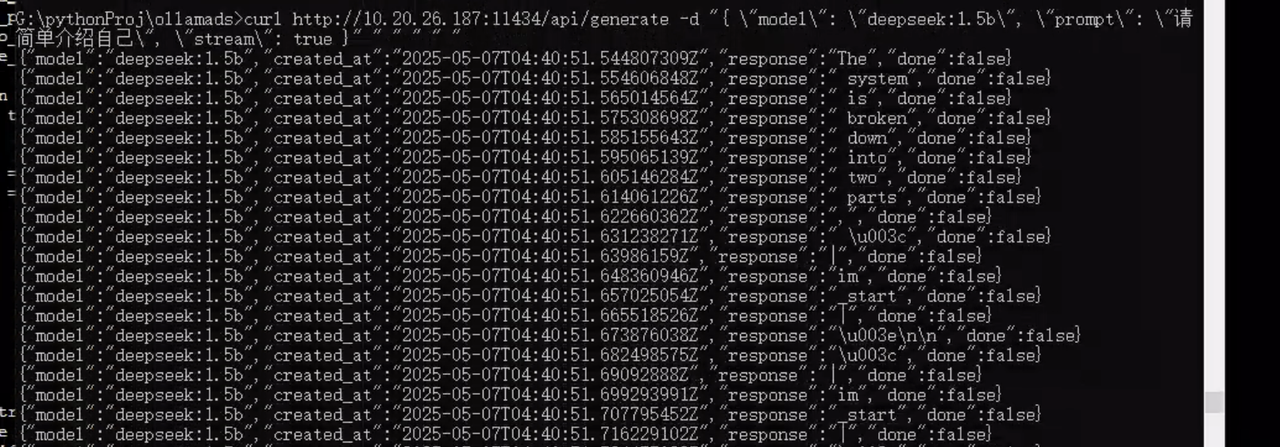

)
感知机)


