1.CLIP的textEncoder能输入多少个单词?
CLIP 模型中的 context_length 设置为 77,表示每个输入句子会被 tokenized 成最多 77 个token。这个 77 并不是直接对应到 77 个单词, 因为一个单词可能会被拆分成多个 token,特别是对于较长的或不常见的单词。
在自然语言处理中,token 通常指的是模型在处理文本时的最小单位,可以是单个词,也可以是词的一部分或多个词的组合。 这是因为 CLIP 模型使用了 Byte-Pair Encoding (BPE) 分词器,这种方法会将常见的词作为单个 token,但会把不常见的词拆分成多个 token。
实际例子
为了更好地理解,我们来看一个具体的例子:
import clip# 加载模型
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device)# 示例句子
text = "a quick brown fox jumps over the lazy dog."# 对句子进行 tokenization
tokenized_text = clip.tokenize([text])print(tokenized_text)
print(tokenized_text.shape)
在这个例子中,我们对句子 "a quick brown fox jumps over the lazy dog." 进行了 tokenization。让我们看看它的输出:
tensor([[49406, 320, 1125, 2387, 539, 1906, 315, 262, 682, 1377,269, 49407, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0]])
torch.Size([1, 77])
在这个例子中,句子被转换成了 77 个 token ID,其中包含了句子的 token ID 和填充的零。句子的 token 包括起始和结束的特殊 token (49406 和 49407), 剩余的空位用 0 进行填充。
可以看到,虽然句子有 9 个单词,但经过 tokenization 后得到了 11 个 token(包括起始和结束 token),加上填充后的长度为 77。
总结
- context_length 设置为 77 表示模型的输入长度限制为 77 个 token。
- 77 个 token 不等同于 77 个单词,因为一个单词可能会被拆分成多个 token。
- 实际的单词数量会少于 77 个,具体取决于句子的复杂度和分词方式。
- 通常情况下,77 个 token 可以容纳大约 70 个左右的单词,这取决于句子的内容和复杂度。
为了在实际应用中得到精确的单词数量与 token 数量的关系,可以对输入文本进行 tokenization 并观察其输出。通过这种方式,可以更好地理解模型的输入限制。
2.比较BERT和GPT-3的模型结构,并分析它们在语言理解和生成任务上的差异?
BERT模型结构:
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer的预训练语言处理模型,它主要由多层Transformer编码器组成。这种结构使得BERT在编码过程中具有独特的优势,即每个位置都能获得所有位置的信息,包括历史位置的信息。这种双向编码的能力使得BERT在理解和处理自然语言方面表现出色。
BERT模型由输入层、编码层和输出层三部分组成。输入层负责将文本数据转换为模型可以理解的格式,编码层则由多层Transformer编码器组成,负责对输入的文本进行深层次的特征提取和编码。最后,输出层则根据不同的任务需求,输出相应的预测结果。
在预训练阶段,BERT模型的最后有两个输出层,分别是掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)。掩码语言模型的目的是预测被掩码的单词,这迫使模型学习单词之间的关系和上下文信息。下一句预测则旨在预测两个句子是否在原始文本中是连续的,这有助于模型理解句子之间的逻辑关系。
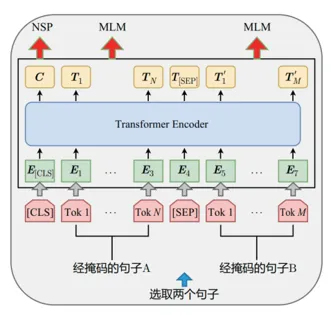
BERT 模型的输入表示主要包括三个部分: Token Embedding、 Segment Embedding 和Position Embedding。其中, Token Embedding 用于表示每个单词的向量表示, Segment Embedding 用于区分不同句子的输入, Position Embedding 用于表明每个单词在句子中的位置。
GPT3模型结构:
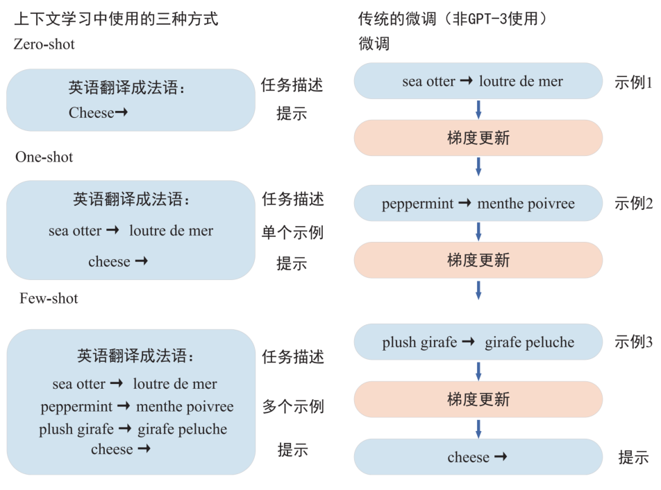
GPT-3 是一个自回归语言模型,沿用了 GPT-2 的结构,在网络容量上有很大的提升,采用了96 层的多头 Transformer,词向量维度为 12,288,共有 1,750 亿个参数,是 GPT-2 的 100 多倍。在给出任务的描述和一些参考案例的情况下, GPT-3 模型能根据当前的任务描述、参数案例理解当前的语境,即使在下游任务和预训练的数据分布不一致的情况下,模型也能表现得很好。 GPT-3 并没有进行微调,在计算子任务的时候不需要计算梯度,而是让案例作为一种输入的指导,帮助模型更好地完成任务。
GPT-3 使用三种方式来评测所有的任务,包括 Few-shot、 One-shot 和 Zero-shot。这三种方式与原本的微调最大的不同,在于是否改变模型的参数。微调会在学习样本的过程中,不断调整自身模型的参数,而 GPT-3 的几种方式,则完全不会调整模型的参数,这也是一个模型能够处理所有任务的基础。
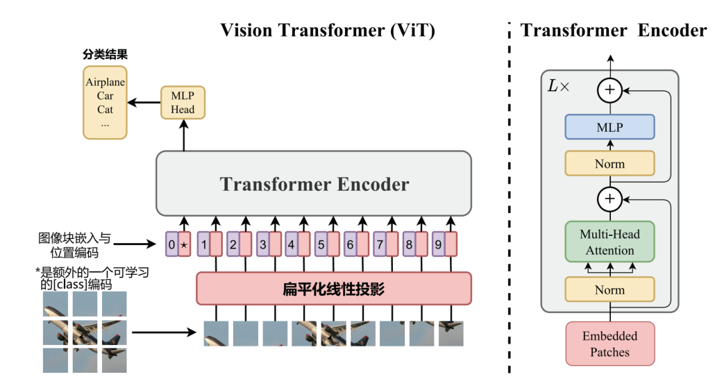
3.解释ViT和MAE的区别,并说明它们在图像特征提取方面的优势?
ViT 将图像分成一个个小的图像块 (Patch),然后将每个图像块进行扁平化处理,得到一个序列。接着,将序列输入 Transformer 编码器中,通过多个 Transformer 编码器层学习图像中的特征表示。最后,使用一个全连接层将编码器的输出映射到类别标签。
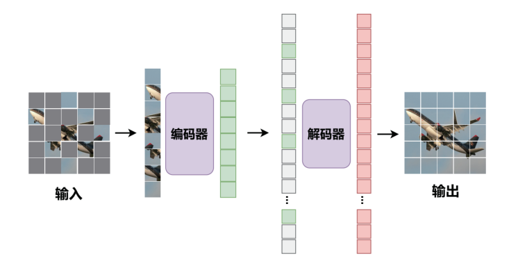
MAE 是一个非对称的编码器-解码器 (Encoder-Decoder) 结构的模型,编码器结构采用了 ViT 提出的以 Transformer 为基础的骨干网络,解码器是一个轻量级的结构,在深度和宽度上都比编码器小很多。MAE 的解码器将整个图像的图像块(掩码标志和编码器编码后的未被掩码图像块的图像特征)作为输入。
4.什么是模态编码器在AI多模态大模型中的作用?
模态编码器主要任务是将来自不同模态的输入数据(如图像、音频、视频)转换成模型可以理解和处理的特征表示。通过模态编码器,模型能够捕捉到每种模态的独特信息,并将这些信息整合在一起,以实现更全面和准确的分析和决策。
5.CLAP模型是如何通过对比学习进行音频表示学习的?
CLAP(Contrastive Language-Audio Pretraining)是一种基于对比学习的预训练方法,旨在通过结合音频数据和相应的自然语言描述来学习音频的表示。CLAP的核心思想是利用对比学习范式,将音频和文本映射到一个共享的潜在空间中,并通过训练使得相关的音频-文本对在该空间中更接近,而不相关的对更远离。这种方法有助于学习到更具语义意义的音频表示。




