Boosting及提升树
Boosting概述
- Bootstrap强调的是抽样方法
不同的数据集彼此独立,可并行操作
- Boosting注重数据集改造
数据集之间存在强依赖关系,只能串行实现
处理的结果都是带来了训练集改变,从而得到不同的学习模型
Boosting基本思想
boosting样本集中,初始权重均等;根据上一个弱模型预测结果修改错分样本的权重。
- 生成具有不同样本权重的新数据集
- 训练新的弱学习模型
循环操作,生成n个不同的数据集
-
新数据集依次递进生成
-
训练n个不同的学习模型
-
根据组合策略生成强学习模型

Boosting的基本问题
- 如何计算预测的错误率
- 如何设置弱学习模型的权重系数
- 如何更新训练样本的权重
- 如何选择集成学习的组合策略
Boosting的常用方法
- AdaBoost 自适应提升
- Gradient Boosting 梯度提升
- Extreme Gradient Boosting 极端梯度提升
常用的弱学习模型
- 决策树
- GBDT(Gradient Boosting DecisionTree)
- XGBDT(eXtreme Gradient Boosting DecisionTree)
AdaBoost
- 加法模型:强学习模型是弱学习模型的线性组合
- 损失函数是指数型函数
- 学习算法是正向分步算法
- 采用“正向激励+递进”机制
- 也是需要根据损失函数自动调节
AdaBoost的特点
- 不是人为地调节训练样本权重,通过损失函数自适应权重调节
- 弱学习模型也有各自的权重
- 调节投票权大小
- 也是需要根据损失函数自动调节
分类误差率
-
对于样本集 X = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } X=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\} X={(x1,y1),(x2,y2),⋯,(xN,yN)}
-
建立K个弱学习模型,第k个模型的训练样本权重
D ( k ) = ( w k 1 , w k 2 , ⋯ , w k N ) D(k)=(w_{k1},w_{k2},\cdots,w_{kN}) D(k)=(wk1,wk2,⋯,wkN)
-
权重的初始化
w 1 i = 1 N ; i = 1 , 2 , ⋯ , N w_{1i}=\frac{1}{N};\qquad i=1,2,\cdots,N w1i=N1;i=1,2,⋯,N
-
样本的权重对应一种概率分布
∑ i = 1 N w k i = 1 \sum_{i=1}^Nw_{ki}=1 i=1∑Nwki=1
-
定义二值分类问题的误差,假定二值 [ − 1 , 1 ] [-1,1] [−1,1]
- 第k个弱学习模型的加权误差率
e k = P ( G k ( x i ) ≠ y i ) = ∑ i = 1 N w k i I ( G k ( x i ) ≠ y i ) I ( G k ( x i ) ≠ y i ) = 1 e_k=P(G_k(x_i)\neq y_i)=\sum_{i=1}^Nw_{ki}I(G_k(x_i)\neq y_i)\\ I(G_k(x_i)\neq y_i)=1 ek=P(Gk(xi)=yi)=i=1∑NwkiI(Gk(xi)=yi)I(Gk(xi)=yi)=1
即:
e k = P ( G k ( x i ) ≠ y i ) = ∑ y i ≠ G k ( x i ) N w k i e_k=P(G_k(x_i)\neq y_i)=\sum_{y_i\neq G_k(x_i)}^Nw_{ki} ek=P(Gk(xi)=yi)=yi=Gk(xi)∑Nwki
AdaBoost的组合策略
学习模型通过正向分布算法获得
每一轮都会生成新的弱模型,第k轮对应的强模型定义为:
f k ( x ) = ∑ i = 1 k α i G i ( x ) f_k(x)=\sum_{i=1}^k\alpha_iG_i(x) fk(x)=i=1∑kαiGi(x)
由当前所有的弱模型的线性组合而成,最终的强学习模型:
f ( x ) = s i g n ( ∑ k = 1 K α k G k ( x ) ) f(x)=sign(\sum_{k=1}^K\alpha_kG_k(x)) f(x)=sign(k=1∑KαkGk(x))
弱学习模型的权重
第k轮:
f k ( x ) = ∑ i = 1 k α i G i ( x ) = f k − 1 ( x ) + α k G k ( x ) f_k(x)=\sum_{i=1}^k\alpha_iG_i(x)=f_{k-1}(x)+\alpha_kG_k(x) fk(x)=i=1∑kαiGi(x)=fk−1(x)+αkGk(x)
求解:
( α k , G k ( x ) ) = a r g m i n ∑ i = 1 N e x p [ − y i ( f k − 1 ( x i ) + α G ( x i ) ) ] (\alpha_k,G_k(x))=arg\ min\ \sum_{i=1}^Nexp[-y_i(f_{k-1}(x_i)+\alpha G(x_i))] (αk,Gk(x))=arg min i=1∑Nexp[−yi(fk−1(xi)+αG(xi))]
令 w ‾ k i = e x p [ − y i [ f k − 1 ( x i ) ] \overline w_{ki}=exp[-y_i[f_{k-1}(x_i)] wki=exp[−yi[fk−1(xi)]
且 G k ∗ = a r g m i n ∑ i = 1 N w ‾ k i I ( y i ≠ G ( x i ) ) G_k^*=arg\ min\sum_{i=1}^N\overline w_{ki}I(y_i\neq G(x_i)) Gk∗=arg min∑i=1NwkiI(yi=G(xi))
则:
∑ i = 1 N w ‾ k i e [ − y i α G ( x i ) ] = ∑ y i = G k ( x i ) w ‾ k i e ( − α ) + ∑ y i ≠ G i ( x i ) w ‾ k i e ( α ) = ( e ( α ) − e − α ) ∑ i = 1 N w ‾ k i I ( y i ≠ G ( x i ) ) + e − α ∑ i = 1 N w ‾ k i ( α k ) = a r g m i n ( ( e α − e − α ) ∑ i = 1 N w ‾ k i I ( y i ≠ G ( x i ) ) + e − α ∑ i = 1 N w ‾ k i ) \sum_{i=1}^N\overline w_{ki}\ e^{[-y_i\alpha}G(x_i)]=\sum_{y_i=G_k(x_i)}\overline w_{ki}e^{(-\alpha)}+\sum_{y_i\neq G_i(x_i)}\overline w_{ki}\ e^{(\alpha)}\\=(e^{(\alpha)}-e^{-\alpha})\sum_{i=1}^N\overline w_{ki}I(y_i\neq G(x_i))+e^{-\alpha}\sum_{i=1}^N\overline w_{ki}\\ (\alpha_k)=arg\ min((e^\alpha-e^{-\alpha})\sum_{i=1}^N\overline w_{ki}I(y_i\neq G(x_i))+e^{-\alpha}\sum_{i=1}^N\overline w_{ki}) i=1∑Nwki e[−yiαG(xi)]=yi=Gk(xi)∑wkie(−α)+yi=Gi(xi)∑wki e(α)=(e(α)−e−α)i=1∑NwkiI(yi=G(xi))+e−αi=1∑Nwki(αk)=arg min((eα−e−α)i=1∑NwkiI(yi=G(xi))+e−αi=1∑Nwki)
对 α \alpha α求导,令导数为0,得: α k ∗ = 1 2 l n 1 − e k e k \alpha_k^*=\frac{1}{2}ln\frac{1-e_k}{e_k} αk∗=21lnek1−ek
其中, e k = ∑ i = 1 N w k i I ( y i ≠ G ( x i ) ) e_k=\sum_{i=1}^Nw_{ki}I(y_i\neq G(x_i)) ek=∑i=1NwkiI(yi=G(xi))
强学习模型权重
f k ( x ) = ∑ i = 1 k α i G i ( x ) = f k − 1 ( x ) + α k G k ( x ) f_k(x)=\sum_{i=1}^k\alpha_iG_i(x)=f_{k-1}(x)+\alpha_kG_k(x) fk(x)=i=1∑kαiGi(x)=fk−1(x)+αkGk(x)
w ‾ k + 1 = w ‾ k i Z k e y i α k G k ( x ) {\overline w_{k+1}}=\frac{\overline w_{ki}}{Z_k}e^{y_i\alpha_kG_k(x)} wk+1=ZkwkieyiαkGk(x)
AdaBoost的回归分析
- 计算错误率
- 第k个弱模型的最大误差 E k = m a x ∣ y i − G k ( x i ) ∣ E_k=max|y_i-G_k(x_i)| Ek=max∣yi−Gk(xi)∣
- 每个样本的误差 e k i = ∣ y i − G k ( x i ) ∣ E k e_{ki}=\frac{|y_i-G_k(x_i)|}{E_k} eki=Ek∣yi−Gk(xi)∣
- 第k个弱模型的错误率 e k = ∑ i = 1 N w k i e k i e_k=\sum_{i=1}^Nw_{ki}e_{ki} ek=∑i=1Nwkieki
- 权重的更新
- 第k个弱模型的权重 α k = e k 1 − e k \alpha_k=\frac{e_k}{1-e_k} αk=1−ekek
- 每个样本的权重更新 w k + 1 = w k i Z k α k 1 − e k i w_{k+1}=\frac{ w_{ki}}{Z_k}\alpha_k^{1-ek_i} wk+1=Zkwkiαk1−eki, ( Z k = ∑ i = 1 N w k i α k 1 − e k i ) (Z_k=\sum_{i=1}^Nw_{ki}\alpha_k^{1-e_{ki}}) (Zk=∑i=1Nwkiαk1−eki)
- 组合策略
- 对加权的弱学习器,取权重中位数对应的弱学习器,作为强学习器的方法。
- 最终的强回归器为 f ( x ) = G k ∗ ( x ) f(x)=G_k^*(x) f(x)=Gk∗(x)
- 其中 G k ∗ ( x ) G_k^*(x) Gk∗(x)是K个弱模型权重中位数对应的模型
AdaBoost的正则化
- 为了防止过拟合,可以引入正则化
对于强学习模型而言:
f k ( x ) = f k − 1 ( x ) + α k G k ( x ) f_k(x)=f_{k-1}(x)+\alpha_kG_k(x) fk(x)=fk−1(x)+αkGk(x)
改进模型:
f k ( x ) = f k − 1 ( x ) + v α k G k ( x ) f_k(x)=f_{k-1}(x)+v\alpha_kG_k(x) fk(x)=fk−1(x)+vαkGk(x)
其中,v为正则化参数,在此也称为步长(或者学习率),调节弱模型的生成。
AdaBoost的分类算法描述(二值)


AdaBoost的分类算法描述(多值)

AdaBoost回归算法描述
以AdaBoost R2为例

Gradient Boosting Tree
Boosting的本质:采用加法模型与正向激励算法
对弱学习模型的要求:学习能力差的模型,输出结果低方差,高偏差
弱模型采用决策树:
- 提升树(Boosting Tree)
- 采用CART(二叉树)
- 深度1-5即可,不宜太大
梯度提升树
初始化
f 0 ( x ) = a r g m i n ∑ i = 1 N L ( y i , c ) f_0(x)=arg\ min\sum_{i=1}^NL(y_i,c) f0(x)=arg mini=1∑NL(yi,c)
第m步残差
r m i = − ( ∂ L ( y i , f ( x i ) ) ∂ f ( x i ) ) f ( x ) = f x − 1 ( x ) r_{mi}=-(\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)})_{f(x)=f_{x-1}(x)} rmi=−(∂f(xi)∂L(yi,f(xi)))f(x)=fx−1(x)
利用 ( x i , r m i ) ( i = 1 , 2 , ⋯ , N ) (x_i,r_{mi})(i=1,2,\cdots,N) (xi,rmi)(i=1,2,⋯,N),可以拟合一棵CART回归树
对于叶子结点
c m j = a r g m i n ∑ L ( y i , f m − 1 ( x i ) + c ) c_{mj}=arg\ min\sum L(y_i,f_{m-1}(x_i)+c) cmj=arg min∑L(yi,fm−1(xi)+c)
第m步的强模型
f m ( x ) = f m − 1 ( x ) + ∑ c m j I ( x ∈ R m j ) f_m(x)=f_{m-1}(x)+\sum c_{mj}I(x\in R_{mj}) fm(x)=fm−1(x)+∑cmjI(x∈Rmj)
最终的强模型
f ^ ( x ) = f M ( x ) = f 0 ( x ) + ∑ m = 1 M ∑ j = 1 J c m i I ( x ∈ R m j ) \hat f(x)=f_M(x)=f_0(x)+\sum_{m=1}^M\sum_{j=1}^Jc_{mi}I(x\in R_{mj}) f^(x)=fM(x)=f0(x)+m=1∑Mj=1∑JcmiI(x∈Rmj)
对于分类树,与回归树的损失函数不同
如果采用指数函数,提升树退化为AdaBoost
也可采用逻辑回归函数
- 对数似然损失函数
- 二值分类和多值分类有不同的表示形式
对于二值分类
-
损失函数
L ( y , f ( x ) ) = l o g ( 1 + e − y f ( x ) ) , y ∈ { − 1 , 1 } L(y,f(x))=log(1+e^{-yf(x)}),\quad y\in \{-1,1\} L(y,f(x))=log(1+e−yf(x)),y∈{−1,1}
-
残差计算
r m j = − ( ∂ L ( y i , f ( x i ) ) ∂ f ( x i ) ) = y i 1 + e y i ( x i ) r_{mj}=-(\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)})=\frac{y_i}{1+e^{y_i(x_i)}} rmj=−(∂f(xi)∂L(yi,f(xi)))=1+eyi(xi)yi
-
对于为你和残差构建的决策树
c m j = a r g m i n ∑ l o g ( 1 + e − y i ( f m − 1 ( x i ) + c ) ) c_{mj}=arg\ min\sum log(1+e^{-y_i(f_{m-1}(x_i)+c)}) cmj=arg min∑log(1+e−yi(fm−1(xi)+c))
最优值的近似计算
c m j ≈ ∑ r m j ∑ ∣ r m j ∣ ( 1 − ∣ r m j ∣ ) c_{mj}\approx\frac{\sum r_{mj}}{\sum\ |r_{mj}|(1-|r_{mj}|)} cmj≈∑ ∣rmj∣(1−∣rmj∣)∑rmj
对于多值分类
-
对应K个分类的损失函数
L ( y , f ( x ) ) = ∑ k = 1 K y k l o g p k ( x ) L(y,f(x))=\sum_{k=1}^Ky_klog\ p_k(x) L(y,f(x))=k=1∑Kyklog pk(x)
如果输出样本类别为k,则 y k = 1 y_k=1 yk=1
-
第k类的概率的表达式为
p k ( x ) = e f k ( x ) / ∑ l = 1 K e f l ( x ) p_k(x)=e^{f_k(x)}/\sum_{l=1}^Ke^{f_l(x)} pk(x)=efk(x)/l=1∑Kefl(x)
-
计算残差
r m i l = − ( ∂ L ( y i , f ( x i ) ∂ f ( x i ) ) f k ( x ) = f l , m − 1 ( x ) = y i l − p l , m − 1 ( x i ) r_{mil}=-(\frac{\partial L(y_i,f(x_i)}{\partial f(x_i)})_{f_k(x)=f_{l,m-1}(x)}=y_{il}-p_{l,m-1}(x_i) rmil=−(∂f(xi)∂L(yi,f(xi))fk(x)=fl,m−1(x)=yil−pl,m−1(xi)
上式对应样本i对应类别l的真实概率和第m-1轮预测概率的差值
-
对于决策树优化
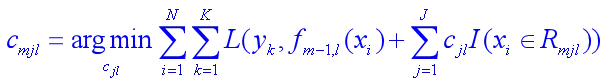
最优值的近似计算
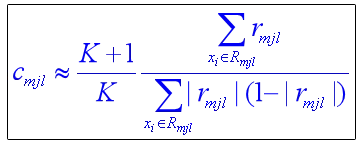
梯度提升树的其它常用损失函数
指数损失函数
L ( y , f ( x ) ) = e − y f ( x ) L(y,f(x))=e^{-yf(x)} L(y,f(x))=e−yf(x)
使用该函数,提升树退化为AdaBoost
绝对误差
L ( y , f ( x ) ) = ∣ y − f ( x ) ∣ L(y,f(x))=|y-f(x)| L(y,f(x))=∣y−f(x)∣
对应的负梯度误差
s i g n ( y i − f ( x i ) ) sign(y_i-f(x_i)) sign(yi−f(xi))
Huber损失函数
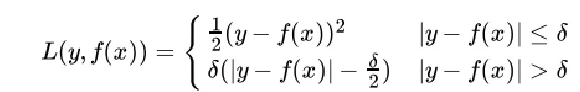
均方差和绝对差的折中产物,用于处理异常点
对应的负梯度误差:
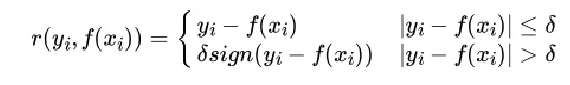
Qutantile(分位数)损失函数
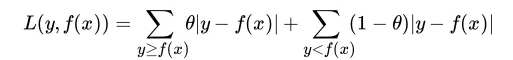
也能有效处理异常点
对应的负梯度误差
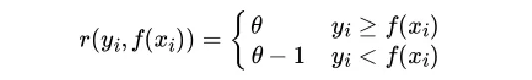
梯度提升树的正则化
方法一:
f k ( x ) = f k − 1 ( x ) + v h k ( x ) f_k(x)=f_{k-1}(x)+vh_k(x) fk(x)=fk−1(x)+vhk(x)
与AdaBoost算法手段相同
方法二:
采用采样比,取值为 ( 0 , 1 ] (0,1] (0,1]
用部分样本去拟合决策树,克服过拟合
此时的模型称为随机梯度提升树
可以实现部分并行,从而提升执行效率
梯度提升树总结
- 优点
- 可灵活处理各类数据
- 在相对少的调参情况下,预测准确率也可以比较高
- 对异常值鲁棒性强




