目录
0.前言
1.FileReader
1.1 概述
1.2 构造方法
1.3 成员方法
1.4 FileReader读取文件案例演示
1.4.1 文本内容只有BMP字符
1.4.2 文本内容包含辅助平面字符
2.FileWriter
2.1 概述
2.2 自带缓冲区
2.3 构造方法
2.4 成员方法
2.5 FileWriter写入文件案例演示
2.5.1 使用 public FileWriter(String filename) + write (int c)
2.5.2 使用 public FileWriter(String filename,boolean append) + write (int c)
2.5.3 使用 public FileWriter(String filename,boolean append) + write (String str)
2.5.4 使用 public FileWriter(String filename) + write (char[ ] cbuf)
2.6 关于flush(刷新)
3.FileReader+FileWriter拷贝文本文件
3.1 拷贝步骤
3.2 案例演示
3.2.1 以单个字符拷贝(不推荐)
5.2.2 以字符数组拷贝(更常用)
0.前言
本文讲解的是两个比较重要的节点流,也是两个比较重要的字符流。即字符输入流 FileReader、字符输出流 FileWriter
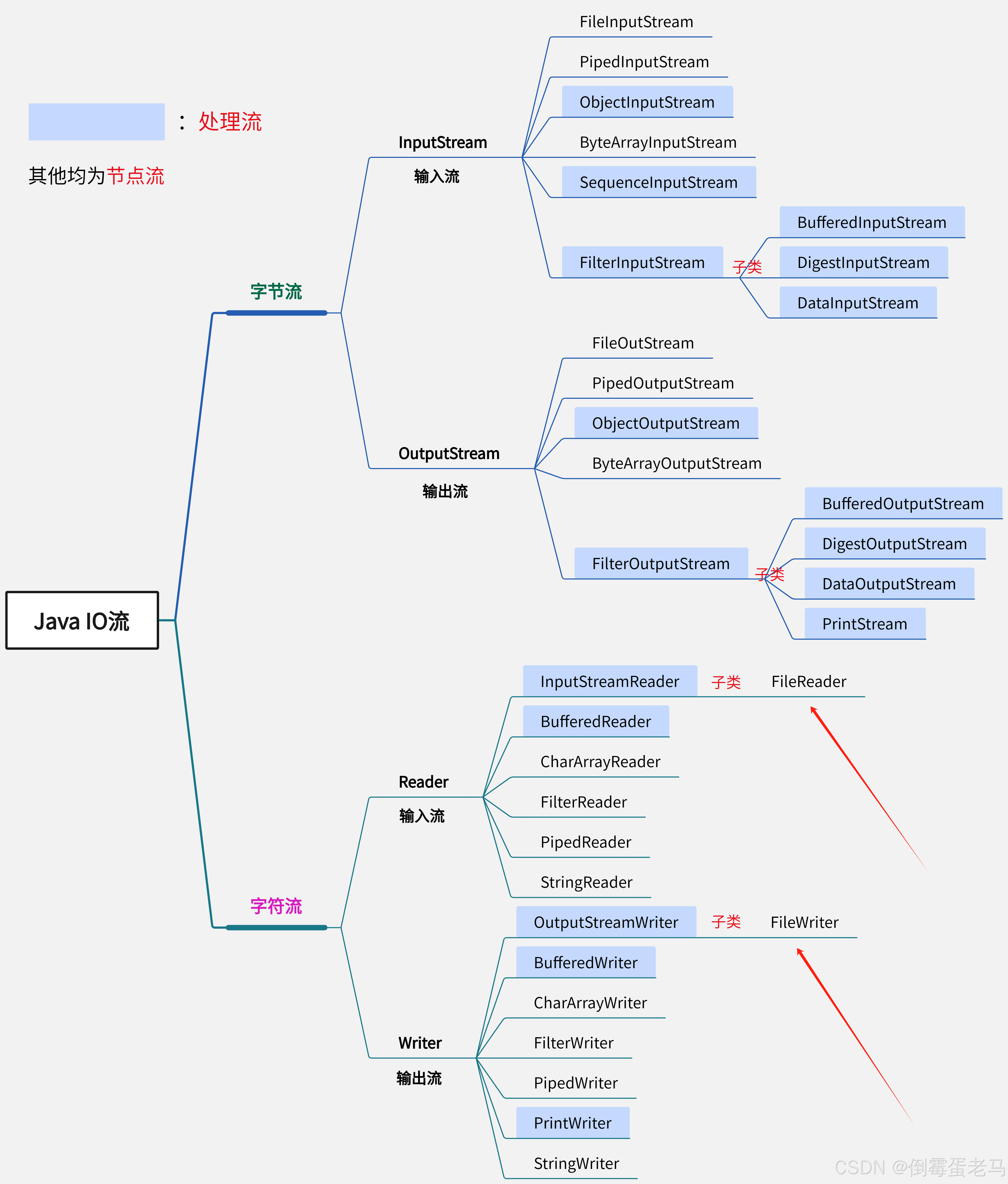
Java IO 流体系图如下:
1.FileReader
1.1 概述
作用:将磁盘文本文件的数据读取到 Java 程序(内存)中

1.2 构造方法
FileReader 有 2 个常用的构造方法,如下:
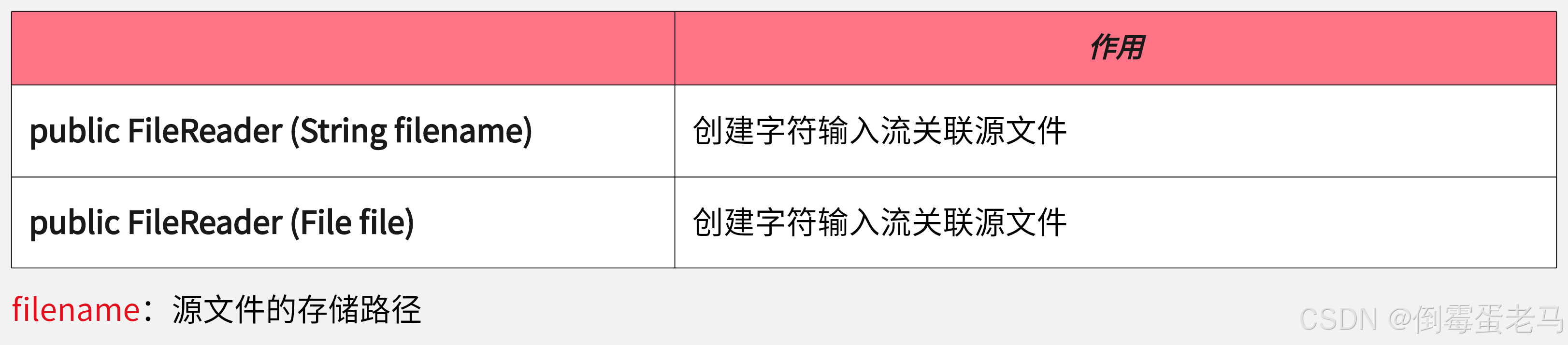
源文件即我们要读取的磁盘文件。关于第 2 个构造器 public FileReader(File file) 的形参 File,看过 File 类基础的都知道 File 实例其实就代表一个文件对象
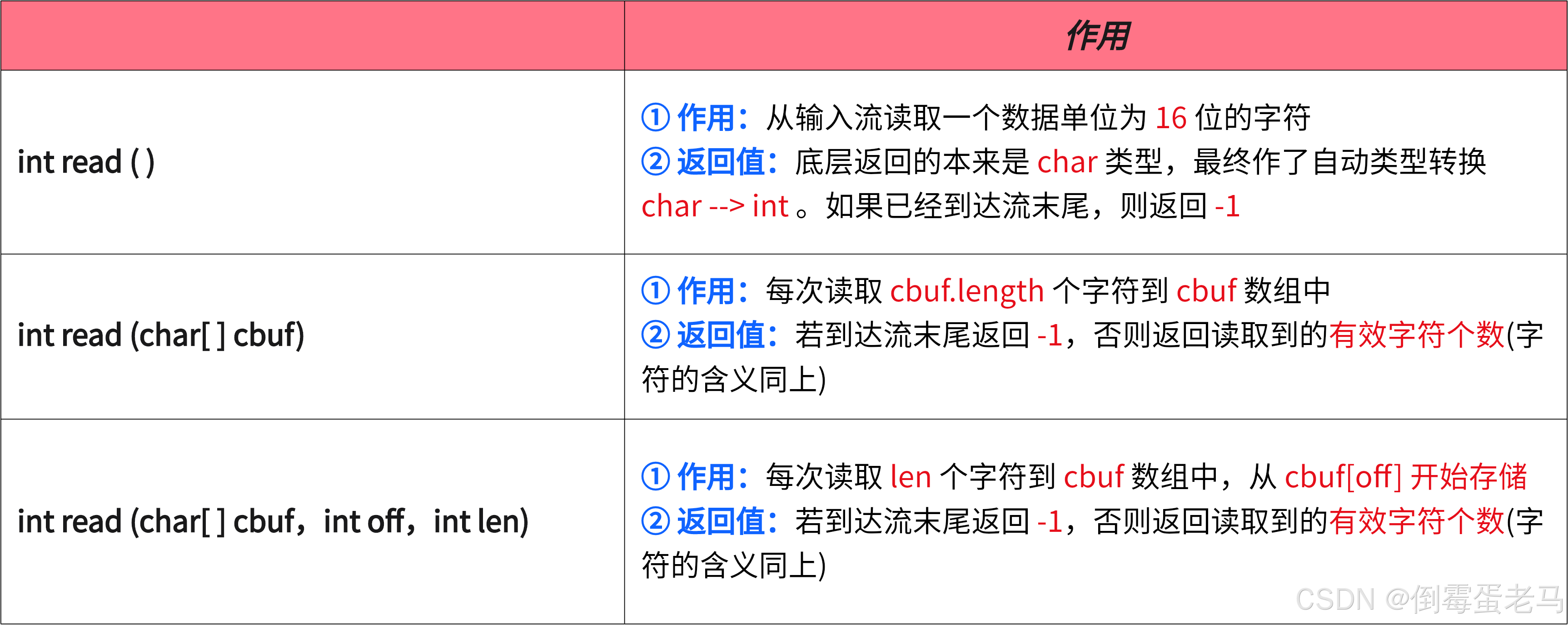
1.3 成员方法
3 个 read 方法都继承于 FileReader 的直接父类 InputStreamReader 。对输入流源文件的解码方式使用的是 IDE 默认的编码方式,IDEA 默认的编码方式是:UTF-8,这里就以 IDEA 默认的编码方式来讲解
① read() 方法的底层:在 Java 中的 char 类型是 16 位无符号整数类型,采用 UTF-16 BE 编码。现在我们以 IDEA 默认的编码方式为 UTF-8 ,文本文件采用 UTF-8 编码为前提,在读取文本文件的时候会先将文本文件底层存储的 UTF-8 编码内容正确转换为 UTF-16 BE 编码方式,然后再用 read() 方法每次读取一个数据单位为 16 位 的字符到 JVM 内存中
FileReader + read() 读取文本文件的流程如下图所示:
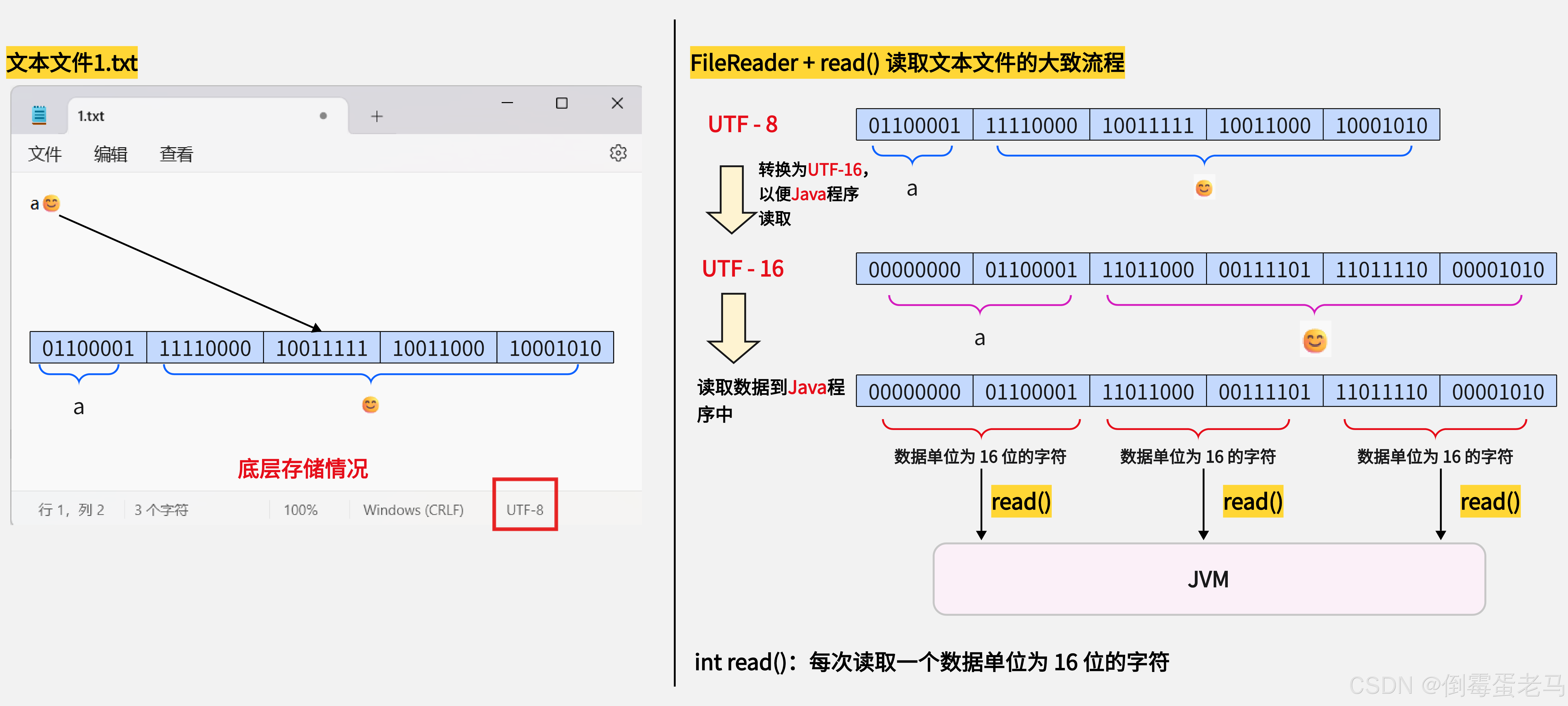
因为辅助平面字符需要用 2 个 char 存储,所以如果文本中包含辅助平面字符的话,只能先读取到其高位代理,再读取其低位代理
说明:对于 read(char[ ] cbuf)、read(char[ ] cbuf,int off,int len) 的底层实现是类似的,这里就不再赘述了
② 每次调用 read(char[ ] cbuf) 、read(char[ ] cbuf,int off,int len) 时,会用从文本文件中读取到的新字符覆盖 cubf 字符数组中相同位置的旧字符。另外在读取到接近文件末尾的时候,有可能读取的新字符个数 < cubf.length,所以返回值是 "读取到的有效字符个数" 。这么看可能还是有点抽象,后面会举具体的案例
③ read() 每次只能读取一个数据单位为 16 位的字符,速度较慢。通常情况下使用 read(char[ ] cbuf) 更多,一次可以读取多个字符
1.4 FileReader读取文件案例演示
1.4.1 文本内容只有BMP字符
案例1:使用 read() 读取文本文件内容到 Java 程序
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\1.txt,该文本文件使用 UTF-8 编码方式,文本内容是 "csdn" ,只有 BMP 字符。具体如下:
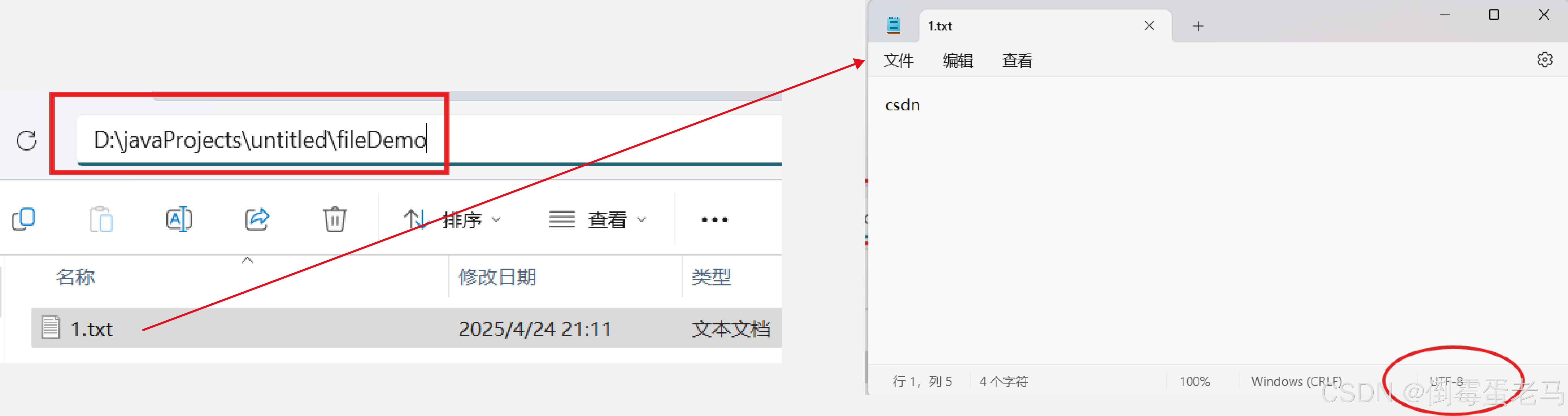
代码如下:
import java.io.*;
public class demo {public static void main(String[] args) throws IOException {//1.创建字符输入流FileReader对象,关联数据源文件 1.txtReader reader = new FileReader("D:\\javaProjects\\untitled\\fileDemo\\1.txt");/* 也可以用另一个构造器方法创建FileReader:Reader reader = new FileReader(new File("D:\\javaProjects\\untitled\\fileDemo\\1.txt"));*///2.定义变量,记录读取到的内容int data;//3.循环调用 read 方法读取数据,只要还未到文件末尾就一直读,并将读取到的内容赋值给变量while ((data = reader.read()) != -1) {System.out.println(data);}//4.释放流资源,避免内存泄漏reader.close();}
}运行结果:
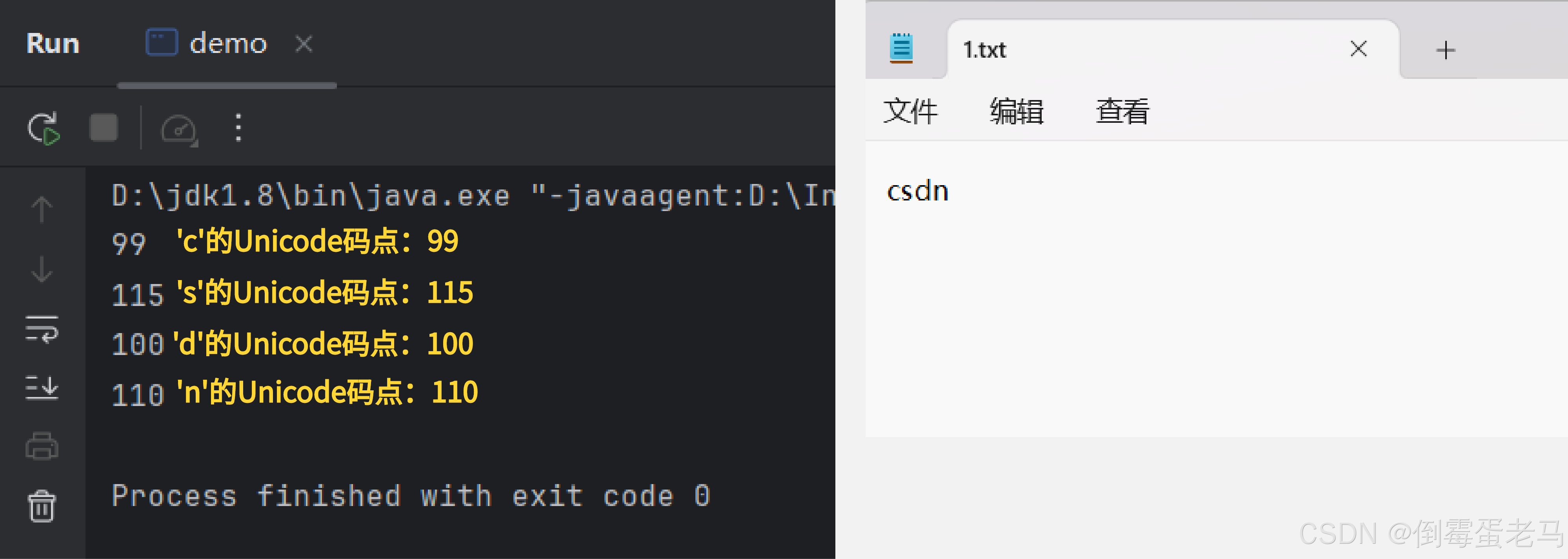
可以看到,控制台上打印出的内容正确对应了 "csdn" 的 Unicode 码点
注意:int read() 的方法返回的本应该是字符经过 UTF-16 编码之后的十进制值,不过因为在 UTF-16 编码中,BMP 字符都是直接将码点转换为二进制然后用 2 个字节存储即可,所以编码值的十进制形式和码点的十进制形式是一致的
如果想要原封不动的把读取到的 BMP 字符显示在控制台上,可以将返回的编码值转换为 char 类型,如下:
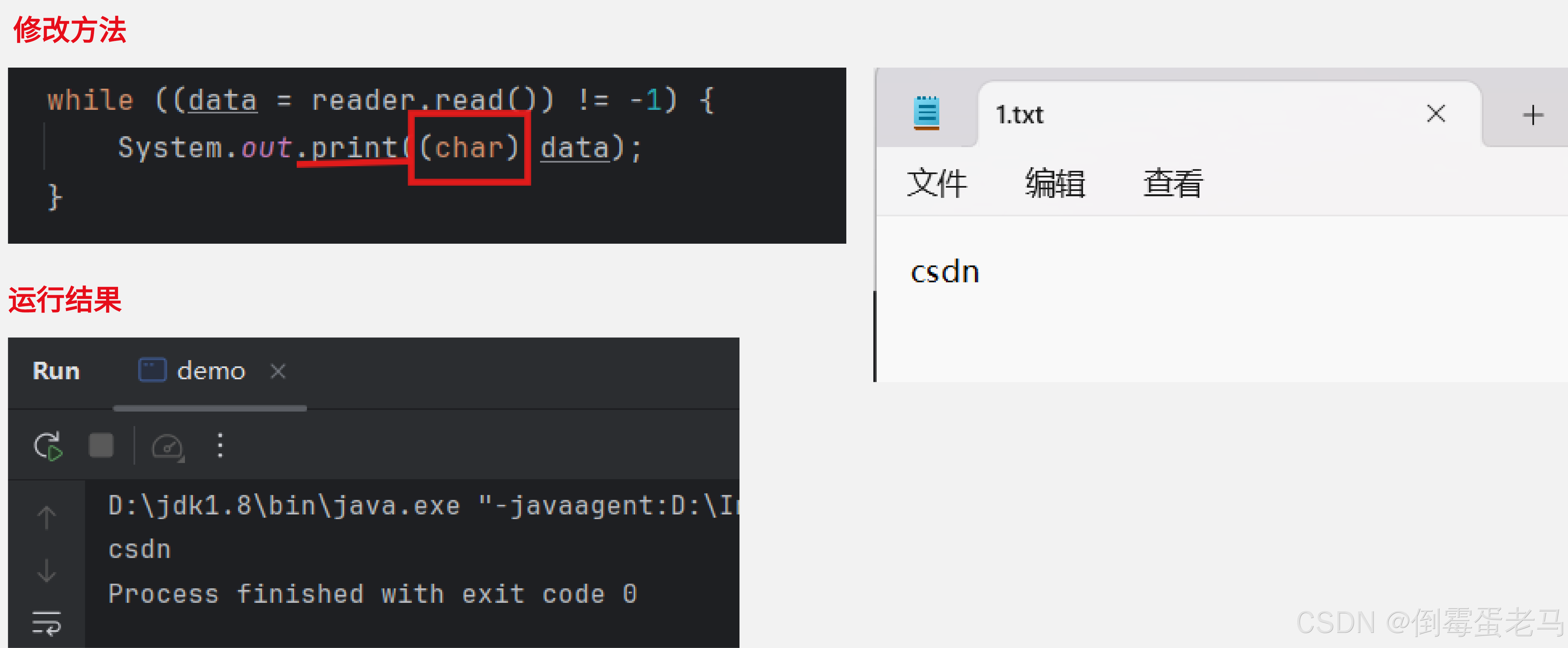
案例2:使用 read(char[] cbuf) 读取文本文件内容到 Java 程序
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\2.txt,该文本文件使用 UTF-8 编码方式,文本内容是 "abcd蔡徐坤",只有 BMP 字符。具体如下:
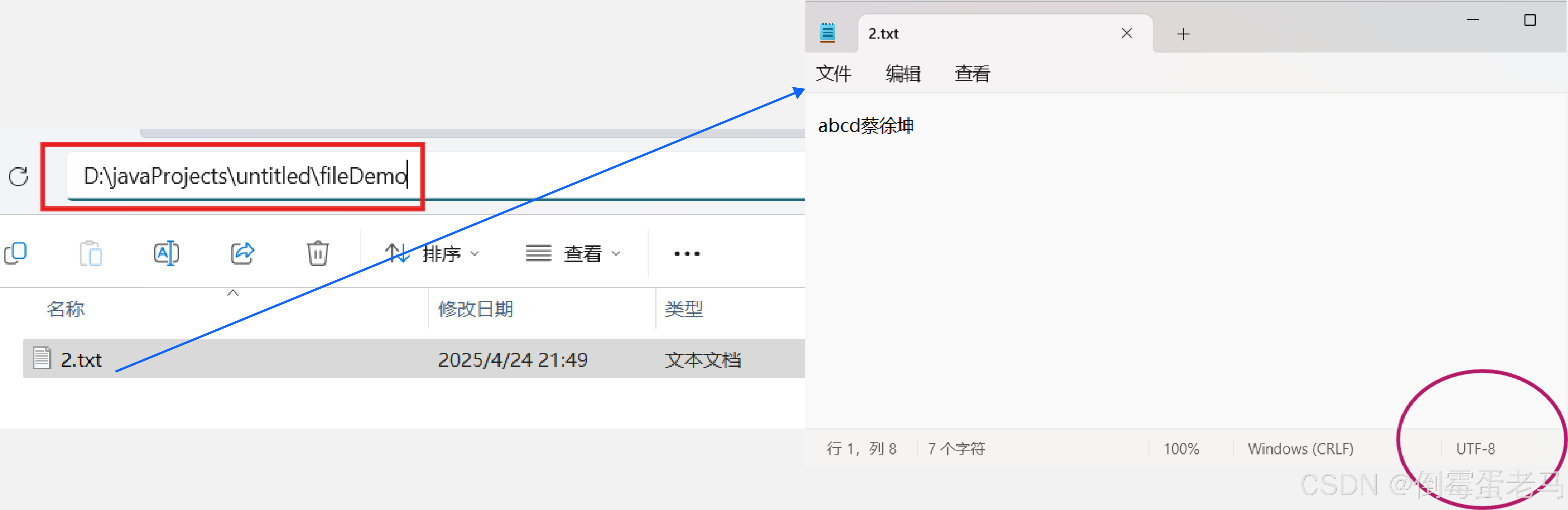
代码如下(注释同样重要噢):
import java.io.*;
import java.util.Arrays;
public class demo {public static void main(String[] args) throws FileNotFoundException, IOException {//1.创建字符输入流FileReader对象,关联数据源文件 2.txt(建议第一步就抛出父类异常IOException)FileReader reader = new FileReader(new File("D:\\javaProjects\\untitled\\fileDemo\\2.txt"));//2.定义字符数组cbuf,记录读取到的内容char[] cbuf = new char[2]; //定义一个长度为2的字符数组,表示每次从流中读取2个数据单位为16位的字符//3.调用 int read(char[] cbuf) 读取文本文件的内容//第一次读取,有效字符个数 i1 = 2,'a'、'b'int i1 = reader.read(cbuf);System.out.println("第一次读取后的cbuf内容:"+ Arrays.toString(cbuf)+" 读取到的有效字符个数:"+i1);System.out.println("--------------------------");//第二次读取,有效字符个数 i2 = 2,'c'、'd'int i2 = reader.read(cbuf);System.out.println("第二次读取后的cbuf内容:"+ Arrays.toString(cbuf)+" 读取到的有效字符个数:"+i2);System.out.println("--------------------------");//第三次读取,有效字符个数 i3 = 2,'蔡'、'徐'int i3 = reader.read(cbuf);System.out.println("第三次读取后的cbuf内容:"+ Arrays.toString(cbuf)+" 读取到的有效字符个数:"+i3);System.out.println("--------------------------");//第四次读取,有效字符个数 i4 = 1,'坤'int i4 = reader.read(cbuf);System.out.println("第四次读取后的cbuf内容:"+ Arrays.toString(cbuf)+" 读取到的有效字符个数:"+i4);System.out.println("--------------------------");/*总结:int read(char[] cbuf)每次都是用读取到的新字符覆盖cbuf相同位置的旧字符所以可以看到在第四次用调用read(char[] cbuf)后,输出结果为[坤,徐],读取到的有效字符个数i4 = 1,即其实第四次读取只读到了'坤'1个字符,'徐'是上一次读取到的结果,没有被覆盖噢*///4.释放流资源reader.close();}
}输出结果:
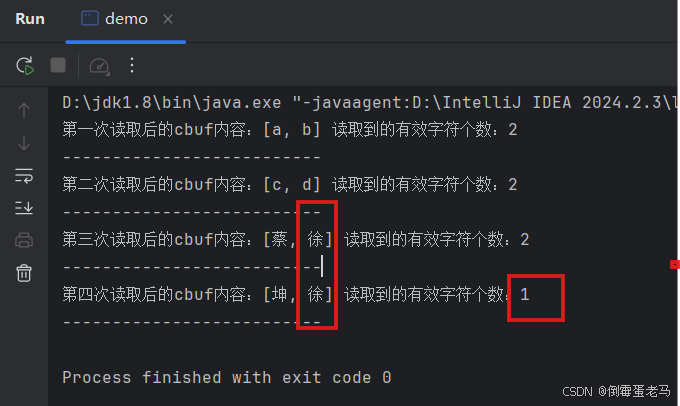
案例3:优化案例2的代码
import java.io.*;
public class demo {public static void main(String[] args) throws FileNotFoundException, IOException {//1.创建字符输入流FileReader对象,关联数据源文件 2.txt(建议第一步就抛出父类异常IOException)FileReader reader = new FileReader(new File("D:\\javaProjects\\untitled\\fileDemo\\2.txt"));//2.定义字符数组cubf,记录读取到的内容char[] cbuf = new char[2]; //定义一个长度为3的字符数组,表示每次从流中读取2个字符int count;//记录每次读取到的有效字符个数//3.循环读取,只要还未到文件末尾就一直读,并将读取到的内容保存在字符数组cbufwhile ((count = reader.read(cbuf)) != - 1){//String(char value[], int offset, int count):将cbuf中offset索引处开始的count个字符转换为字符串String charString = new String(cbuf, 0, count);System.out.print(charString);//输出流编码}//4.释放流资源,避免内存泄漏reader.close();}
}运行结果:
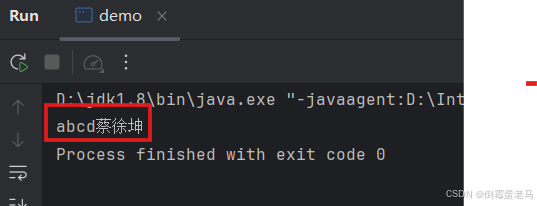
1.4.2 文本内容包含辅助平面字符
案例1:使用 read() 读取文本文件内容到 Java 程序
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\4.txt,该文本文件使用 UTF-8 编码方式,文本内容是 "😊",😊为辅助平面字符。具体如下:
🆗,我们先看一下下面这段代码会打印什么结果:
import java.io.*;
public class demo {public static void main(String[] args) throws IOException {//1.创建字符输入流FileReader对象,关联数据源文件 4.txtReader reader = new FileReader("D:\\javaProjects\\untitled\\fileDemo\\4.txt");//2.定义变量,记录读取到的内容int data;int i = 1;//3.循环调用 read 方法读取数据,只要还未到文件末尾就一直读,并将读取到的内容赋值给变量while ((data = reader.read()) != -1) {System.out.println("第"+i+"次读取:"+data);i++;}//4.释放流资源,避免内存泄漏reader.close();}
}运行结果:
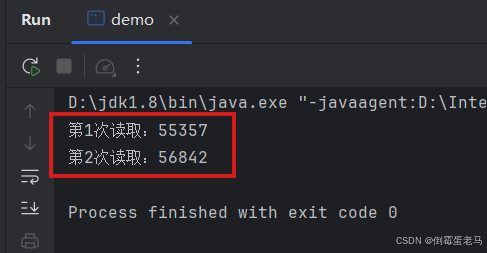
很多人看到运行结果懵逼了,欸不对啊,为什么明明就 "1个字符" 却执行了两次 read() 呢? 原因: 😊 是 Unicode 字符集的辅助平面字符,经过 UTF-16 编码之后得到的内容需要用 4 字节 = 32 bit 存储,第一个字节存放高位代理,第二个字节存放低位代理。而 read() 每次读取的是一个数据单位为 16 位的字符,因此执行了两次 read() ,第一次读取到的是😊高位代理的十进制值,第二次读取到的是😊低位代理的十进制值
劈里啪啦说了一堆,还是用流程图来解释一下:
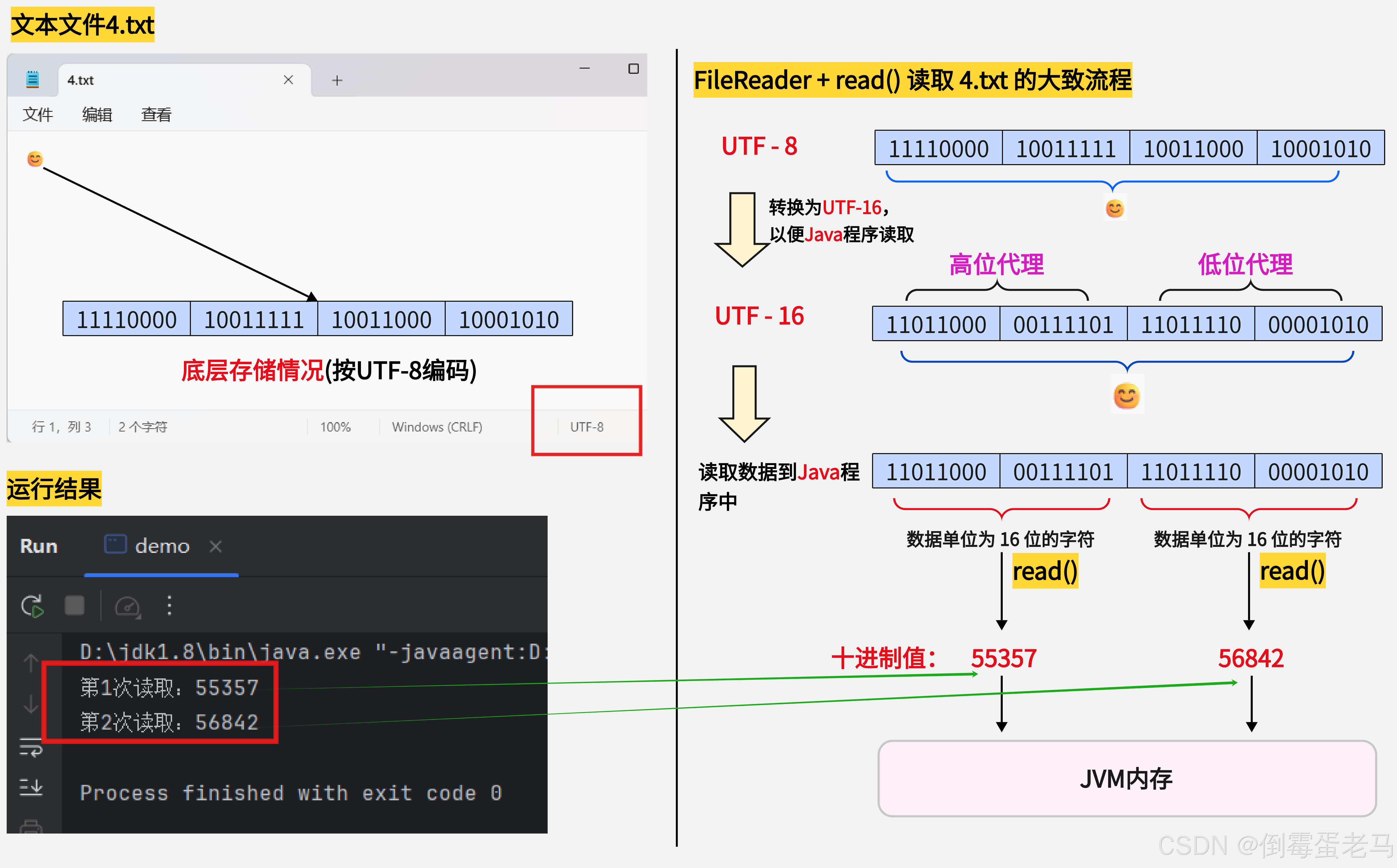
🆗,这下知道为啥第一次调用 int read() 返回 55357,第二次调用 int read() 返回 56842 了吧?
案例2:使用 read(char[ ] cbuf) 读取文本文件内容到 Java 程序
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\4.txt,该文本文件使用 UTF-8 编码方式,文本的内容如下:
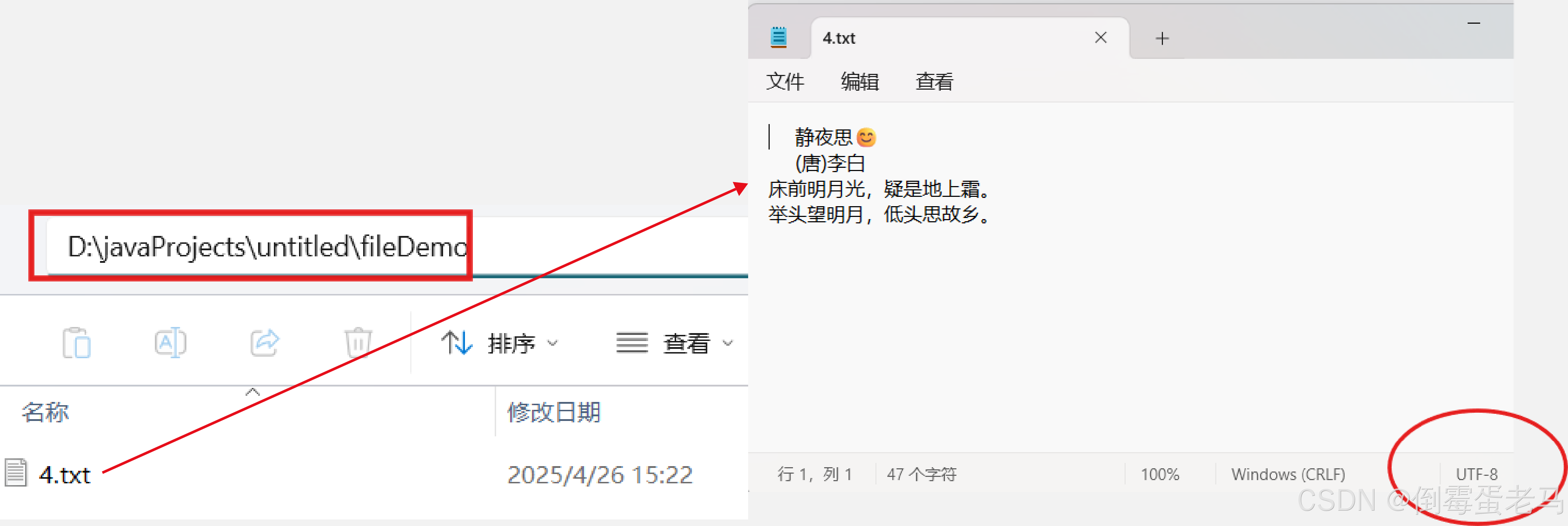
演示类完成的任务是:将 4.txt 中的内容正确读取,并显示在控制台上
代码如下:
import java.io.*;
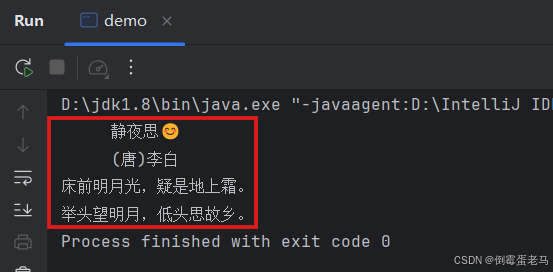
public class demo {public static void main(String[] args) throws Exception {//1.创建字符输入流FileReader对象,关联数据源文件 4.txtFileReader reader = new FileReader(new File("D:\\javaProjects\\untitled\\fileDemo\\4.txt"));//2.定义字符数组cubf,记录读取到的内容char[] cbuf = new char[5];//定义一个长度为10的字符数组,表示每次从流中读取10个数据单位为16位的字符int count;//记录每次读取到的有效字符个数//3.循环读取,只要还未到文件末尾就一直读,并将读取到的内容保存在字符数组cbufwhile ((count = reader.read(cbuf)) != - 1){//String(char value[], int offset, int count):将cbuf中offset索引处开始的count个字符转换为字符串String charString = new String(cbuf, 0, count);System.out.print(charString);//输出流编码}//4.释放流资源,避免内存泄漏reader.close();}
}运行结果:
2.FileWriter
2.1 概述
作用:将 Java 程序(内存)中的字符写入到磁盘文件中

2.2 自带缓冲区
普通的字符输出流本身就自带缓冲区(字符输入流好像没有),包括 FileWriter。我们可以溯源一下,查看所有字符输出流的基类 Writer ,如下:
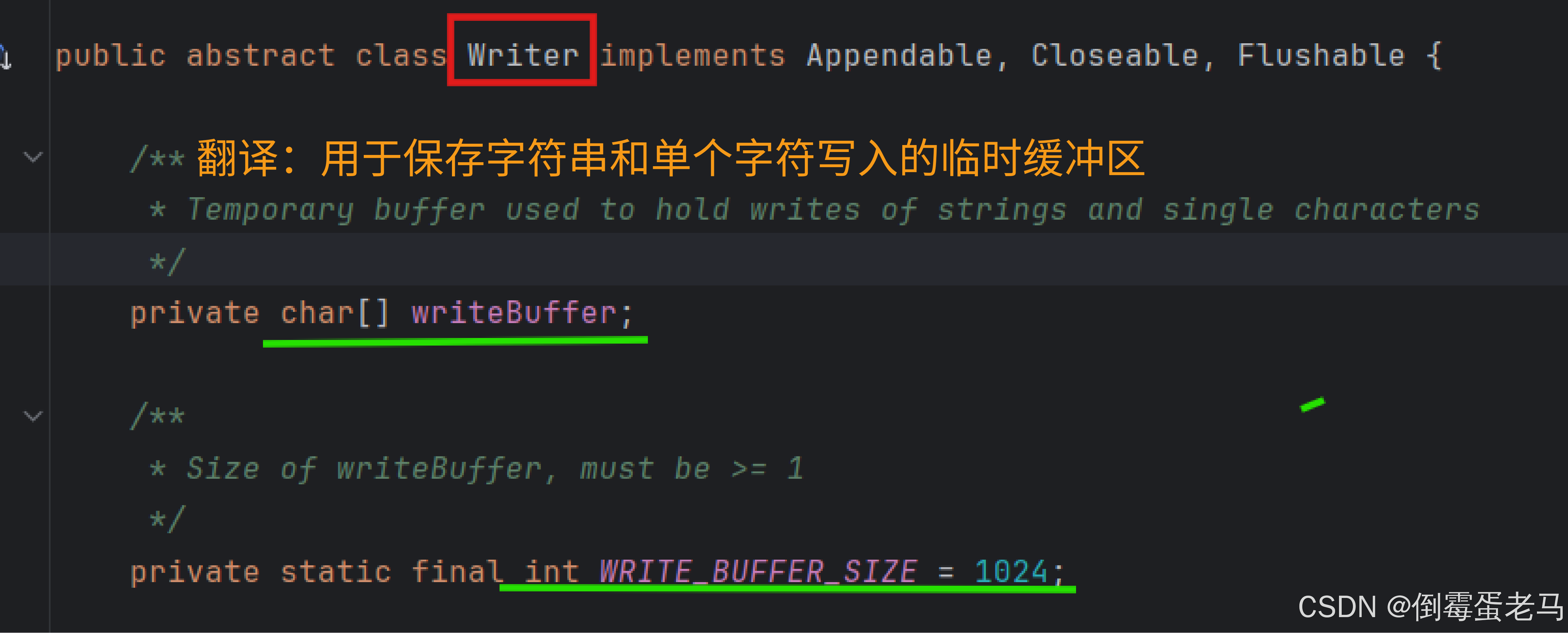
可以看到,字符输出流自带的缓冲区是一个长度为 1024 的 char 类型数组 writeBuffer
缓冲区的作用如下图所示:
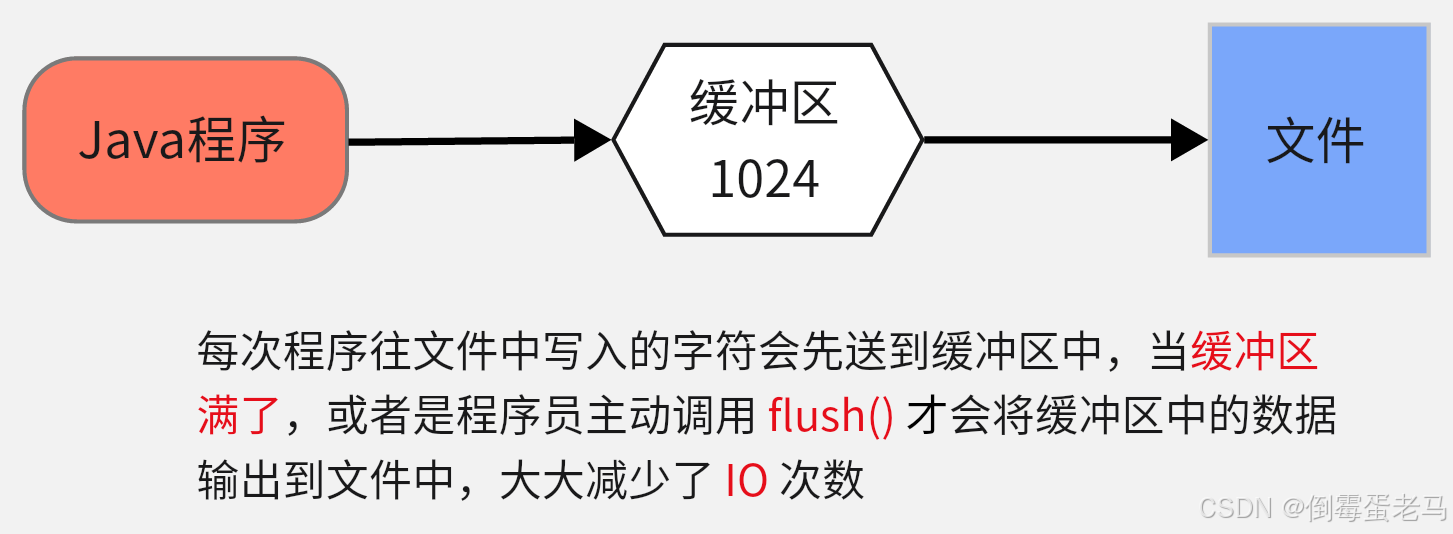
由于程序与磁盘的交互速度是比较慢的,容易称为程序的性能瓶颈,因此减少 IO 次数可以提高字符数输出流的写入速度
如果还是不太能理解缓冲区的作用的话,我举一个生活中的例子:
我们搬砖的时候,一块一块地往车上装肯定是很低效的。我们可以使用一个小推车,先把砖头装到小推车上,等到小推车被砖头堆满的时候,就把这个小推车推到车前,把砖头装到车上。这个例子中,小推车可以视为缓冲区,小推车的存在,减少了我们装车次数(类比 IO 次数),从而提高了效率

2.3 构造方法
FileWriter 中 4 个常用的构造方法,如下:
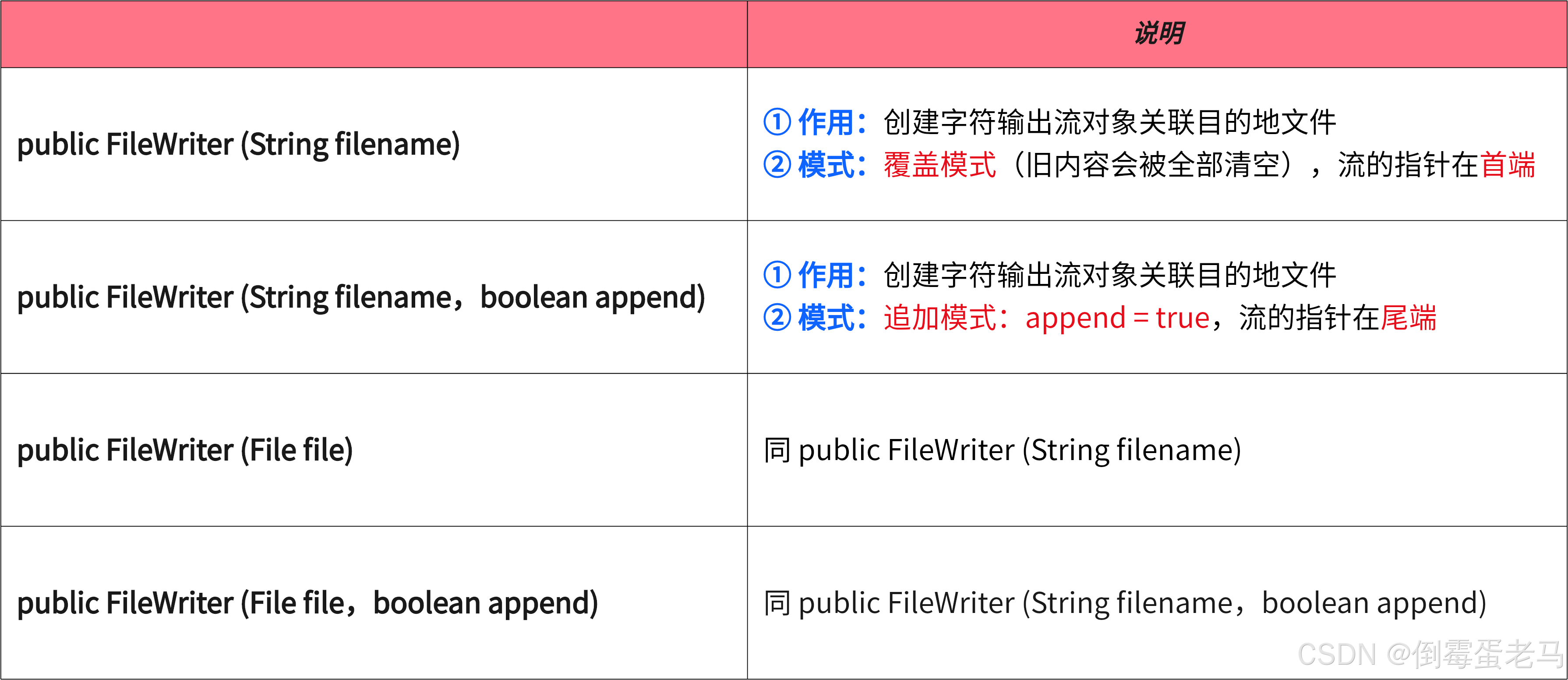
PS:如果目的地文件不存在,使用 FileWriter 构造器方法后会在磁盘上生成该文件,但要保证父级目录是存在的
2.4 成员方法
成员方法都继承自 FileWriter 的直接父类 OutputStreamWriter
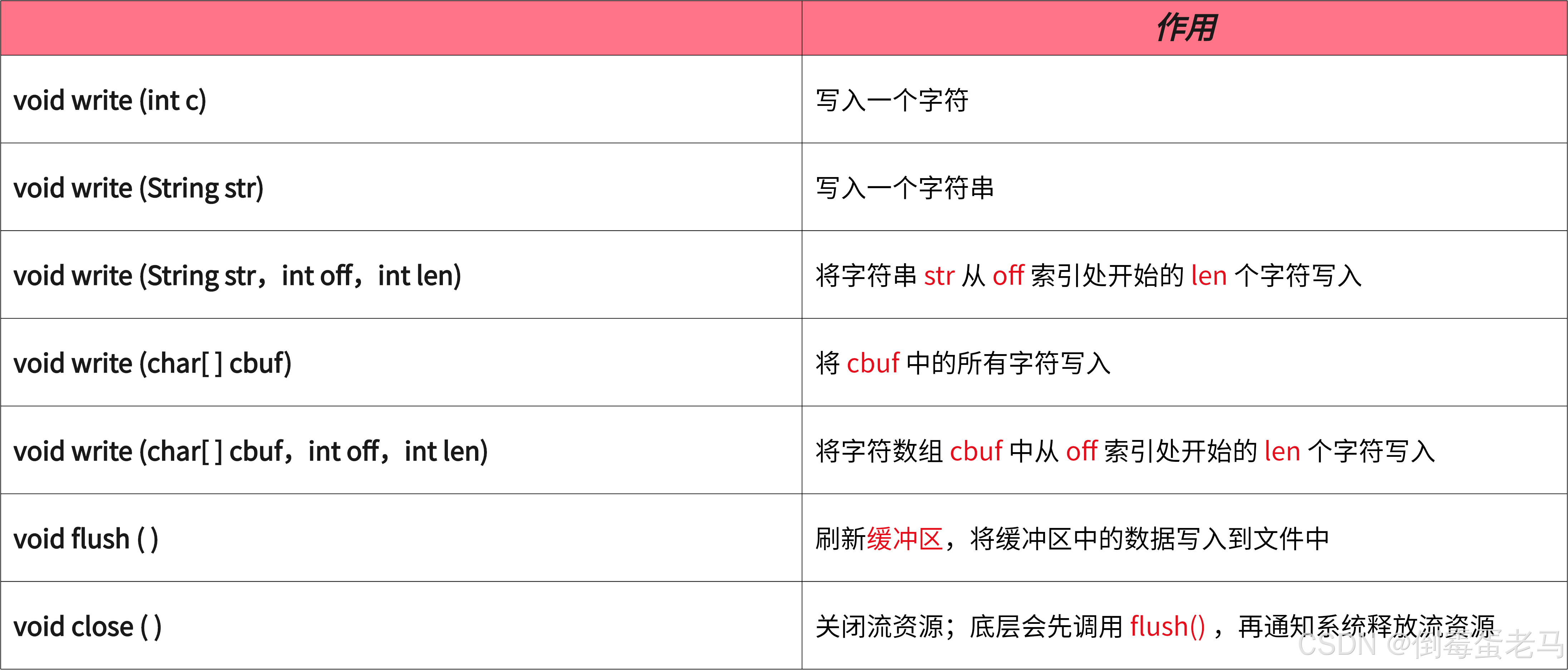
① 第一行的 void write (int c) 会将传入的 int 类型在底层强制转换成 char 类型(2个字节),如下:

即该 wirte 方法每次只能用写入一个数据单位为 16 位的字符。因此对于 BMP 字符调用 1 次 write(int c) 即可写入,对于辅助平面字符需要调用 2 次 write(int c) 分别传入高位代理、低位代理才能完成写入。后续会举例子
② FileWriter + write 会以开发工具的默认编码方式对写入文件的字符进行编码,再保存到文件中。IDEA 的默认编码方式是 UTF-8,Java 的 char 类型的编码方式是 UTF-16 BE ,不要搞混了噢
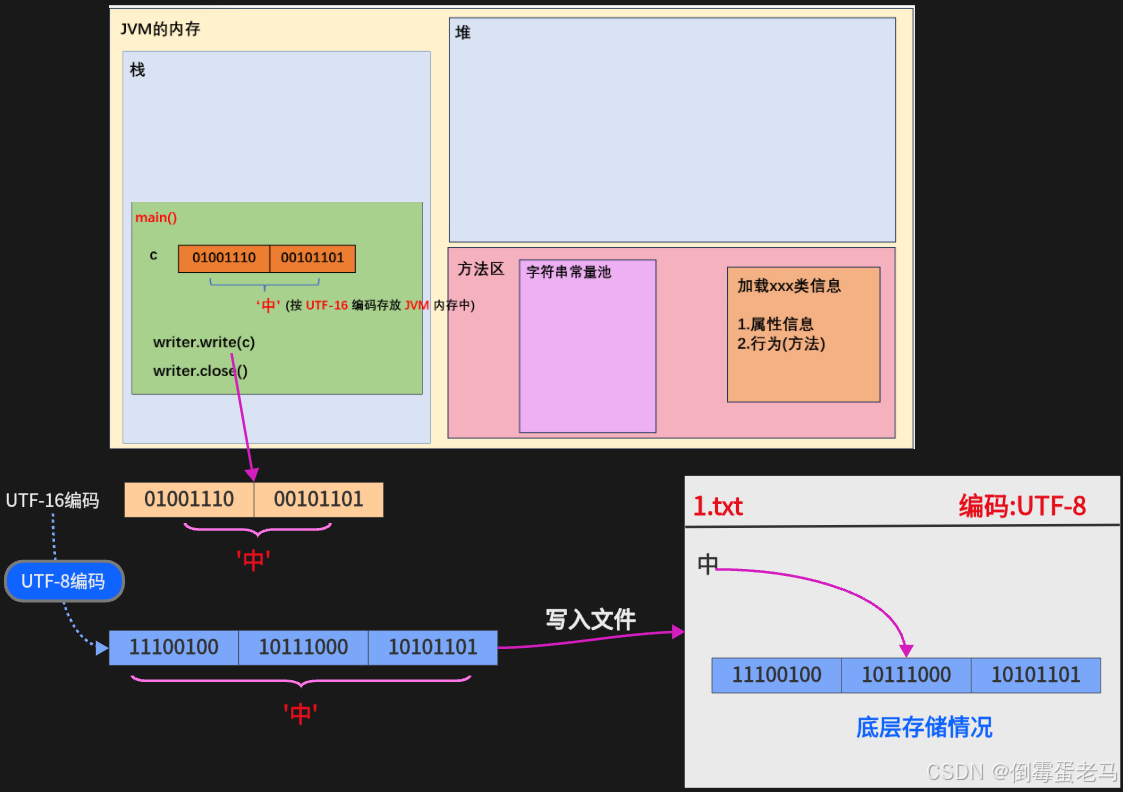
③ FileWriter + write 写入文件的流程剖析:
为了方便演示,这里我以 FileWriter + void write(int b) 演示,其他 write 方法的原理也是一样的
演示代码:
import java.io.*;
public class demo {public static void main(String[] args) throws IOException {//1.创建FileWriter字符输出流对象,关联目的地文件 1.txtWriter writer = new FileWriter("fileDemo\\1.txt");//2.将字符'中'写入到目的地文件中char c = '中';writer.write(c);//3.释放流资源,避免内存泄漏writer.close();}
}流程图:
2.5 FileWriter写入文件案例演示
写入文件的步骤
① 创建字符输出流对象 FileWriter ,关联目的地文件(建议第一步就抛出父类异常IOException)
② 调用 write 方法将字符写入到目的地文件中
③ 调用 close 方法释放流资源,避免内存泄漏
2.5.1 使用 public FileWriter(String filename) + write (int c)
使用该构造器时为覆盖模式(旧内容全部清空),流指针在文件首都端
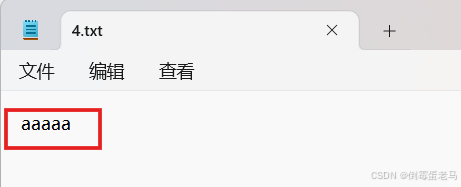
案例1:目的地文件中原先没有内容,写入 BMP 字符
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\4.txt,4.txt 是一个使用 UTF-8 编码的空文件,如下:

演示类完成的任务是:使用 write(int c) 将 BMP 字符 'a' 写入到 4.txt 中
演示代码如下:
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
public class demo {public static void main(String[] args) throws IOException {//1.创建FileWriter字符输出流对象,关联目的地文件 4.txtWriter writer = new FileWriter("D:\\javaProjects\\untitled\\fileDemo\\4.txt");//2.将字符写入到目的地文件中/**write(int b)的5种传入方式**/writer.write('a');//直接传入'a'writer.write(97);//'a'的UTF-16编码值的十进制writer.write(0x61);//'a'的UTF-16编码值的十六进制writer.write(0b0000000001100001);//'a'的UTF-16编码值的二进制writer.write('\u0061');//'a'的Unicode转义序列//3.释放流资源,避免内存泄漏writer.close();}
}执行效果:
案例2:目的地文件中原先有内容,写入辅助平面字符😊
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\4.txt,4.txt 是一个使用 UTF-8 编码的非空文件,其内容如下:
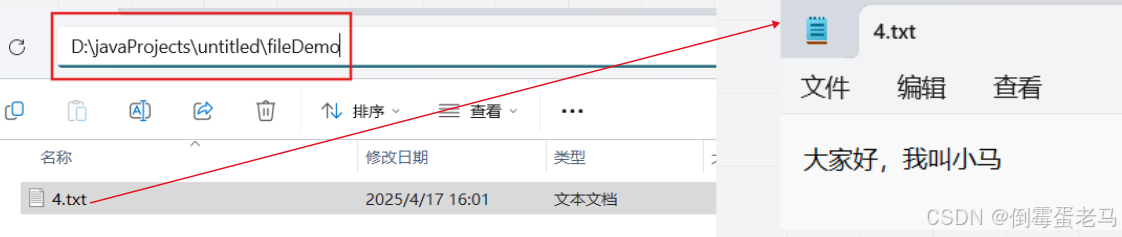
演示类完成的任务是:使用 write(int c) 将辅助平面字符 😊 写入到 4.txt 中。由于流的指针在文件的首端,所以 4.txt 的旧内容 "大家好,我叫小马" 会被全部清空覆盖
代码如下:
import java.io.*;
public class demo {public static void main(String[] args) throws IOException {//1.创建FileWriter字符输出流对象,关联目的地文件 1.txtWriter writer = new FileWriter("D:\\javaProjects\\untitled\\fileDemo\\4.txt");/*2.将辅助平面字符😊写入到目的地文件中😊的高位代理:0xD83D(十六进制),55357(十进制),0b1101100000111101(二进制),'\uD83D'(Unicode转义序列)😊的低位代理:0xDE0A(十六进制),56842(十进制),0b1101111000001010(二进制),'\uDE0A'(Unicode转义序列)*//*写入4个😊*/writer.write(0xD83D);//高位代理writer.write(0xDE0A);//低位代理writer.write(55357);//高位代理writer.write(56842);//低位代理writer.write(0b1101100000111101);//高位代理writer.write(0b1101111000001010);//低位代理writer.write('\uD83D');//高位代理writer.write('\uDE0A');//低位代理//3.释放流资源,避免内存泄漏writer.close();}
}执行效果:
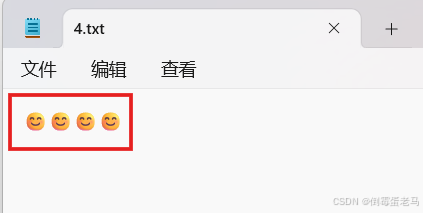
可以看到,4.txt 的原内容 "大家好,我叫小马" 确实 被 "😊😊😊😊" 给覆盖掉了
2.5.2 使用 public FileWriter(String filename,boolean append) + write (int c)
使用该构造器且 append = true 时,流的指针在文件尾端,每次调用 write 都是以追加模式将数据写入到文件中,不会覆盖文件的原内容
案例演示
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\4.txt,4.txt 是一个使用 UTF-8 编码的非空文件,其内容如下:

演示类完成的任务是:将 '唱'、'跳'、'篮'、'球' 4 个字符以追加模式写入到 4.txt 中,不覆盖 4.txt 的原内容
代码如下:
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
public class demo {public static void main(String[] args) throws IOException {//1.创建FileWriter字符输出流对象(追加模式),关联目的地文件 4.txtWriter writer = new FileWriter("D:\\javaProjects\\untitled\\fileDemo\\4.txt",true);//2.将目标数据写入到目的地文件中writer.write('唱');writer.write('跳');writer.write('篮');writer.write('球');//3.释放流资源,避免内存泄漏writer.close();}
}执行效果:
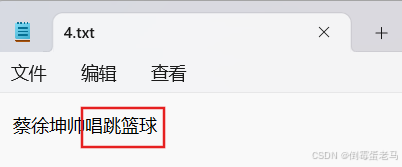
可以看到,'唱'、'跳'、'篮'、'球' 确实是以追加模式写入到 4.txt 中
2.5.3 使用 public FileWriter(String filename,boolean append) + write (String str)
调用 write(String str) 时,是将整个 str 字符串写入到文件中
案例演示
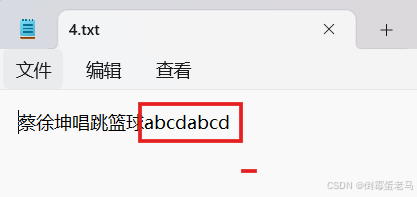
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\4.txt,4.txt 是一个使用 UTF-8 编码的非空文件,其内容是 "蔡徐坤唱跳篮球" 。具体如下:

演示类完成的任务是:将 4 个字符 'a' 、'b'、'c' 、'd' 用字符串形式 "abcd" 且以追加模式写入到 4.txt 中,不覆盖 4.txt 的原内容
演示代码如下:
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
public class demo {public static void main(String[] args) throws IOException {//1.创建FileWriter字符输出流对象,关联目的地文件 4.txtWriter writer = new FileWriter("D:\\javaProjects\\untitled\\fileDemo\\4.txt",true);//2.将字符串写入到目的地文件中/**write(String str)的2种传入方式**/writer.write("abcd");//直接传入字符串writer.write("\u0061\u0062\u0063\u0064");//按字符的Unicode转义序列传入//3.释放流资源,避免内存泄漏writer.close();}
}执行结果:
2.5.4 使用 public FileWriter(String filename) + write (char[ ] cbuf)
调用 write(char[ ] cbuf) 时,是将 cbuf 数组中的所有字符写入到文件中
案例演示
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\1.txt,1.txt 是一个使用 UTF-8 编码的空文件。具体如下:
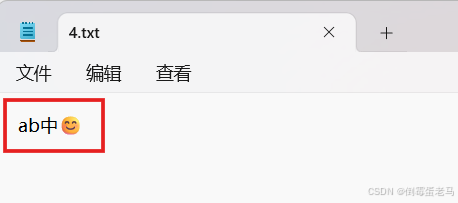
演示类完成的任务是:将 "ab中😊" 以字符数组形式写入到 1.txt 中,由于😊是辅助平面字符,在 UTF-16 编码后需要用 4 个字节存储,所以需要用 2 个 char 来表示,第一个 char 存储高位代理,第二个 char 存储低位代理
代码如下:
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
public class demo {public static void main(String[] args) throws IOException {//1.创建FileWriter字符输出流对象,关联目的地文件 4.txtWriter writer = new FileWriter("D:\\javaProjects\\untitled\\fileDemo\\4.txt",true);//2.将字符数组写入到目的地文件中,内容是"ab中😊"char[] cbuf = {'a',98,'中','\uD83D','\uDE0A'};//\uD83D是😊的高位代理,\uDE0A是😊的低位代理writer.write(cbuf);//3.释放流资源,避免内存泄漏writer.close();}
}执行结果:
🆗,其他方法就不演示了,应用起来也很简单
2.6 关于flush(刷新)
由于字符输出流自带缓冲区,因此程序员可以主动调用 flush() ,及时将缓冲区中的数据写入到文件中
PS:即便调用 flush() 写出了数据,但最终一定要要调用 close() 释放流资源,避免内存泄漏
案例演示
import java.io.*;
public class demo {public static void main(String[] args) throws IOException {FileWriter fw = new FileWriter("D:\\javaProjects\\untitled\\fileDemo\\1.txt");fw.write('蔡');//写入到缓冲区中,不是直接写入到文件中噢fw.flush();//刷新缓冲区,将缓冲区中的'蔡'写入到文件中}
}运行结果:
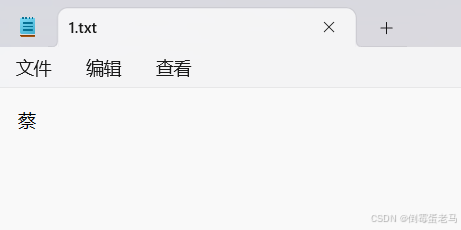
可以看到,字符输出流调用 flush() 可以及时将缓冲区中的数据写入到文件中
3.FileReader+FileWriter拷贝文本文件
拷贝文件,无非就是把前面的字符输入流 FileReader 读取文件和字符输出流 FileWriter 写入文件结合起来使用,如下:
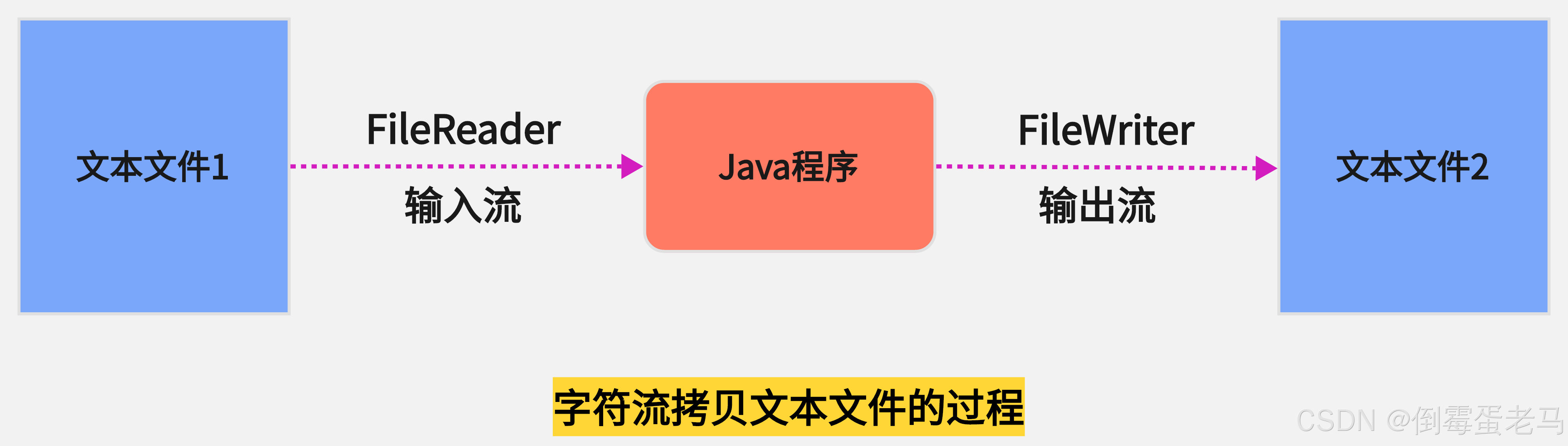
3.1 拷贝步骤
① 创建字符输入流 FileReader 对象,关联数据源文件
② 创建字符输出流 FileWriter 对象,关联目的地文件
③ 定义变量,记录读取到的内容
④ 循环调用 FileReader 的 read 方法读取,只要未到流末尾就一直读,将读取到的内容保存在变量中
⑤ 将读取到的数据调用 FileWriter 的 write 方法写入到目的地文件
⑥ 释放流资源,避免内存泄漏
3.2 案例演示
注意:案例中的源文件和目的地文件都使用 UTF-8 编码
3.2.1 以单个字符拷贝(不推荐)
以单个字符拷贝:即调用 read() 每次从源文件读取 1 个数据单位为 16 位的字符到 Java 程序(内存)中,再调用 write (int c) 把读取到的 1 个 字符写入到目的地文件
PS:以单个字符拷贝速度较慢,通常使用字符数组拷贝,不过这里还是演示一下吧
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\2.txt,2.txt 使用 UTF-8 编码,文本内容是 "大家好😊,我叫小马" 。具体如下:
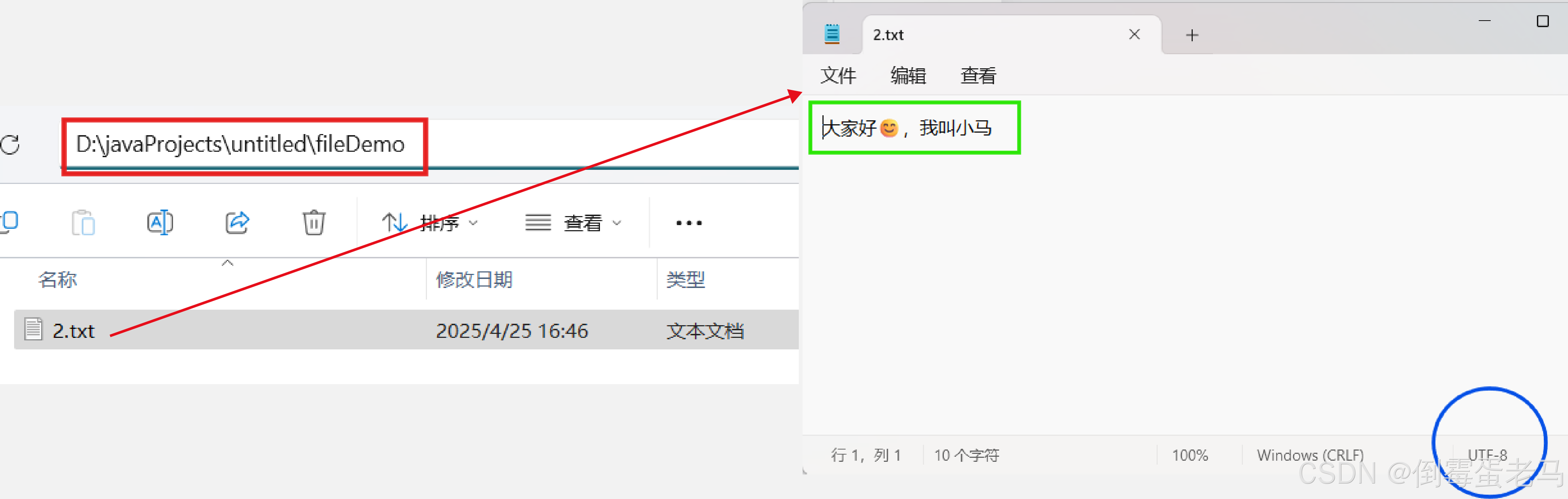
演示类完成的任务是:将 2.txt 中的全部内容以单个字符的形式拷贝到 D:\javaProjects\untitled\fileDemo\3.txt 文件中
代码如下:
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class demo{public static void main(String[] args) throws IOException{// 1.创建字符输入流FileReader对象,关联数据源文件 2.txtFileReader reader = new FileReader("D:\\javaProjects\\untitled\\fileDemo\\2.txt");// 2.创建字符输出流FileWriter对象,关联目的地文件 3.txtFileWriter writer = new FileWriter("D:\\javaProjects\\untitled\\fileDemo\\3.txt");//3.定义变量data,记录读取到的内容int data;// 4.循环调用 read() 方法读取,未到文件末尾就一直读,并将读取到的内容赋值给变量datawhile ((data = reader.read()) != -1){//5.将读取到的数据调用 write(int c) 方法写入到目的地文件writer.write(data);}// 6.释放流资源,避免内存泄漏reader.close();writer.close();}
}执行结果:
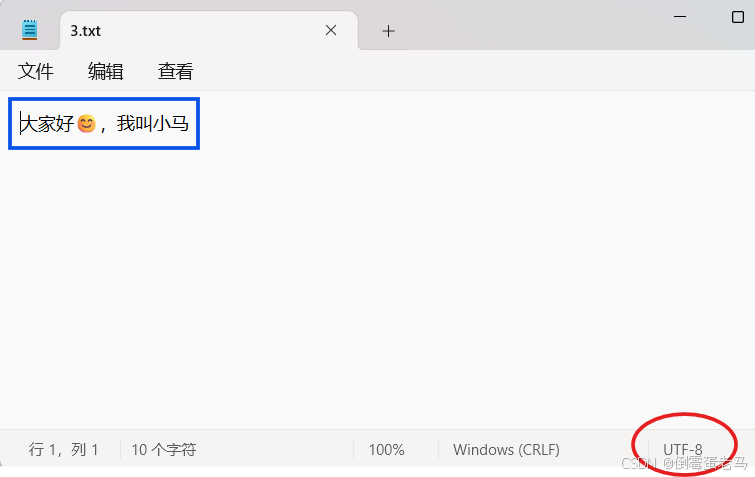
5.2.2 以字符数组拷贝(更常用)
以字符数组拷贝:即调用 read(char[ ] cubf) 每次从源文件读取 cubf.length 个数据单位为 16 位的字符到数组 cubf 中,再调用 write (char[ ] cubf,int off,int len) 把读取到的有效字符写入到目的地文件
演示类中使用到的文件路径是 D:\javaProjects\untitled\fileDemo\4.txt,4.txt 使用 UTF-8 编码,文本内容如下:
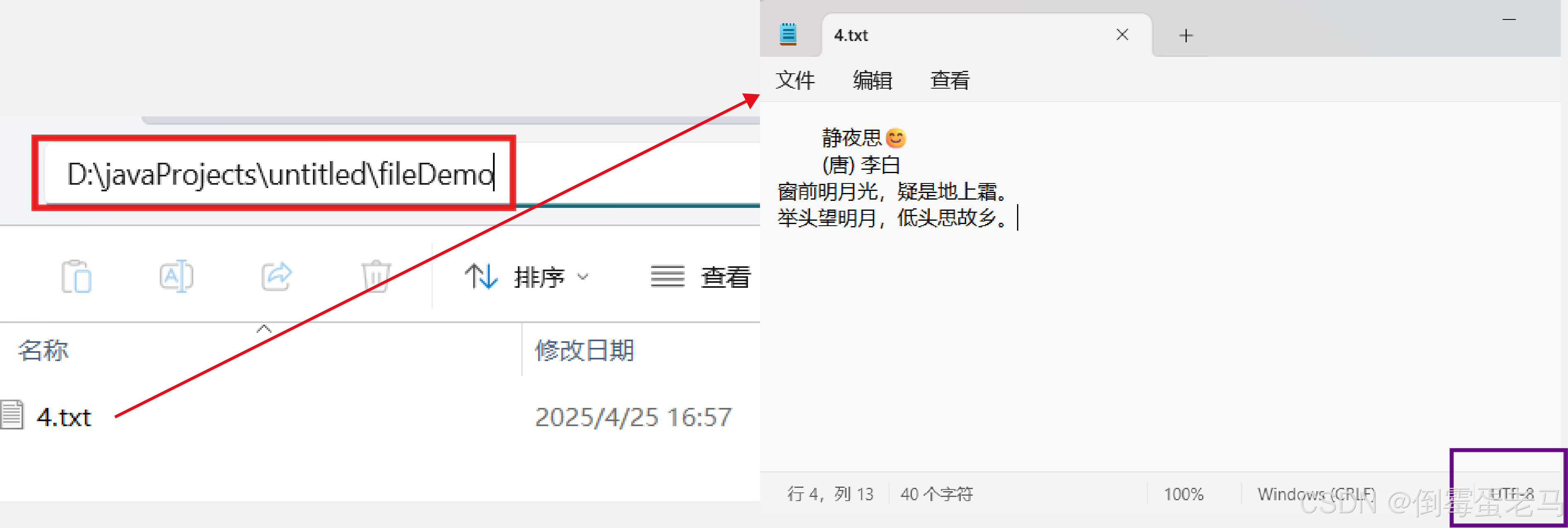
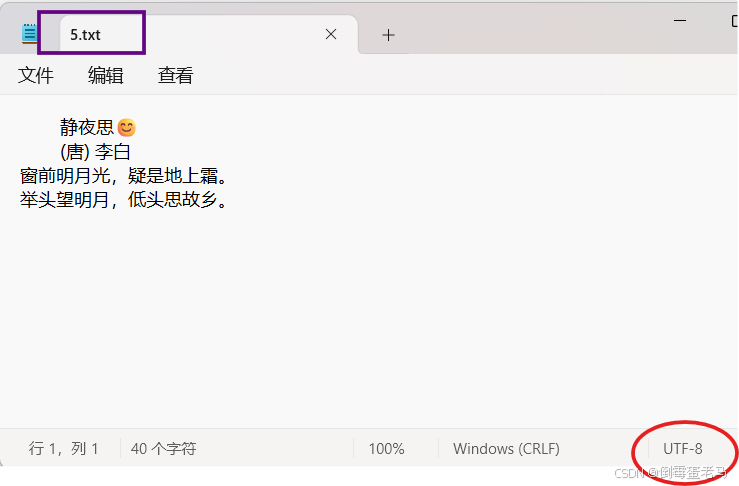
演示类完成的任务是:将 4.txt 中的全部内容以字符数组的形式拷贝到 D:\javaProjects\untitled\fileDemo\5.txt 文件中
代码如下:
import java.io.*;
public class demo{public static void main(String[] args) throws IOException{// 1.创建字符输入流FileReader对象,关联数据源文件 4.txtFileReader reader = new FileReader("D:\\javaProjects\\untitled\\fileDemo\\4.txt");// 2.创建字符输出流FileWriter对象,关联目的地文件 5.txtFileWriter writer = new FileWriter("D:\\javaProjects\\untitled\\fileDemo\\5.txt");//3.定义字符数组cbuf,记录读取到的内容char[] cbuf = new char[1024];//以字符数组的形式进行IO流拷贝操作时,所定义数组的长度最好是1024的整数倍,即每次读取1024个数据单位为16位的字符int len;//记录每次读取到的有效字符个数// 4.循环调用 read(char[] cbuf) 方法读取,只要未到文件末尾就一直读,读取到的数据保存在cbuf数组中while ((len = reader.read(cbuf)) != -1){//5.将读取到的数据调用 write(char[] cbuf,int off,int len) 方法写入到目的地文件writer.write(cbuf,0,len);}// 6.释放流资源,避免内存泄漏reader.close();writer.close();}
}执行结果:
🆗,以上就是 FileReader、FileWriter 的全部内容




