一.对文件的理解
首先我们已经知道,在Linux下,一切皆文件。
文件 = 文件内容 + 文件属性,所以一个文件的内容为0kb,但是其也占磁盘空间。所以对文件的操作其实就是对文件的内容和属性进行一系列的操作。
对文件操作,需要先打开文件,而打开文件的不是别人就是进程。所以对文件的操作,本质上是进程对文件操作。
一个进程有可能同时会打开多个文件,且一个文件可能同时被多个进程打开。所以操作系统要对打开的文件进行管理——先描述,在组织。
C语言里面的库函数fopen/fclose等文件操作的函数,本质上是对系统调用的封装。因为文件操作需要访问硬件,而一旦访问硬件就得借助系统调用来实现。
二.将信息输出到显示器
我们将消息输出到显示器,除了使用printf/cout,还可以使用一些文件读写函数来实现。
printf和cout默认就会向显示器打印消息,而fwrite和fprintf函数是向指定的文件里面写入消息。Linux一切皆文件,所以我们当然可以向显示器文件打印消息了。
#include <iostream>
#include <cstdio>
#include <cstring>int main()
{printf("printf()\n");std::cout << "cout" << std::endl;const char* msg = "hello world\n";fwrite(msg, strlen(msg), 1, stdout);fprintf(stdout, "%s\n", msg);return 0;
}
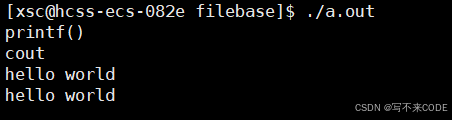
但是我们并没有打开stdout这个文件啊?为什么可以直接使用呢?
因为程序启动,C会默认为我们打开了三个文件,stdin,stdout,stderr。而且我们观察,它们的类型都是FILE*的。
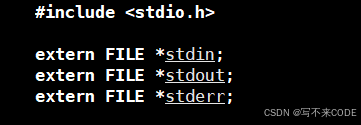
所以我们的程序其实是被动过手脚的,C会向我们的程序开头和结尾添一些代码。就比如三个标准输入输出流的打开和关闭。
三.系统文件I/O
C语言的的fopen封装了底层的系统调用。而fopen打开文件时要指定打开文件的方式。而这个方式在底层open函数中其实是以标志位的方式来传递的。而open函数只有一个参数作为标志位。那么它是怎么实现不同的打开方式的呢?
1.传递标志位
其实open采用的是位图来解决标志位的问题。一个整数的32个bit位,每一位都表示这不同的打开方式。
当我们采用|的方式就可以将不同的标志位绑定在一起,之后在利用|的结果去调用函数,就可以同时实现这两个标志位的方法。
#define ONE_FLAG 1
#define TWO_FLAG 1<<1
#define THREE_FLAG 1<<2
#define FOUR_FLAG 1<<3void func(int flags)
{if(flags & ONE_FLAG){printf("one\n");}if(flags & TWO_FLAG){printf("two\n");}if(flags & THREE_FLAG){printf("three\n");}if(flags & FOUR_FLAG){printf("four\n");}
}int main()
{func(ONE_FLAG);printf("\n");func(ONE_FLAG | TWO_FLAG);printf("\n");func(ONE_FLAG | TWO_FLAG | THREE_FLAG);printf("\n");func(ONE_FLAG | TWO_FLAG | THREE_FLAG | FOUR_FLAG);printf("\n");return 0;
}
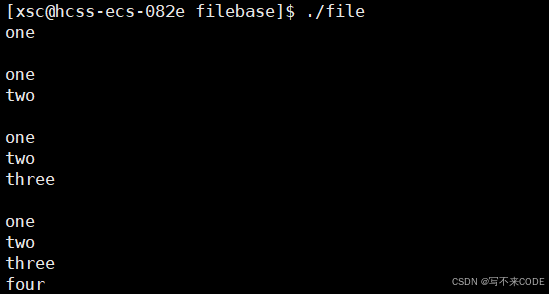
2.open系统调用
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
第一个参数就是指打开文件的路径,如果不指定路径,就默认会在当前路径下寻找该文件。
第二个参数就是标志位
- O_CREAT:指定文件不存在就创建文件
- O_RDONLY:只读方式打开文件
- O_WRONLY:只写方式打开文件
- O_TRUNC:清空文件内容
- O_APPEND:以追加的方式打开
有了这几个标志位,我们就可以实现C语言中的r,w,a等打开方式了。
第三个参数指的是文件的权限,如果打开的文件不存在,新建时我们得指定文件的权限。
如下,其实就是以w的方式打开文件,而我们当前目录下,并没有log.txt这个文件,运行程序之后,log.txt会创建。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main()
{open("log.txt", O_CREAT | O_WRONLY | O_TRUNC);return 0;
}
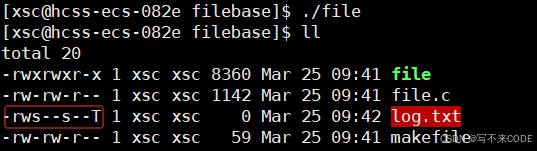
我们看到,创建的文件标红了,其权限是乱码。因为我们在新建文件时,并没有指定权限。
open("log.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666); // 指定权限 -rw- rw- rw- 当我们指定权限后,再来观察结果: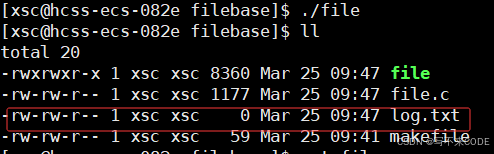
我们观察到,权限好像与我们设置的不一样啊,这是为啥呢?因为权限掩码umask的存在。
它会指定创建文件时不想存在的权限。
如果向避免umask对创建文件的影响,我们可以在我们的程序中先将umask置为0,避免影响我们对权限的设置。
umask(0);
open("log.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666); // 指定权限 -rw- rw- rw-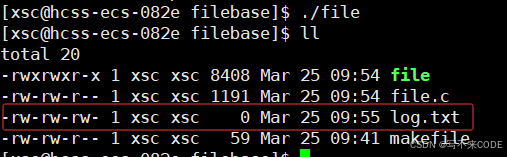
3.open的返回值
open打开文件成功则会返回一个文件描述符,如果失败则返回-1,并设置错误码
open() and creat() return the new file descriptor, or -1 if an error occurred (in which case, errno is set appropriately).
这里的文件描述符其实就类似于C语言的FILE*指针。该文件描述符就代表了我们所打开的文件,我们后续对文件的操作都需要借助该文件描述符。
我们打开多个文件来看一起他们的文件描述符:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>int main()
{umask(0);int fd1 = open("log1.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666); // 指定权限 -rw- rw- rw-int fd2 = open("log2.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666); // 指定权限 -rw- rw- rw-int fd3 = open("log3.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666); // 指定权限 -rw- rw- rw-int fd4 = open("log4.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666); // 指定权限 -rw- rw- rw-printf("%d\n", fd1);printf("%d\n", fd2);printf("%d\n", fd3);printf("%d\n", fd4);close(fd1);close(fd2);close(fd3);close(fd4);return 0;
}
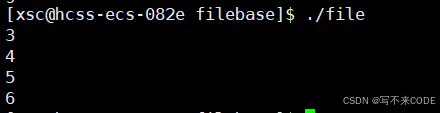
我们看到,他们的文件描述符是从3开始依次递增的。那为什么是从3开始的呢?我们待会在作解释。
4.write
#include <unistd.h>ssize_t write(int fd, const void *buf, size_t count);我们注意观察,write对写入的字符串是什么格式并没有规定,是void*的。
而对于C的文件操作接口来说,却分为文本写入和二进制写入,但是两者其实都调用的是底层的write接口。所以本质上根本就没有什么二进制写入和文本写入,这是对于用户曾来说的,在底层系统不关心你的写入方式。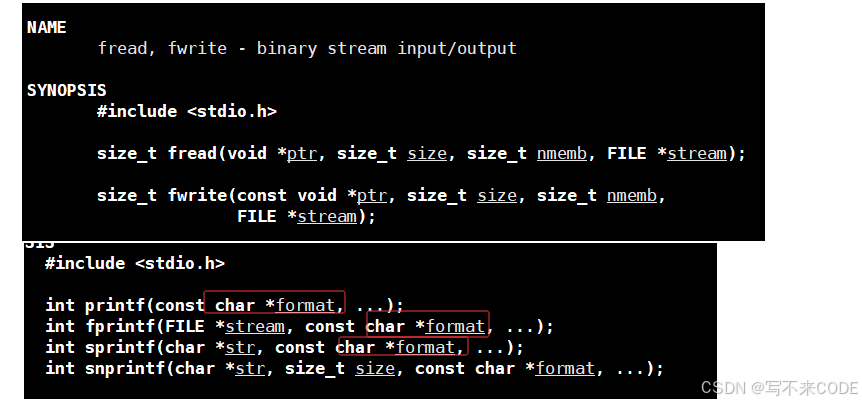
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>int main()
{umask(0);int fd = open("log.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666);const char* msg = "hello world\n";int cnt = 5;while(cnt){write(fd, msg, strlen(msg));cnt--;}close(fd);return 0;
}
5.FILE*
C语言打开文件返回一个FILE*的指针,而从现在看来,FILE这个结构体里面一定封装了文件描述符fd。
而且不仅是C语言,C++,java,python等语言,都有自己的文件操作那一套,它们都对底层的open等函数进行了封装,为什么呢?
为了代码的可移植性!!!
因为你有可能在不同的系统下编写程序,你用Windows的系统调用,代码在Linux上是不能运行的。因为两个平台的系统调用不一致。
在不同的环境下要使用不同的系统调用,而语言层就会对每个环境写一套适合的库,采用条件编译的方式,这样你写的C/C++代码就有了可移植性,可以在多个平台下运行。
四.文件描述符
我们在open返回值那里知道了文件描述符,但文件描述到底是啥呢?为啥文件描述符是从3开始的呢?
其实文件描述符是从0开始的,0,1,2分别是默认打开的stdin,stdout和stderr。我们可以借助stdin->_fileno来查看他们的文件描述符。
int main()
{printf("stdin:%d\n",stdin->_fileno);printf("stout:%d\n",stdout->_fileno);printf("stderr:%d\n",stderr->_fileno);umask(0);int fd1 = open("log1.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666); // 指定权限 -rw- rw- rw-int fd2 = open("log2.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666); // 指定权限 -rw- rw- rw-int fd3 = open("log3.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666); // 指定权限 -rw- rw- rw-int fd4 = open("log4.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666); // 指定权限 -rw- rw- rw-printf("%d\n", fd1);printf("%d\n", fd2);printf("%d\n", fd3);printf("%d\n", fd4);close(fd1);close(fd2);close(fd3);close(fd4);return 0;
}
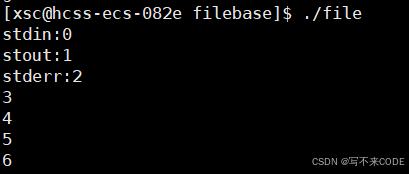
文件描述符是从0开始的,然后依次增大的。从0开始且依次增大,这不就是数组下标么?!
操作系统要对文件进行管理,就得先描述在组织。
而当打开一个文件时,操作系统会在内部为该文件创建一个struct file结构体,里面包含了文件的相关信息:
struct file
{属性集读写位置读写选型...struct file* next;
}除此之外,操作系统还会为每一个文件开辟一个文件缓冲区,打开文件其实就是创建对应的struct file结构体,以及将文件内容拷贝到文件缓冲区中。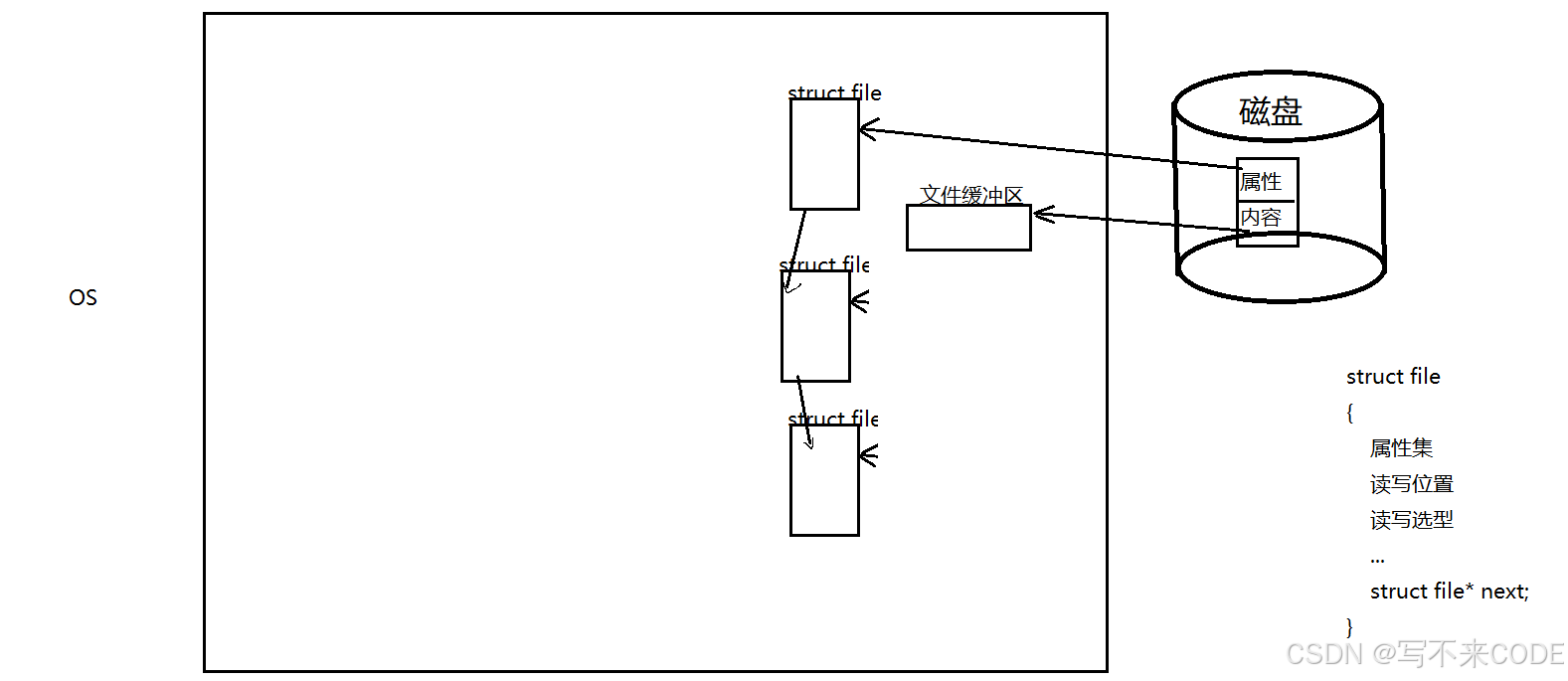
而文件是被进程打开的,所以进程就要有打开文件的属性和内容,所以进程的pcb中有一个files_struct* files 的指针,指向一张文件描述符表。
而这张表的类型是struct file* fd_array[],里面的每一个位置存储的都是一个指向struct file结构体的指针。而它的下标,就是对应的文件描述符。所以,open返回的其实就是数组的下标,我们获取下标,通过fd_array访问到对应的文件。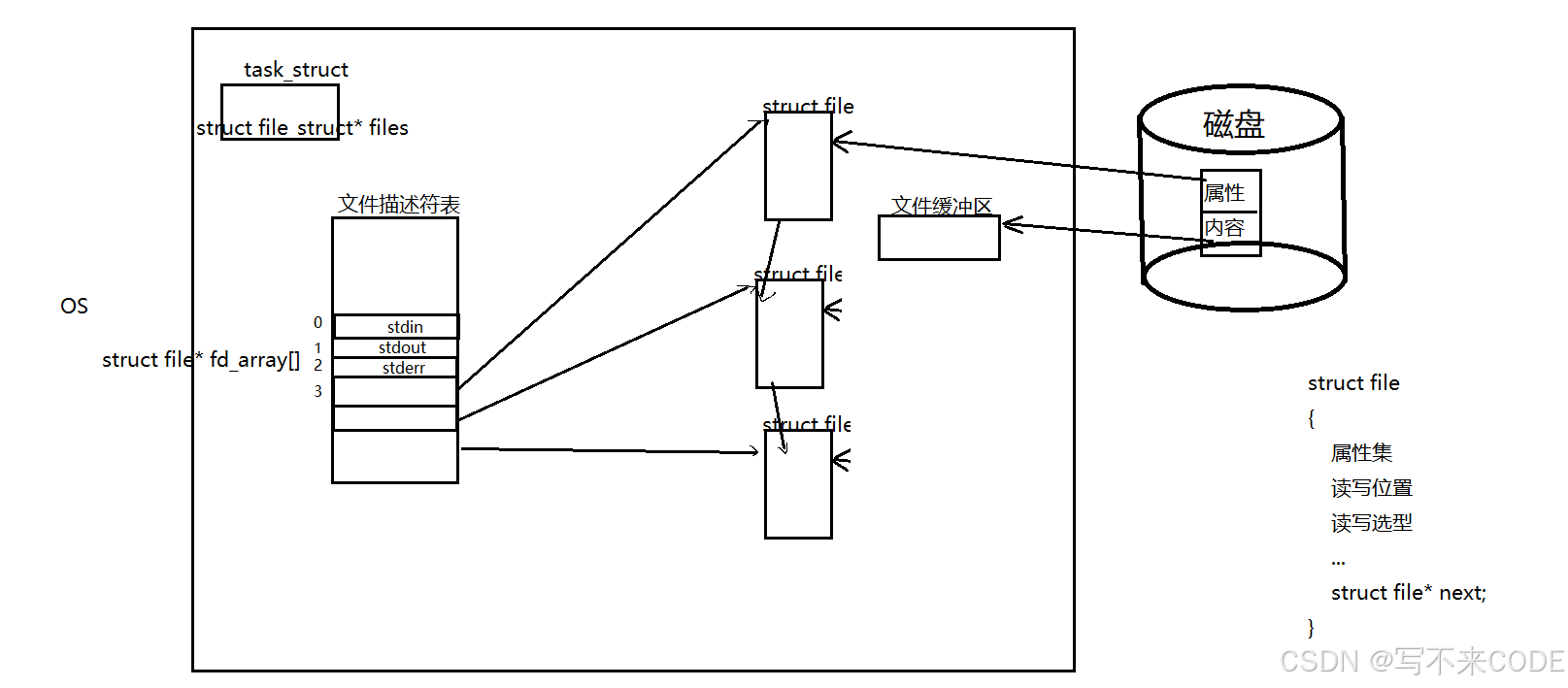
- 对文件内容做任何操作都必须先将文件内容加载到对应的内核中的文件缓冲区中。说是加载,其实就是拷贝(磁盘->内存)。
- 而在用户层,我们读取文件内容其实就是打开文件获取文件描述符,调用read(fd, buffer, ...),其实就是通过fd去查文件描述符表,找到对应文件的缓冲区,将其内容拷贝到buffer中。
- 对文件内容的修改操作,其实是将我们已有的buffer,拷贝到文件对应的缓冲区中,然后操作系统会定时将缓冲区中的内容刷新到磁盘中。
另外,一个文件有可能同时被多个进程打开,所以struct file结构体里面还存在f_count引用计数,表示当前文件被多少个进程所打开。当一个进程close(fd)后,不会立刻关闭该文件,而是使其f_count--,当f_count为0时---没有任何进程指向该文件,此时才将该文件的内核数据结构销毁,释放资源,将缓冲区内容刷新到磁盘中。
五.重定向
文件描述符的分配原理:最小的,还没有被使用的数组小标作为新的fd给用户。
因为stdin,stdout和stderr会被默认打开,占据了文件描述符表的前三个位置,所以再打开文件时fd是从3开始的。
那如果我们将stdin关闭呢?
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>int main()
{close(0); // 关闭stdinint fd = open("log.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666);if(fd == -1){perror("open");exit(1);}printf("fd:%d\n", fd);return 0;
}
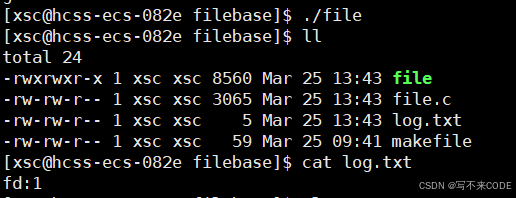
我们看结果,0号被关闭了,此时最小的未被使用的就是0号了,此时再打开文件就会以0作为文件描述符了。
![]()
那如果关闭了stdout呢?stderr呢?
![]()
当关闭stdout时,运行程序居然没有打印消息,但是观察之后 log.txt里面居然有了内容,打印内容发现,本该打印在显示器的消息居然打印在了log.txt文件中。
当关闭stderr时,可以看到消息。
这是因为stdout是标准输出,指的是终端,当我们将其关闭后,就无法给终端文件写信息了,所以此时不会显式消息。而stderr是标准错误,也指的是终端,但其一般指的是错误信息,而printf不是错误信息,所以可以显式。
1.重定向原理
有了上面的现象,其实就可以解释重定向的原理。printf其实就是向显示器文件内部写信息,当我们关闭之后,就会导致写入失败。
但是我们关闭之后,又打开了一个新的文件,此时新的文件就占据了原来stdout的位置。而stdout里面就封装了1作为其文件描述符,但是此时1位置的文件已经是修改后的了,所以printf默认向stdout打印时,就会打印到修改后的文件内部!!!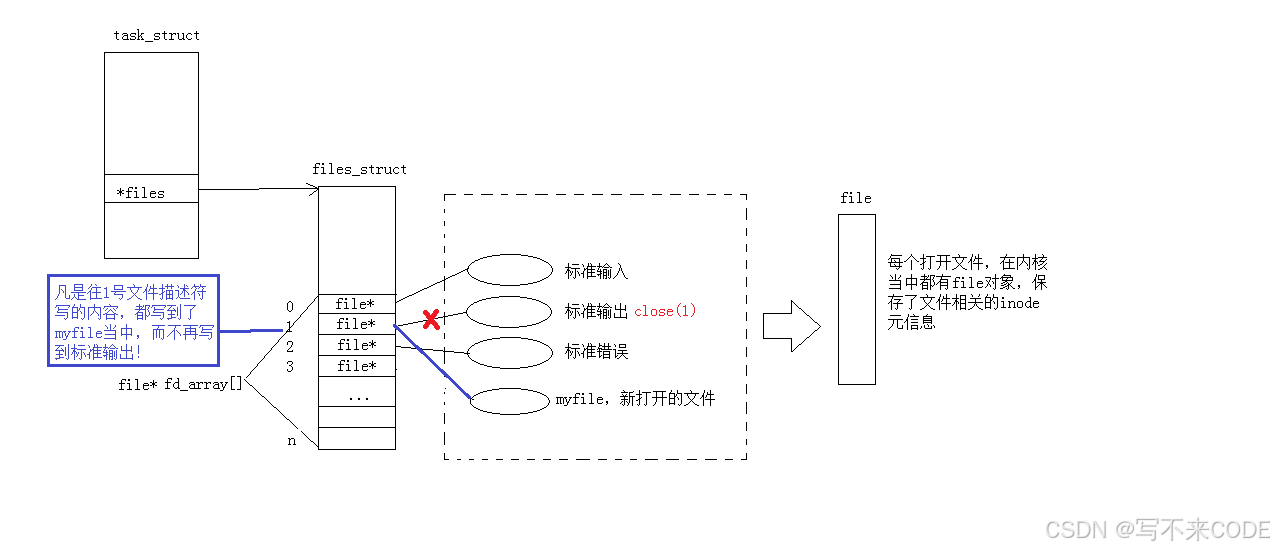
所以,重定向的原理,其实就是改变文件描述符的指针的指向
2.实现重定向
#include <unistd.h>int dup2(int oldfd, int newfd);
dup2可以改变文件描述符所指向的文件。
让newfd成为oldfd的copy,即让newfd指向oldfd所指向的文件。
调用完dup2之后,你可以选择是否关闭oldfd。因为此时oldfd和newfd都指向oldfd指向的文件,该文件此时的f_coutnt引用计数是2,所以关闭oldfd该文件也不会被释放。
int main()
{int fd = open("log.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666);dup2(fd,1); // 让stdout指向fdprintf("hello world\n");return 0;
}
说明:让stdout执行fd之后,此时printf默认向stdout打印时,就会打印到log.txt中,因为stdout已经被修改成了log.txt。
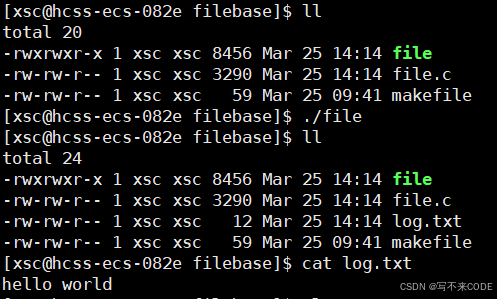
其实上述操作就实现了输出重定向的操作。
而如果想要实现追加重定向或者是输入重定向,就需要修改打开文件的方式!!!
3.在minshell中添加重定向操作
1、我们需要在命令解析前先对重定向操作进行判断,我们可以倒着向前寻找命令中是否有< >.
- 如果是<那就是输入重定向,接下来我们将<在命令中覆盖掉,并获取重定向文件名以及设置重定向类型。
- 如果是>,那么我们还得继续判断前一个是否还是>,确定是追加还是输出。接着也是覆盖符号,获取重定向文件,设置重定向类型。
2、完成之后,对命令进行分析,接着就是执行命令。
3、执行命令
- 我们需要根据重定向的类型,以不同的方式打开文件,并改变特定文件描述符表的内容,以达到重命名的目的。
// 重定向操作
#define NONE_REDIR 0
#define INPUT_REDIR 1
#define OUTPUT_REDIR 2
#define APPEND_REDIR 3int redir; // 重定向类型
std::string filename; // 重定向目标文件void skipSpace(char cmd[], int& end)
{while(isspace(cmd[end])) end++;
}void reDir(char cmd[])
{redir = NONE_REDIR;filename.clear();int begin = 0;int end = strlen(cmd)- 1;// 判断重定向类型while(end > begin){if(cmd[end] == '<'){redir = INPUT_REDIR;cmd[end++] = 0;skipSpace(cmd, end);filename = cmd+end;}else if(cmd[end] == '>'){if(cmd[end-1] == '>'){redir = APPEND_REDIR;cmd[end-1] = 0;}else{redir = OUTPUT_REDIR;}cmd[end++] = 0;skipSpace(cmd, end);filename = cmd+end;}else{end--;}}
}// 执行命令
void exectue()
{pid_t id = fork();if(id == 0){// childif(redir == 1) // 输入重定向{int fd = open(filename.c_str(), O_RDONLY);if(fd < 0){perror("open");exit(1);}dup2(fd, 0);close(fd);}else if(redir == 2) // 输出重定向{int fd = open(filename.c_str(), O_CREAT | O_WRONLY | O_TRUNC, 0666);if(fd < 0){perror("open");exit(2);}dup2(fd, 1);close(fd);}else if(redir == 3) // 追加重定向{int fd = open(filename.c_str(), O_CREAT | O_WRONLY | O_APPEND, 0666);if(fd < 0){perror("open");exit(3);}dup2(fd, 1);close(fd);}execvp(argv[0], argv);exit(1);}// fatherint status = 0;pid_t rid = waitpid(id, &status, 0); // 阻塞等待if(rid < 0){exit(2);}
}测试重定向:
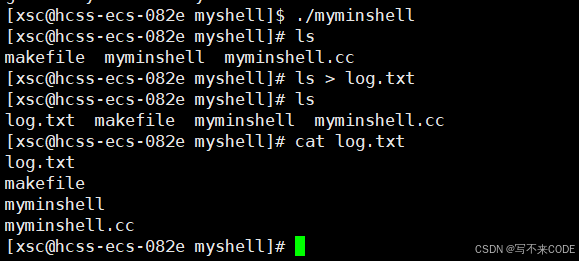
4.进程替换与重定向
进程替换是否会影响重定向操作呢?
毫不影响!
因为重定向操作修改的是进程中的文件描述符表,而程序替换是进行代码和数据的覆盖式修改。进程还是原来的进程。只不过代码修改了。所以此时替换上来的进程使用的就是该进程的文件描述符表,所以程序替换并不会对重定向操作产生影响!!!
5.标准错误stderr/cerr
我们知道stderr的文件描述符是2,但是它和标准输出都指的是显示器。那两者有什么区别呢?我们看下面这个例子来理解stderr和stdout的关系。
#include <iostream>
#include <cstdio>
#include <cstring>int main()
{printf("hello printf\n");std::cout << "hello cout" << std::endl;const char* msg = "hello stderr\n";fprintf(stderr, msg,strlen(msg));std::cerr << "hello cerr" << std::endl;return 0;
}
说明:我们分别使用printf和cout会默认向标准输出打印消息,cerr和stderr则是标准错误,我们向标准错误也打印两条消息。但是他们两个都指的是显示器,所以我们这些消息我们都可以看到。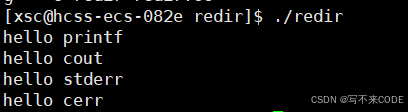
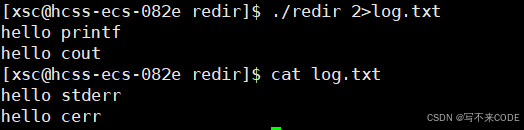
那么我们如果在运行文件时进行重定向操作呢?
我们看到下图,我们进行输出重定向时,按道理应该将打印出来的所有消息都重定向到log.txt文件中,但是标准错误却没有被重定向。


这是为啥呢?首先,我们这样的重定向操作其实是简化后的,真正的重定向操作应该这样写:
其实这样写一目了然,就是将1->标准输出重定向到log.txt。
./redir 1>log.txt而我们已经知道了重定向的原理,就是改变文件描述符表的内容。上述操作相当于将1位置的内容用log.txt覆盖,此时1就不再指向stdout了,而指向log.txt,所以本应打印在stdout的内容就会打印在log.txt中。
而stderr对应的文件描述符表的内容并没有修改,它依旧指向显示器文件。所以stderr的输出消息依旧会在显示器上。
既然如此,那我们要是指定 ./redir 2>log.txt 是否就会将本应打印到stderr的信息打印到log.txt中,而本应打印到stdout的消息,依旧会打印在显示器上?
没错!!!
那么如何将stdout和stderr打印到同一个文件呢?
可以使用命令:
./redir 1>log.txt 2>&1 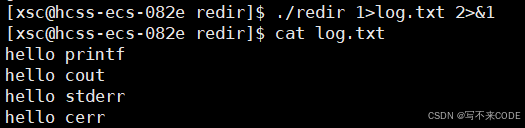
那么为什么既然有stdout又要有stderr呢?
通过重定向操作,可以将常规消息和错误消息区分开。当我们将所有的错误消息抽离出来,这就为我们日志的书写奠定了基础。
六.如何理解一切皆文件
Linux中的普通文件、目录等叫做文件我们都可以理解。那些硬件---键盘、鼠标、显示器、网卡等要怎么将其理解成一个文件呢?
首先,每一个硬件都要有其唯一的读写等方式。而且操作系统还要将所有的硬件给管理起来---先描述在组织。所以在操作系统内部,每一个硬件都有一个struct device的结构体,里面包含了设备的类型,属性、状态等等信息,当然里面肯定还有指针使所有的设备连接起来。这样操作系统对管理设备就变成了对这个链表的管理。
struct device
{// type// status// 相关信息...list_head head;
};之所以能认为一切皆文件,因为打开一个文件就会在操作系统中创建一个struct file结构体。struct file结构体里包含一个inode来存储文件的属性,以及一个内核文件缓冲区。除此之外,该file结构体内部,还包含了一系列的函数指针。这些函数指针都有着相同的参数,当我们传不同的参数时,就会调用不同硬件设备的读写方式等。
有了struct file结构,进程访问硬件的时候,就通过文件描述符,找到对应的struct file对象,然后通过内部的函数指针,以及参数传递来实现访问指定硬件的独特的读写方式。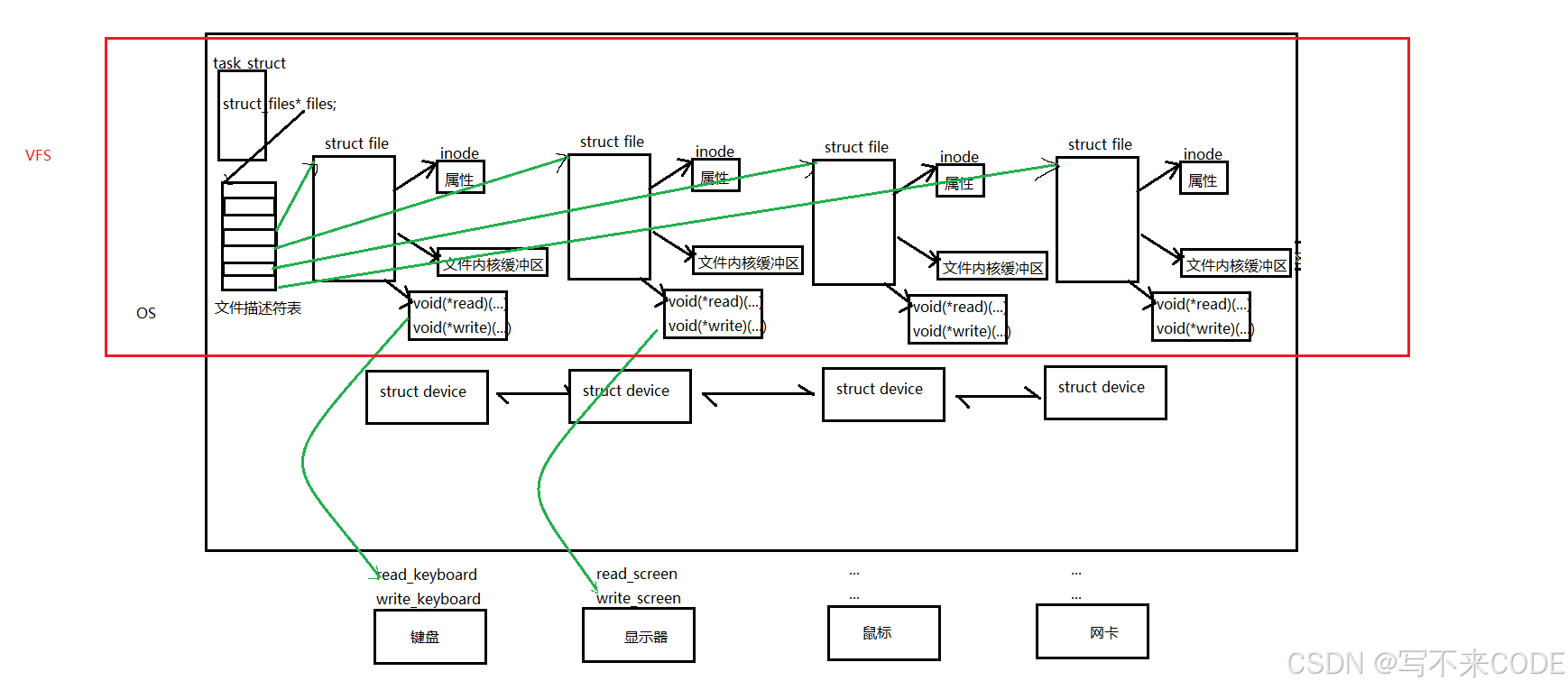
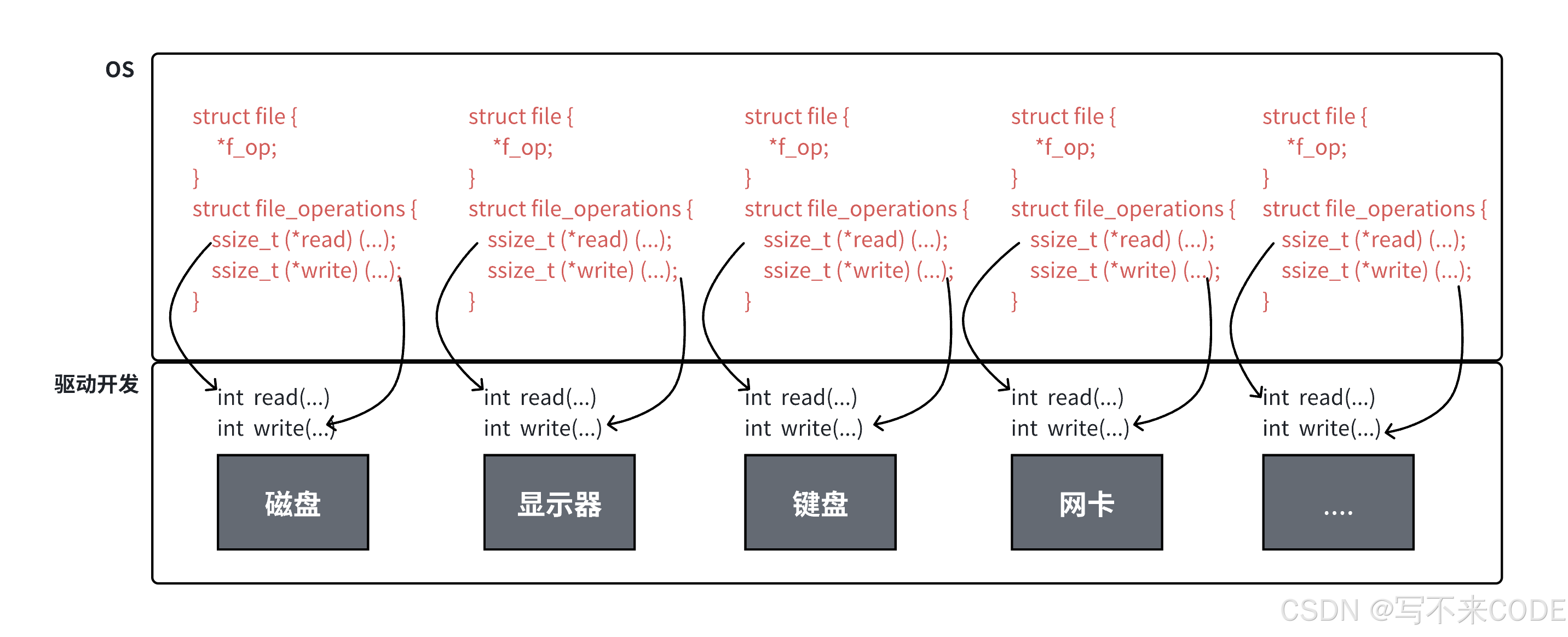
而我们用户访问硬件都是通过进程访问的,然后进程在访问硬件时是通过file结构来访问的,所以进程认为硬件是文件,所以对于用户来说,硬件也就成了文件。
struct file {union {struct llist_node fu_llist;struct rcu_head fu_rcuhead;} f_u;struct path f_path;struct inode *f_inode; /* pointer to inode */const struct file_operations *f_op; /* pointer to operations *//** Protects f_ep_links, f_flags.* Must not be taken from IRQ context.*/spinlock_t f_lock;enum rw_hint f_write_hint;atomic_long_t f_count; /* number of file references */unsigned int f_flags; /* file flags */fmode_t f_mode; /* mode of the file */loff_t f_pos; /* current file offset */struct fown_struct f_owner; /* owning process info */struct file_ra_state f_ra; /* read-ahead state */file_lock_t f_lockv; /* cached file lock */struct address_space *f_mapping; /* associated address space *//* private data here may vary between file types */
} __attribute__((aligned(4))); /* lest something weird decides that 2 is OK */struct file_operations {struct module *owner; // 拥有该操作的模块loff_t (*llseek) (struct file *, loff_t, int); // 移动文件读写指针ssize_t (*read) (struct file *, char __user *, size_t, loff_t *); // 从文件中读取数据ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *); // 向文件中写入数据ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t); // 异步读取数据ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t); // 异步写入数据int (*readdir) (struct file *, void *, filldir_t); // 读取目录内容unsigned int (*poll) (struct file *, struct poll_table_struct *); // 轮询文件状态long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long); // 执行设备特定操作long (*compat_ioctl) (struct file *, unsigned int, unsigned long); // 32位兼容ioctl调用int (*mmap) (struct file *, struct vm_area_struct *); // 映射文件到内存地址空间int (*open) (struct inode *, struct file *); // 打开文件int (*flush) (struct file *, fl_owner_t id); // 刷新文件数据int (*release) (struct inode *, struct file *); // 关闭文件int (*fsync) (struct file *, loff_t, loff_t, int datasync); // 同步文件数据到存储设备int (*aio_fsync) (struct kiocb *, int datasync); // 异步同步文件数据int (*fasync) (int, struct file *, int); // 通知文件异步事件int (*lock) (struct file *, int, struct file_lock *); // 加锁文件ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int); // 发送页面数据到socketunsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long); // 获取未映射的内存区域int (*check_flags)(int); // 检查文件打开标志int (*flock)(struct file *, int, struct file_lock *); // 文件加锁操作ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int); // 拼接写入数据ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int); // 拼接读取数据/* ... 其他函数指针,根据内核版本和文件系统类型可能有所不同 ... */
};七.缓冲区
先看一个现象:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main()
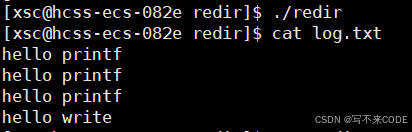
{close(1);// fd == 1int fd = open("log.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666);// 库函数printf("hello printf\n");printf("hello printf\n");printf("hello printf\n");// 系统调用const char* msg = "hello write\n";write(fd, msg, strlen(msg));close(fd);return 0;
}
说明:我们先关闭文件描述符1,此时在打开文件,根据文件描述符的分配原则:最小的未被使用的,此时fd就应该为1.然后我们分别用库函数和系统调用向fd里面写内容,默认都是向stdout写的,但是stdout封装的1描述符已经改变了,所以内容都写到了log.txt中。当调用完之后,关闭fd。
首先看当不关闭fd时的结果:
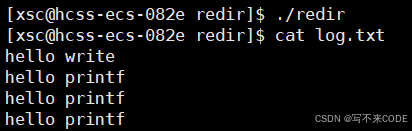
关闭fd的结果:

这是为什么呢?
其实这些都是缓冲区造成的!!!
1.语言级缓冲区和内核文件缓冲区
之所以会出现上面这种情况,就是因为printf这些库函数,不会直接将写的内容拷贝到内核文件缓冲区,而是写到C语言提供的缓冲区中,write这些系统调用则会直接将内容写到内核文件缓冲区中。此时还都没有刷新缓冲区,而当我们手动close(fd)关闭文件后,操作系统就会刷新内核文件缓冲区,此时内容就刷新到了磁盘文件中。但是库函数写的内容还在C语言提供的缓冲区中,还没有刷新到内核文件缓冲区中,当进程结束后,才刷新语言级缓冲区,但是文件都已经关闭了,刷新不到内核缓冲区中了。所以在log.txt中,只会有write写的内容。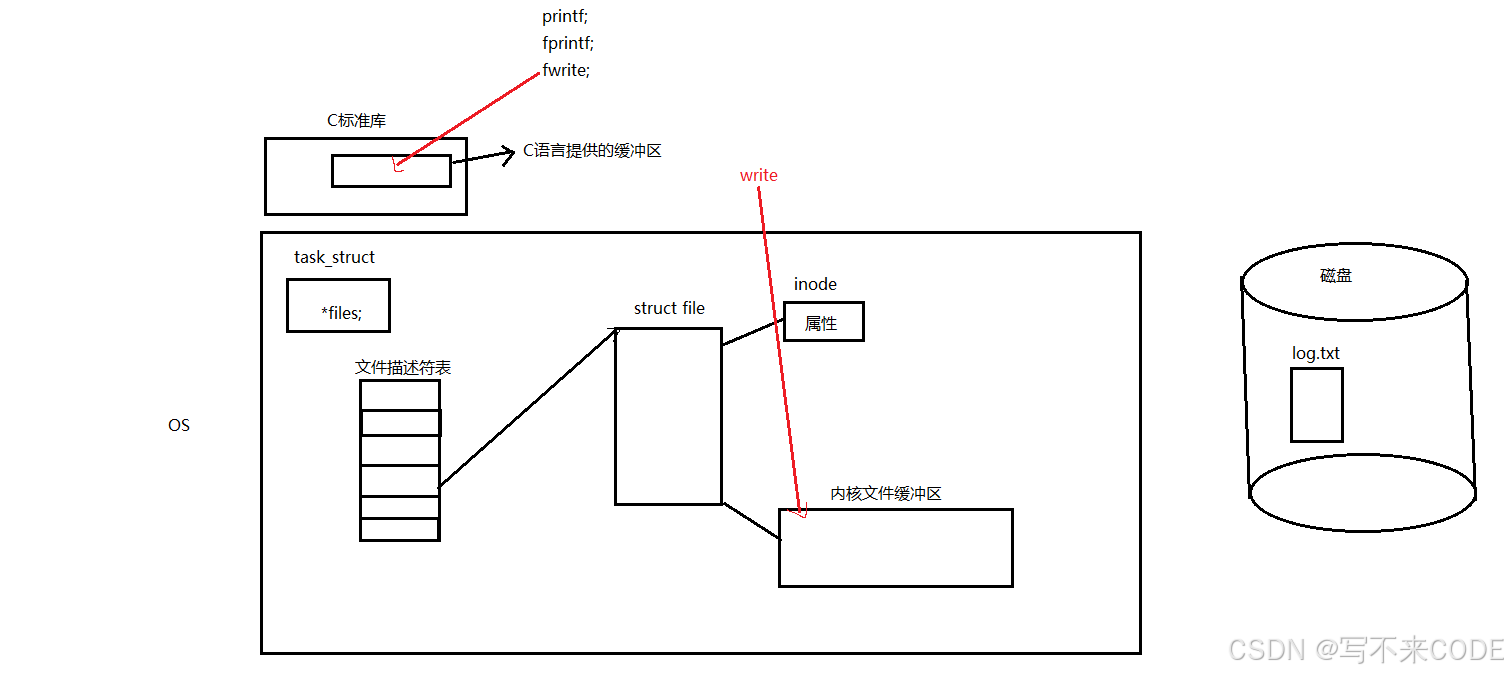
那我们要是想让库函数写的内容也写到文件中呢?
可以在文件关闭之前,强制刷新一下C语言库提供的,用户级,语言层缓冲区!!!
...
// 库函数
printf("hello printf\n");
printf("hello printf\n");
printf("hello printf\n");
fflush(stdout);// 系统调用
const char* msg = "hello write\n";
write(fd, msg, strlen(msg));close(fd);
...
当我们强制刷新缓冲区后,就会将缓冲区内的内容拷贝到内核文件缓冲区,其实这一步就是借助write系统调用实现的!
2.为什么要引入缓冲区机制呢?
引入缓冲区机制主要是为了提高效率!!!
因为系统调用是有消耗的!如果我们每一次使用库函数都将内容写道内核文件缓冲区,那么每一次都得使用系统调用,这样的消耗是很大的。但是当我们引入了文件缓冲区后,先将内容写到缓冲区中,当缓冲区满了/满足刷新条件/进程结束后,就会自动刷新缓冲区,刷新时才使用系统调用,这样就减少了使用系统调用的次数,提高了库函数的效率。
而如果没有内核文件缓冲区,操作系统直接将内容写到磁盘文件中,这就需要访问硬件,也是会产生消耗的。而我们设立了内核文件缓冲区,将内容先写到内核文件缓冲区中,当我们手动刷新/关闭文件时,操作系统就会将缓冲区中的内容刷新到磁盘文件中!!!这样也就减少了访问硬件的操作,提高了系统调用的效率。
所以,引入缓冲区机制主要是为了提高使用者的效率!!!
那么缓冲区到底是什么呢?
其实缓冲区就是一块内存空间。
3.缓冲区刷新机制
对于用户级,语言层缓冲区来说,刷新缓冲区有三种方式:
- 强制刷新——fflush
- 满足刷新条件
- 进程退出
0x01.强制刷新很好理解,那么进程退出为什么会刷新缓冲区呢?
注意:我们的程序是被编译器动过手脚的,他在没运行我们的程序之前就打开了stdin/out/err,那么,他在进程退出后,是不是还得关闭,那么他在关闭的时候,就会进行缓冲区的刷新。
0x02.满足刷新条件
既然满足刷新条件就可以刷新缓冲区,那么刷新条件都有哪些呢?
1、立即刷新——无缓冲——写透模式WT
这种方式就类似于直接使用系统调用,数据在写入缓存的同时,也会立即写入磁盘或其他持久性存储介质。这种策略确保了数据的一致性和可靠性,但可能会降低写操作的性能。
2、行刷新——行缓冲
这种方式一般用于显示器文件,当我们所写的内容含换行符时,此时就会立即刷新到内核文件缓冲区中!!!这种方式主要是为了方便用户查看打印消息
int main()
{printf("hello printf\n");printf("hello printf\n");printf("hello printf\n");const char* msg = "hello write\n";write(1, msg, strlen(msg));close(1);return 0;
}
说明:此时直接向stdout里面打印数据,printf会先将数据写入到用户级缓冲区,但因为这是想显示器写,所以默认是行刷新,且我们带了\n,所以这三条消息已经刷新到了内核文件缓冲区,所以即使我们关掉close(1)也能看到输出。 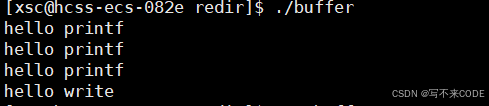
如果我们不带\n,此时就不会刷新,那么我们就也看不到了![]()
那么我们前面关闭了close(1)时写入也带了\n,为什么不显示呢?因为关闭了之后,我们打印的目标文件已经不是显示器文件了,而是普通文件,刷新方式改成了满刷新!!!
3、满刷新——全缓冲
当缓冲区满时,此时将缓冲区内容刷新到内核文件缓冲区中。该刷新策略一般适用于普通文件。采用这种刷新策略可以有效减少刷新次数,提高效率。
需要注意的是,我们上面说的都是用户级缓冲区的刷新策略,而内核文件缓冲区的刷新策略往往更加复杂,因为操作系统还得时刻关注内存使用情况,即使你采用的是满刷新,但是此时内存都不够用了,此时你也不得不刷新。
4.缓冲区在哪呢?
内核文件缓冲区在内核空间中,由操作系统直接管理。
那用户级缓冲区在哪?在FILE中。
为什么我们C语言打开文件会给我们返回一个FILE*的指针呢?FILE*到底是什么呢?
FILE其实是C语言提供的一个结构体,该结构体里除了封装文件描述符外,还有一个缓冲区:
struct FILE
{int fd;...// 缓冲区
};当我们用C语言打开一个文件时,底层就会给我们malloc出一个FILE结构体,当我们往文件写数据时,就会写到FILE的缓冲区中。
当然,我们知道fflush是刷新用户缓冲区,而它的参数就是FILE*,这也间接的说明了用户缓冲区就在FILE内部!!!
#include <stdio.h>int fflush(FILE *stream);
其实FILE是被typedef出来的,我们看一下源代码:
struct _IO_FILE {int _flags; /* High-order word is _IO_MAGIC; rest is flags. */#define _IO_file_flags _flags// 缓冲区/* The following pointers correspond to the C++ streambuf protocol. *//* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */char* _IO_read_ptr; /* Current read pointer */char* _IO_read_end; /* End of get area. */ char* _IO_read_base; /* Start of putback+get area. */ char* _IO_write_base; /* Start of put area. */ char* _IO_write_ptr; /* Current put pointer. */char* _IO_write_end; /* End of put area. */ char* _IO_buf_base; /* Start of reserve area. */char* _IO_buf_end; /* End of reserve area. *//* The following fields are used to support backing up and undo. */char *_IO_save_base; /* Pointer to start of non-current get area. */char *_IO_backup_base; /* Pointer to first valid character of backup area */char *_IO_save_end; /* Pointer to end of non-current get area. */struct _IO_marker *_markers;struct _IO_FILE *_chain;int _fileno; //文件描述符...
};struct _IO_FILE;__BEGIN_NAMESPACE_STD
/* The opaque type of streams. This is the definition used elsewhere. */
typedef struct _IO_FILE FILE; 5.缓冲区与fork
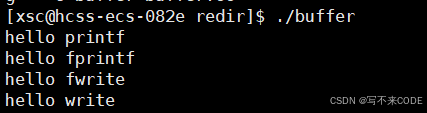
先看下面代码的执行结果
int main()
{// 库函数printf("hello printf\n");const char* s = "hello fprintf\n";fprintf(stdout, s, strlen(s));const char* ss = "hello fwrite\n";fwrite(ss, strlen(ss), 1, stdout);// 系统调用const char* msg = "hello write\n";write(1, msg, strlen(msg));fork();return 0;
}直接执行:
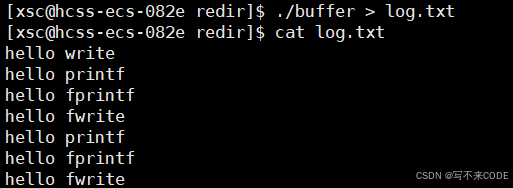
重定向:
为什么不同的方式,会产生不同的结果呢?
当我们直接指定代码时,此时库函数向显示器打印消息默认是行数新,且我们每一个字符串都带了\n,所以会直接刷新到内核文件缓冲区中,而write会直接拷贝到内核文件缓冲区中。此时fork创建子进程,没有任何执行,然后进程结束,刷新用户缓冲区,但是缓冲区中并没有任何内容,所以不会对结果产生影响!!!
而当我们使用重定向操作时,库函数此时向log.txt中打印内容,对普通文件来说,刷新方式就改成了满刷新。所以库函数的内容会先写到用户缓冲区中,write会直接写到内核文件缓冲区。此时fork床子进程,然后待进程结束后,父子进程都要刷新缓冲区,所以会刷新两份到文件缓冲区中,所以结果就是log.txt中,库函数的部分会有两次。
其实父子进程刷新缓冲区的过程也是修改操作,所以此时会进行写时拷贝,所以有一个进程刷新的其实是缓冲区内容的一份拷贝!!!
八.简单封装glibc库——实现文件操作库函数
// mystdio.h#include <stdio.h>#define MAX 1024
#define NONE_FFLUSH (1<<0)
#define LINE_FFLUSH (1<<1)
#define FULL_FFLUSH (1<<2)typedef struct __IO__FILE
{int fileno; // 文件描述符int flag; // 标志位??打开方式char buffer[MAX];int bufferLen;int fflush_mode;
}Myfile;Myfile* myFopen(const char* path, const char* mode);
void myFclose(Myfile* file);
int myFwrite(const void* ptr, size_t len, Myfile* file);
void myFflush(Myfile* file);// mystdio.c#include "mystdio.h"
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>Myfile* buyMyfile(int fd, int flag)
{Myfile* file = (Myfile*)malloc(sizeof(Myfile));if(file == NULL){return NULL;}file->fileno = fd;file->flag = flag;file->bufferLen = 0;memset(file->buffer, 0, sizeof(file->buffer));file->fflush_mode = LINE_FFLUSH;return file;
}Myfile* myFopen(const char* path, const char* mode)
{int fd = -1;int flag = 0;if(strcmp(mode, "w") == 0){flag = O_CREAT | O_WRONLY | O_TRUNC;fd = open(path, flag, 0666);}else if(strcmp(mode, "r") == 0){flag =O_RDONLY;fd = open(path, flag, 0666);}else if(strcmp(mode, "a") == 0){flag = O_CREAT | O_WRONLY | O_APPEND;fd = open(path, flag, 0666);}else {// todo}if(fd < 0) return NULL;return buyMyfile(fd, flag);
}
void myFclose(Myfile* file)
{myFflush(file);close(file->fileno);free(file);
}
int myFwrite(const void* ptr, size_t len, Myfile* file)
{// 拷贝到用户级缓冲区中memcpy(file->buffer + file->bufferLen, ptr, len);file->bufferLen += len;// 尝试判断是否满足刷新条件if(file->fflush_mode == LINE_FFLUSH && file->buffer[file->bufferLen - 1] == '\n'){myFflush(file);}return 0;
}
void myFflush(Myfile* file)
{if(file->bufferLen <= 0) return;write(file->fileno, file->buffer, file->bufferLen);fsync(file->fileno);file->bufferLen = 0;
}
上面便是简单的封装了一下系统调用以及用户级缓冲区。
我们下面来测试一下:
0x1.test1
#include "mystdio.h"
#include <string.h>
#include <unistd.h>int main()
{Myfile* file = myFopen("log.txt", "a");if(file == NULL){perror("myFopen error\n");return 1;}int cnt = 10;const char* msg = "hello myfile\n";while(cnt--){myFwrite(msg, strlen(msg), file);printf("buffer:%s\n", file->buffer);sleep(1);}myFclose(file);return 0;
}
说明:当我们向文件里面写的文本带\n时,而且我们默认的就是行刷新,所以消息会直接写到内核文件缓冲区中。而因为我们是追加写,所以log.txt中的内容应该越来越多。
我们用监控持续打印log.txt中的内容:
while :; do cat log.txt ;echo "--------------------------------------------------";sleep 1 ; done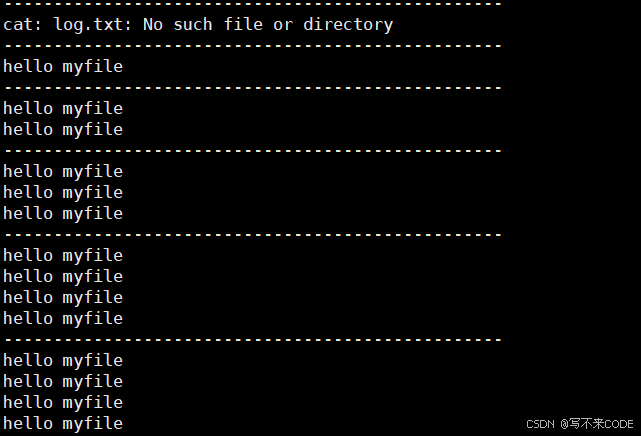
0x2.test2
const char* msg = "hello myfile";说明:这一次,我们向文件里面写的内容不带\n。所以,这些内容应该都写在了用户级缓冲区中,所以buffer会越来越长,但log.txt一直没有内容,直到关闭文件,刷新缓冲区!!!
0x3.test3
myFwrite(msg, strlen(msg), file);
myFflush(file);这次我们依旧不带\n,而在写之后,用myfflush强制刷新缓冲区。所以这次的结果应该和第一次一样,每写一次,log.txt里面就会有内容。log.txt内容会越来越多,而buffer一直都只有一条消息。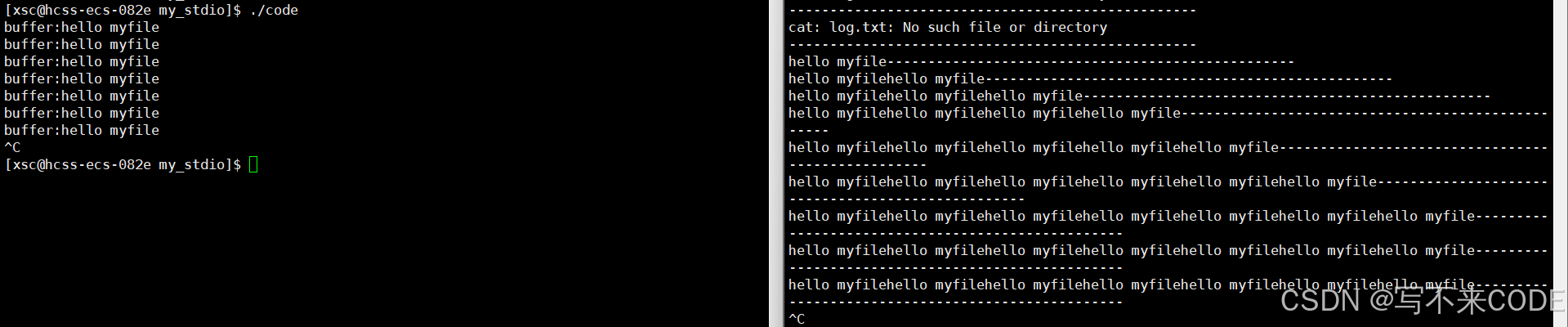
从上面的测试,我们可以得出结论,只要我们将数据交给了操作系统,就相当于交给了硬件。
并且,在计算机中,数据的流动本质上全都是拷贝!!!
我们上面都是以输出缓冲区为例的,其实还有输入缓冲区,即从内核文件缓冲区中读取数据时文件暂存的地方。
自此,Linux基础IO部分就结束了!

)
感知机)


